文章目录
什么是TensorFlow
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。2015年它由Google发布并宣布开源。它的名字来源于本身的工作原理,Tensor(张量)意味着一个N维的数组,Flow(流)就是流动。Tensorflow的运行过程就是张量在数据流图中流动的过程。
选择 TensorFlow 的原因
TensorFlow 是一个端到端开源机器学习平台。它拥有一个包含各种工具、库和社区资源的全面灵活生态系统,可以让研究人员推动机器学习领域的先进技术的发展,并让开发者轻松地构建和部署由机器学习提供支持的应用
TensorFlow核心概念
- 图(Graph):图描述了计算的过程,TensorFlow使用图来表示计算任务。
- 张量(Tensor):TensorFlow使用tensor表示数据。每个Tensor就是一个多维的数组。
- 操作(op):operation的缩写,一个op就是某节点上的一个操作,输入0个或多个Tensor,执行计算,产生输出0个或多个Tensor。
- 会话(Session):图必须在称之为“会话”的上下文中执行。会话将图的op分发到诸如CPU或GPU之类的设备上执行。
- 变量(Variable):运行过程中可以被改变,用于维护状态。
TensorFlow学习导图

TensorFlow实例一
打印helloworld程序
# 引入tensorflow库
try:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except:
import tensorflow as tf
# 创建一个操作(常量)
a = tf.constant('Hello world!')
# 启动会话(Session)
sess = tf.Session()
# 运行Graph
print(sess.run(a))
# 关闭会话
sess.close()

TensorFlow实例二
session的使用
# 引入tensorflow库
try:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except:
import tensorflow as tf
#第一阶段: 构建图
#定义一个1x2的矩阵,矩阵元素为[3 3]
matrix1 = tf.constant([[3., 3.]])
#定义一个2x1的矩阵,矩阵元素为[22]
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
product = tf.matmul(matrix1, matrix2)
#第二阶段: 执行图
with tf.Session() as sess:
print ("matrix1: %s" % sess.run(matrix1))
print ("matrix2: %s" % sess.run(matrix2))
print ("result type: %s" % type(sess.run(product)))
print ("result: %s" % sess.run(product))

TensorFlow实例三
Variable的使用
try:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except:
import tensorflow as tf
state = tf.Variable(0, name='counter') # 定义变量state,并赋值0,名字counter
# print(state.name)
one = tf.constant(1) # 定义常量one,赋值1
new_value = tf.add(state, one) # 变量 + 常量 = 变量
# 将state用new_value代替
updata = tf.assign(state, new_value) # 把new_value加1的值赋值给state
# 变量激活
init = tf.global_variables_initializer() # 初始化所有的变量,必须用会话run才可以激活 (有定义变量时,这步骤是必须的)
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(updata)
print(sess.run(state))

