这篇文章将从零开始指导阅读者利用tensorflow搭建一个神经网络,若是有问题还请指出,或直接再评论区更正。若是对前面的内容不感兴趣可直接跳至神经网络处。
文章目录
一. 安装tensorflow
cmd命令
pip install tensorflow
很慢,这里建议换源
pip install tensorflow -i https://pypi.douban.com/simple/
之后大概率会出现**Cannot uninstall ‘wrapt’.**这样的报错。
这时候手动操作,输入命令
pip install wrapt --ignore-installed
应该就可以解决了。
之后检验
import numpy as np
import tensorflow.compat.v1 as tf
print(tf.__version__)
如果如下便正常。

二. tensorflow是什么
1. Hello TensorFlow!
这句话与我们初学编程时的"hello world!"相同,都是开始接触编程时所学的东西。在学习一门语言,一个框架的时候,首先,要对这门语言或者这门框架有一些基本的认识,我们来谈谈tensorflow到底是个什么。
TensorFlo是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief,现在我们就可以直接把它看为一个机器学习的算法库。
名为tensorflow有其自己的寓意,tensor是张量的意思,flow是流动的意思,仅就字面意思而言,tensorflow的意思是让张量流动起来,我们不妨拓展一下,将其看为,让数据流动起来。让数据一端流动到另一端。其实就是将复杂的数据传输到人工智能神经网络中进行处理的一个系统。
2. 张量
张量是矢量的推广,矢量是一阶张量,矩阵是二阶张量而三阶的张量好比立体的矩阵。
张量是一个表示矢量,标量,和其他张量之间的线性关系的多线性函数。可以看做是tensorflow中的某种基本数据类型。
3. tensorflow的基本概念
①. 算子
在tensorflow中集成了很多现成的,已经实现的机器学习经典算法,这些算法被称为算子(Operation),每个算子在定义时就被定下了规则,方法,数据类型以及相应的输出结果。
②. 节点
某个输入数据在算子中的具体运行和实现。
③. 边
边分为正常边,和特殊边
- 正常边:数据流动的通道。
- 特殊边: 又被称为“控制依赖”,其作用就是控制节点之间相互依赖,使数据的流动遵循一定的顺序。或者可以实现多线程运行数据的执行。
④. 会话
会话是tensorflow的主要交互方式,tensorflow的一般流程为:
- 建立会话
- 生成一张空图
- 添加各个节点和边
- 形成一个有连接的图
- 启动图对模型进行循环。
三. 从代码开始接触,由浅入深
1. 数据类型与逻辑运算
首先,我们运行一段代码
import numpy as np
import tensorflow.compat.v1 as tf
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
#创建 会话控制
sess=tf.Session()
a=tf.constant(1)
b=tf.constant(2)
#利用会话控制调用
print(sess.run(tf.add(a,b)))
结果为
- 开头的导库以及必须要的那段语句目前大家记住便可。之后会解释。
- 首先创建一个对话。
- 定义了两个量。
constant:这是常量的意思。我们知道编程语言中存在常量变量。常量一般是不可变的。比如重力加速度,地球的第一宇宙速度,都属于常量。
tf.add()相加,它是对我们输入的两个tensor进行相加的,而我们调用它,将它输出出来则需要用到会话控制。
tensorflow本身是包含各种数据类型的,不论是int32,float64,等等,在python中可以看到的,几乎在tensorflow都能看到。
import numpy as np
import tensorflow.compat.v1 as tf
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
sess=tf.Session()
hello=tf.constant('hello tensorflow!',dtype=tf.string)
print(sess.run(hello))
如上就是一个tf的字符串。接下来我们来看会话控制的一个重要功能。
import tensorflow.compat.v1 as tf
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
#创建会话控制中心
sess=tf.Session()
#创建常量
input_1=tf.constant(1)
print(input_1)
#创建变量
input_2=tf.Variable(2)
print(input_2)
input_2=input_1
print(sess.run(input_2))
结果如下:

input1显示是没有什么问题的,一个张量。但是input在没有执行会话之前,明明被赋值了,却没有数据,这说明只有在执行会话之后,input2变量才会发生真实值的变化。

如上为tensorflow几种常用的数据类型。
2. 矩阵
tensorflow由于其自身的结构,它也具有其自己矩阵的运算方法。
import numpy as np
import tensorflow.compat.v1 as tf
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
sess=tf.Session()
#创建一个矩阵张量
a=tf.constant([1,2,3],shape=[2,3])
print(sess.run(a))
结果如下:
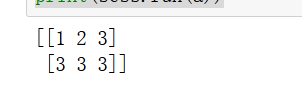
第一行是我们设置的,而第二行则是从第一行随机选取数据填充。创建矩阵的模式很多。如果要随机创建矩阵的话,可以用如下的方法
b=tf.random_normal((2,3))
c=tf.truncated_normal((2,3))
d=tf.random_uniform((2,3))
具体的参数,这里不需要细讲,需要的时候会展开说。
tf.shape()方法可以得到矩阵得大小信息。
矩阵的运算方法大致如下

