
今天我们用Tensorflow构建图1所示的神经网络结构。
神经网络结构说明:
(1)输入层:300个含有一个特征的样本。
(2)隐藏层:含有一个隐藏层,隐藏层中有10个神经元节点。神经元节点的激活函数是:ReLU。
(3)输出层:一个神经元节点,没有激活函数。
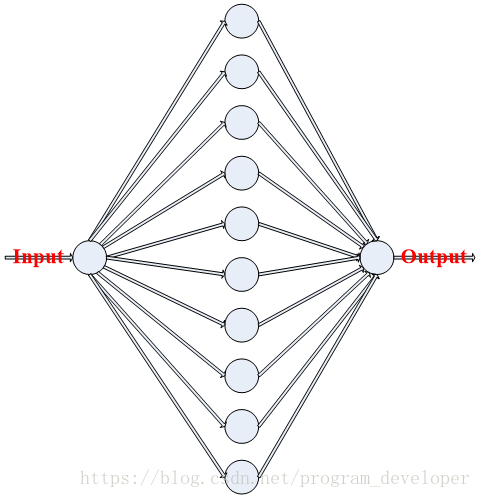
图1:神经网络
实现代码如下:
#coding:utf-8
# 导入本次需要的模块
import tensorflow as tf
import numpy as np
'''
inputs:输入值
in_size:输入的大小
out_size:输出的大小
activation_function:激活函数
'''
# 构造添加一个神经层的函数
def add_layer(inputs,in_size,out_size,activation_function=None):
# 定义weights为一个in_size行,out_size列的随机变量矩阵
Weights = tf.Variable(tf.random_normal([in_size,out_size]))
biases = tf.Variable(tf.zeros([1,out_size])) + 0.1
Wx_plus_b = tf.matmul(inputs,Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
#################导入数据##################################
# 构建所需要的数据。这里的x_data和y_data并不是严格的一元二次函数的关系,
# 因为我们多加了一个noise,这样看起来会更像真实情况。
x_data = np.linspace(-1,1,300)[:,np.newaxis]
noise = np.random.normal(0,0.05,x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# 利用占位符定义我们所需要的神经网络的输入。
# None代表无论输入有多少样本都可以。因为输入只有一个特征,所以这里是1。
xs = tf.placeholder(tf.float32,[None,1])
ys = tf.placeholder(tf.float32,[None,1])
#################导入数据##################################
#################搭建神经网络##################################
# 输入层只有一个属性,所以我们就只有一个输入。
# 我设置隐藏层有10个神经元
# 输出层也只有一层
l1 = add_layer(xs,1,10,activation_function=tf.nn.relu)
prediction = add_layer(l1,10,1,activation_function=None)
# 定义损失函数
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),reduction_indices=[1]))
# 让神经网络通过梯度下降法来训练,这里的0.1是学习率
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 使用变量时,都要对变量进行初始化
init = tf.initialize_all_variables()
# 定义Session,并用Session来执行init初始化步骤
sess = tf.Session()
sess.run(init)
#################搭建神经网络##################################
#################训练网络##################################
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%50 == 0:
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
#################训练网络##################################
总共训练1000次,每隔50次打印出损失函数值。
Instructions for updating: Use `tf.global_variables_initializer` instead. 0.073003575 0.010389006 0.00867055 0.0069280714 0.005706204 0.005057978 0.0047096335 0.0045111366 0.0043739015 0.0042599924 0.004163221 0.0040789503 0.004002313 0.0039392975 0.0038817858 0.003832464 0.0037836325 0.0037361784 0.0036902388 0.0036492061
最后,我们把梯度下降优化神经网络的过程进行可视化显示,结果如图2所示。
这里我制作了一个gif动态图片,可以直观的感受梯度下降优化神经网络过程,可是CSDN博客显示不了,请前往我的知乎专栏观看图片。地址:https://zhuanlan.zhihu.com/p/36416291
从图2中我们可以清楚的看到,因为初始的参数得出的预测值和真实值相差比较大,程序初始化的参数画出的拟合线条和原始数据相差比较大,这也是为什么前几次梯度下降时,我们得到的损失函数值比较大。但是,随着梯度下降的不断优化,得到的参数越来越拟合我们的数据,真实值和预测值之间误差越来越小,得到的损失函数值也越来越小。
给出完整的代码:
#coding:utf-8
# 导入本次需要的模块
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
'''
inputs:输入值
in_size:输入的大小
out_size:输出的大小
activation_function:激活函数
'''
# 构造添加一个神经层的函数
def add_layer(inputs,in_size,out_size,activation_function=None):
# 定义weights为一个in_size行,out_size列的随机变量矩阵
Weights = tf.Variable(tf.random_normal([in_size,out_size]))
biases = tf.Variable(tf.zeros([1,out_size])) + 0.1
Wx_plus_b = tf.matmul(inputs,Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
#################导入数据##################################
# 构建所需要的数据。这里的x_data和y_data并不是严格的一元二次函数的关系,
# 因为我们多加了一个noise,这样看起来会更像真实情况。
x_data = np.linspace(-1,1,300)[:,np.newaxis]
noise = np.random.normal(0,0.05,x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# 利用占位符定义我们所需要的神经网络的输入。
# None代表无论输入有多少样本都可以。因为输入只有一个特征,所以这里是1。
xs = tf.placeholder(tf.float32,[None,1])
ys = tf.placeholder(tf.float32,[None,1])
#################导入数据##################################
#################搭建神经网络##################################
# 输入层只有一个属性,所以我们就只有一个输入。
# 我设置隐藏层有10个神经元
# 输出层也只有一层
l1 = add_layer(xs,1,10,activation_function=tf.nn.relu)
prediction = add_layer(l1,10,1,activation_function=None)
# 定义损失函数
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),reduction_indices=[1]))
# 让神经网络通过梯度下降法来训练,这里的0.1是学习率
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 使用变量时,都要对变量进行初始化
init = tf.initialize_all_variables()
# 定义Session,并用Session来执行init初始化步骤
sess = tf.Session()
sess.run(init)
#################搭建神经网络##################################
#################训练网络##################################
# plot the real data
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(x_data,y_data)
plt.ion()
plt.show()
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%50 == 0:
# 每隔50次训练刷新一次图形,用红色、宽度为5的线来显示我们的预测数据和输入之间的关系,并暂停0.1s。
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
try:
ax.lines.remove(lines[0])
except Exception:
pass
prediction_value = sess.run(prediction,feed_dict={xs:x_data})
lines = ax.plot(x_data,prediction_value,"r-",lw=5)
plt.pause(0.1)
#################训练网络##################################