TensorFlow实例四
占位符(Placeholder)使用
try:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except:
import tensorflow as tf
# 定义placeholder
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
# 定义乘法运算
output = tf.multiply(input1, input2)
input_dict = {
input1 : 7.0,input2 : 10.0}
# 通过session执行乘法运行
with tf.Session() as sess:
# 执行时要传入placeholder的值
# print(sess.run(output, feed_dict = {
input1:[7.], input2: [2.]}))
print(sess.run(output, feed_dict= input_dict ))
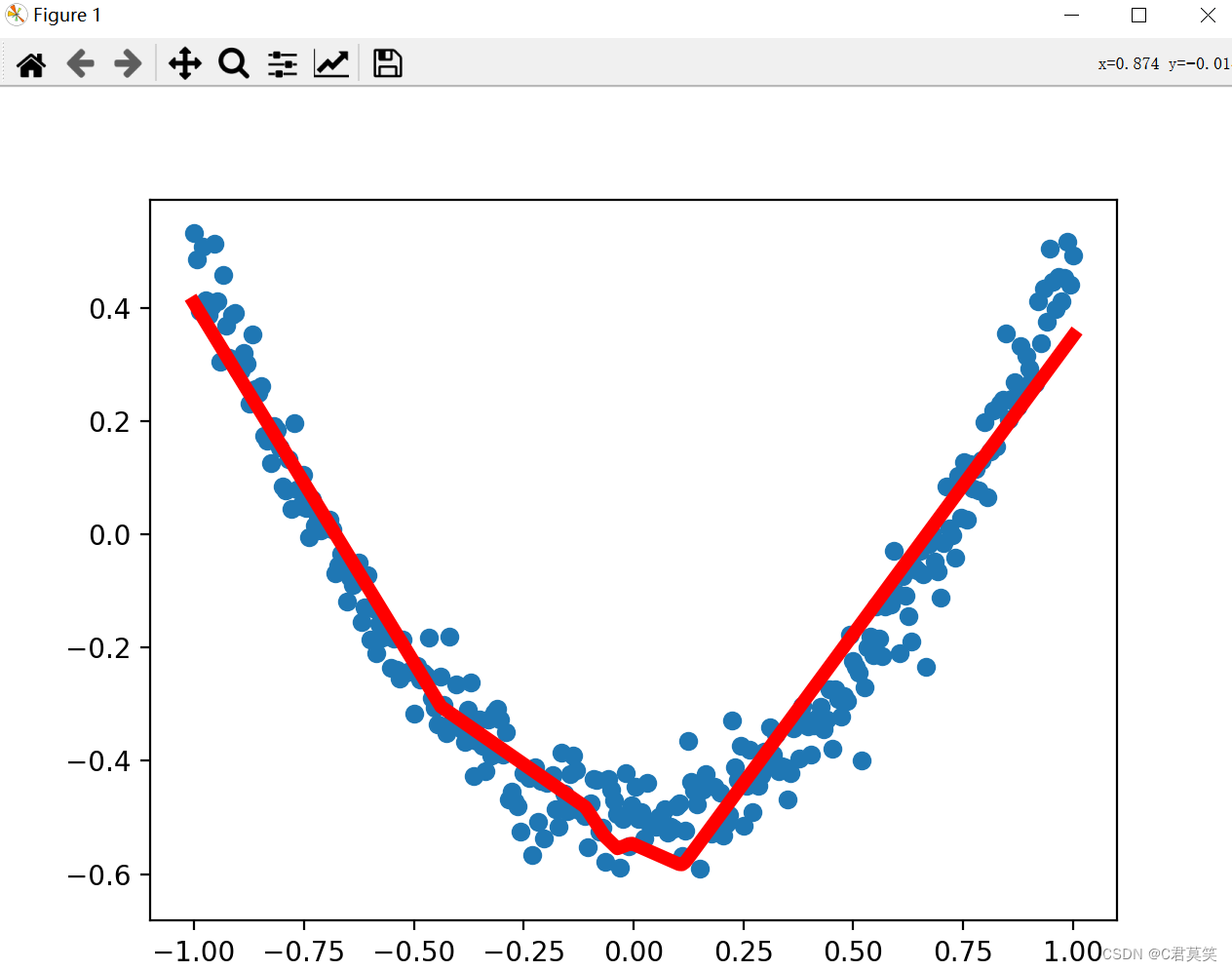
TensorFlow实例五
基于Tensorflow搭建一个神经网络的实现
try:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size])) # 正态分布
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) # 1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases # Weights*x+b的初始化值,也是未激活的值
# 激活
if activation_function is None:
# 如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
# 创建一列(相当于只有一个属性值),(-1,1)之间,有300个单位,后面是维度,x_data是有300行
x_data = np.linspace(-1, 1, 300)[:, np.newaxis] # np.linspace在指定间隔内返回均匀间隔数字
# 加入噪声,均值为0,方差为0.05,形状和x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
# 定义y的函数为二次曲线函数,同时增加一些噪声数据
y_data = np.square(x_data) - 0.5 + noise
# 定义输入值,输入结构的输入行数不固定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
"""建立网络"""
# 定义隐藏层,输入为xs,输入size为1列,因为x_data只有一个属性值,输出size假定有10个神经元的隐藏层,激活函数relu
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# 定义输出层,输出为l1输入size为10列,也就是l1的列数,输出size为1,这里的输出类似y_data,因此为1列
prediction = add_layer(l1, 10, 1, activation_function=None)
"""预测"""
# 定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1]))
"""训练"""
# 进行逐步优化的梯度下降优化器,学习率为0.1,以最小化损失函数进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化模型所有参数
init = tf.global_variables_initializer()
# 可视化
with tf.Session() as sess:
sess.run(init)
fig = plt.figure() # 先生成一个图片框
# 连续性画图
ax = fig.add_subplot(1, 1, 1) # 编号为1,1,1
ax.scatter(x_data, y_data) # 画散点图
# 不暂停
plt.ion() # 打开互交模式
# plt.show()
# plt.show绘制一次就暂停了
for i in range(1000): # 学习1000次
sess.run(train_step, feed_dict={
xs: x_data, ys: y_data})
if i % 50 == 0:
try:
# 画出一条后,抹除掉,去除第一个线段,但是只有一个相当于抹除当前线段
ax.lines.remove(lines[0])
except Exception:
pass
prediction_value = sess.run(prediction, feed_dict={
xs: x_data})
lines = ax.plot(x_data, prediction_value, 'r-', lw=5) # lw线宽
# 暂停
plt.pause(0.5)