3. 占位符
占位符是在tensorflow中的一种特殊的数据类型,没错它也是数据类型,只是很特殊,看代码:
'''
占位符
'''
import tensorflow.compat.v1 as tf
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
#创建会话控制中心
sess=tf.Session()
a=tf.placeholder(tf.int32)
b=tf.placeholder(tf.int32)
output=tf.add(a,b)
#feed_dict对象将tensor对象映射为numpy数组
print(sess.run(output,feed_dict={
a:[1],b:[2]}))
通过
a=tf.placeholder(dtype)
的方式定义一个某种类型的占位符。之后可以通过feed_dict函数传参进去,这个方法类似于什么呢。
a,b=1,2
print('test:{0},{1}'.format(a,b))
可以认为类似于python中的format方法。
这里主要Feeding_dict()函数,Feeding是tensorflow的一种机制,它允许你在运行时使用不同的值替换一个或者多个tensor的值,feed_dict就是将tensor对象,映射为Numpy的数组和一些其他类型,同时在执行step时,这些数组就是tensor的值。
4. 常用方法
如下为tensorflow中的常用方法:

(这里不拍照的话实在是太麻烦了,还没效率。。)
四. 手把手着手搭建一个神经网络
1. 网络的结构
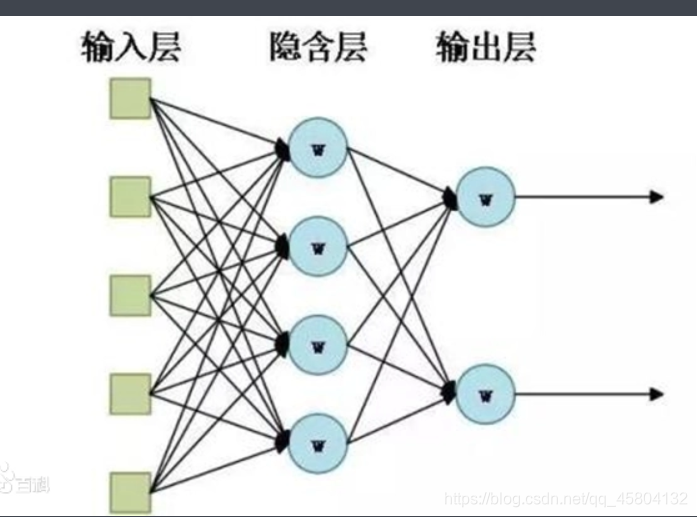
网络的结构,这张图展示的很清楚,我们需要做输入数据,将数据输入之后,通过各个隐藏层的计算,最后输出出来,而我们需要的结果,也就是说我们要训练模型其实要得到的
f(x)=wx+b
的这样一个w和b。
2. 引入数据
既然看到了神经网络,那么说明小伙伴的机器学习基础起码是有的,那么这便是常识了,训练模型,自然是需要训练集的,这里我们用随机数生成。
#创建一个大量的输入数据
input_X=np.random.rand(3000,1)
#创建噪声曲线
nosie=np.random.normal(0,0.05,input_X.shape)
#创建一个线性曲线
output_y=input_X*4+1+nosie
3. 创建一个有隐藏层的反馈神经网络来计算这个曲线
'''
创建一个有隐藏层的反馈神经网络来计算这个线性曲线
'''
#这里是第一层
'''
weight 与 bias_1为神经网络隐藏层的变量,后续会随着误差算法不断的更迭。
'''
weight_1=tf.Variable(np.random.rand(input_X.shape[1],4))
bias_1=tf.Variable(np.random.rand(input_X.shape[1],4))
#x1为占位符,期间要不断输入数据,而y1为最终需要的目标。
x1=tf.placeholder(tf.float64,[None,1])
#y1最终的目标是一个线性模型。
y1=tf.matmul(x1,weight_1)+bias_1
4. 损失函数与模型训练
y=tf.placeholder(tf.float64,[None,1])
loss=tf.reduce_mean(tf.reduce_sum(tf.square((y1-y)),reduction_indices=[1]))
'''
train采用梯度下降法算法计算。
'''
train=tf.train.GradientDescentOptimizer(0.25).minimize(loss)
'''
init启动数值的初始化
'''
init=tf.global_variables_initializer()
'''
启动会话
'''
sess.run(init)
for i in range(1000):
sess.run(train,feed_dict={
x1:input_X,y:output_y})
loss为定义的损失函数,这里采用最小二乘损失法,即计算模型真实值与输出值之间的最小二乘法。
minimize方法,大致包含两个过程,计算各个变量的梯度,以及用梯度去更新各个变量的值,其参数就是我们定义的损失,无可厚非。
其余的注解都在代码之中了。
5. 第一个网络完整代码
完整代码
'''
设计一个简单的神经网络
'''
import tensorflow.compat.v1 as tf
import numpy as np
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
#创建会话控制
sess=tf.Session()
#创建一个大量的输入数据
input_X=np.random.rand(3000,1)
#创建噪声曲线
nosie=np.random.normal(0,0.05,input_X.shape)
#创建一个线性曲线
output_y=input_X*4+1+nosie
'''
创建一个有隐藏层的反馈神经网络来计算这个线性曲线
'''
#这里是第一层
'''
weight 与 bias_1为神经网络隐藏层的变量,后续会随着误差算法不断的更迭。
'''
weight_1=tf.Variable(np.random.rand(input_X.shape[1],4))
bias_1=tf.Variable(np.random.rand(input_X.shape[1],4))
#x1为占位符,期间要不断输入数据,而y1为最终需要的目标。
x1=tf.placeholder(tf.float64,[None,1])
#y1最终的目标是一个线性模型。
y1=tf.matmul(x1,weight_1)+bias_1
y=tf.placeholder(tf.float64,[None,1])
loss=tf.reduce_mean(tf.reduce_sum(tf.square((y1-y)),reduction_indices=[1]))
'''
train采用梯度下降法算法计算。
'''
train=tf.train.GradientDescentOptimizer(0.25).minimize(loss)
'''
init启动数值的初始化
'''
init=tf.global_variables_initializer()
'''
启动会话
'''
sess.run(init)
for i in range(1000):
sess.run(train,feed_dict={
x1:input_X,y:output_y})
'''
训练完成后,打印出参数。
'''
print('weight:',weight_1.eval(sess))
print('bias_l:',bias_1.eval(sess))
x_data=np.matrix([[1.],[2.],[3.]])
print(sess.run(y1,feed_dict={
x1:x_data}))
ok,我们来看看结果。

