reference:https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/3-2-create-NN/
这篇文章主要讲怎样建造一个完整的神经网络,包括添加神经层,计算误差,训练步骤
定义一个添加层神经层函数
我们知道一个神经网络可能包含很多个隐藏层,所以如果我们定义一个添加层函数,在后面如果需要增加神经层就只需要调用我们定义的添加层函数就可以了。神经层里常见的参数通常有:weights,biases和激励函数
首先导入tensorflow模块和numpy,然后定义添加神经层函数def add_layer(),这里有四个参数,输入值,输入值的大小,输出值的大小,激励函数,这里可以设定激励函数默认为None。
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):接下来我们开始定义weights和biases,这两个都需要我们生成初始参数,而后经过训练来调整参数。这里的weights定义为一个in_size行,out_size列的随机变量(normal distribution)矩阵。
Weights = tf.Variable(tf.random_uniform([in_size, out_size]))在机器学习中,biases的推荐值不为0,所以我们在0向量的基础上加0.1
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)接下来我们定义神经网络未激活的值,定义为Wx_plus_b
Wx_plus_b = tf.matmul(input, Weights) + biases当激励函数为默认值None时,此时为liner function,所以直接输出Wx_plus_b。当激励函数存在时,需要将Wx_plus_b传入的激励函数中然后输出并且返回输出结果。
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs这样我们的添加层函数就定义好了。
要对神经网络进行训练就一定要有输入的数据集,现在我们来定义输入数据,这里一个值域为-1到+1期间的300个数据,为300*1的形式,
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]然后定义一个与x_data形式一样的噪音点,使得我们进行训练的数据更像是真实的数据
noise = np.random.normal(0, 0.05, x_data.shape)定义y_data,假设为x_data的平方减去噪音点
noise = np.random.normal(0, 0.05, x_data.shape)定义placeholder, 参数中none表示输入多少个样本都可以,x_data的属性为1,所以输出也为1
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])我们定义一个最简单的神经网络,一个输入层,一个隐藏层和一个输出层,隐藏层
我们假设只给10个神经元,输入层是有多少个属性就有多少个神经元,我们的x_data只有一个属性,所以只有一个神经元,输出层与输入层是一样的,输入层有多少个神经元输出层就有多少个。这里激励函数用的是卷积神经网络中最常用的relu。
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)输出层接受到的data是l1输出的,inputsize为隐藏层的size,输出层的size是1
prediction = add_layer(l1, 10, 1, activation_function=None)计算预测值与真实值的差异。
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))接下来就可以训练我们的数据了,使神经网络从我们的样本点通过误差来学习。这里的优化函数使用GD去减小误差,学习率假设为0.1,通常学习率都为小于1的数
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)对所有的变量初始化
init = tf.global_variables_initializer()定义session
sess = tf.Session()
sess.run(init)最后让我们的神经网络训练1000次,每隔50次打印出来loss
for i in range(1000):
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
if i % 50 == 0:
print(sess.run(loss, feed_dict={xs: x_data, ys:y_data}))这样一个简单的神经网络就完成了。
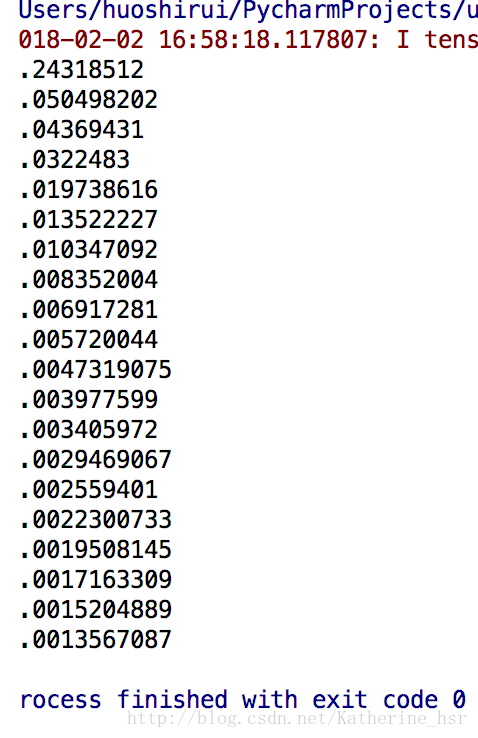
这里是我们的运行结果,从结果中可以看出开始loss很大,经过训练loss逐渐减小,到最后loss只有0.0013567087已经很接近真实值了。