其实我们最终要求的就是w和b这俩个参数罢了,这就是很简单的网络,
6. 构建第二层网络
第二层的设置与第一层类似,但是这时候要注意了,第二层的输入一定会是第一层的结果,这样才实现了一层一层数据的传递。如下图
代码:
'''
设计一个简单的神经网络
'''
import tensorflow.compat.v1 as tf
import numpy as np
#导入tensorflow2 需要用到该语句,否则会报错。
tf.compat.v1.disable_eager_execution()
#创建会话控制
sess=tf.Session()
#创建一个大量的输入数据
input_X=np.random.rand(3000,1)
#创建噪声曲线
nosie=np.random.normal(0,0.05,input_X.shape)
#创建一个线性曲线
output_y=input_X*4+1+nosie
'''
创建一个有隐藏层的反馈神经网络来计算这个线性曲线
'''
#这里是第一层
'''
weight 与 bias_1为神经网络隐藏层的变量,后续会随着误差算法不断的更迭。
'''
weight_1=tf.Variable(np.random.rand(input_X.shape[1],4))
bias_1=tf.Variable(np.random.rand(input_X.shape[1],4))
#x1为占位符,期间要不断输入数据,而y1为最终需要的目标。
x1=tf.placeholder(tf.float64,[None,1])
#y1最终的目标是一个线性模型。
y1=tf.matmul(x1,weight_1)+bias_1
'''
创建第二层
'''
weight_2=tf.Variable(np.random.rand(4,1))
bias_2=tf.Variable(np.random.rand(input_X.shape[1],1))
y2=tf.matmul(y1,weight_2)+bias_2
'''
这里的y是一个占位符,loss为定义的损失函数,这里用最小二乘法计算损失。
'''
y=tf.placeholder(tf.float64,[None,1])
loss=tf.reduce_mean(tf.reduce_sum(tf.square((y2-y)),reduction_indices=[1]))
'''
train采用梯度下降法算法计算。
'''
train=tf.train.GradientDescentOptimizer(0.25).minimize(loss)
'''
init启动数值的初始化
'''
init=tf.global_variables_initializer()
'''
启动会话
'''
sess.run(init)
for i in range(1000):
sess.run(train,feed_dict={
x1:input_X,y:output_y})
'''
训练完成后,打印出参数。
'''
print('weight:',weight_1.eval(sess))
print('bias_l:',bias_1.eval(sess))
x_data=np.matrix([[1.],[2.],[3.]])
print(sess.run(y1,feed_dict={
x1:x_data}))
五. 为什么名为反馈神经网络
为什么叫它反馈神经网络。在网络的一次一次循环运行中,每一次得到的结果,其实tensorflow都会判断它是否到达了期望的值,或者是否到达了迭代的设置次数极限,若是没有达到则会进行一个逆过程,进行参数的修正,而这个参数的修正就是依靠了一个反馈的过程。