论文题目:Multi-View 3D Object Detection Network for Autonomous Driving
论文地址:https://arxiv.org/abs/1611.07759
开源代码代码:https://github.com/leeyevi/MV3D_TF
算法整体思路
这个算法主要思路是利用点云与摄像头进行融合感知,点云是进行了一个鸟瞰图和正视图的投影,再利用图像方面的知识进行检测3D目标。多视图的融合后再进行多传感器的融合。最终实现对道路场景中的物体进行高精度的三维定位和识别。
三维物体检测是自动驾驶汽车视觉感知系统的重要组成部分。现代自动驾驶汽车通常配备多传感器,如激光雷达和摄像头。激光扫描仪具有精确的深度信息的优势,而相机则保留更详细的语义信息。激光雷达点云与RGB图像的融合应该能够实现对自动驾驶汽车更高的性能和安全性。
在本文中,我们提出了一种多视图三维物体检测网络(MV3D),该网络以多模态数据为输入,预测三维空间中物体的完整三维方位。利用多模态信息的主要思想是进行基于区域的特征融合。我们首先提出了一种多视图编码方案,以获得一种紧凑而有效的稀疏三维点云表示。如图1所示,MV3D网络由两部分组成:3D目标库预测网络和基于区域的融合网络。
3D目标库预测网络利用点云的鸟瞰图表示来生成高精度的3D候选框。3D对象预测的好处是它可以投射到3D空间中的任何视图。多视图融合网络通过将多个视图的三维建议投射到特征图中来提取区域特征。我们设计了一种深度融合的方法,使中间层能够从不同的视图进行交互。结合下降路径训练和辅助损失,我们的方法显示出比早期/最近的融合方案更好的性能。在多视图特征表示的情况下,该网络进行有方向的三维目标框回归,准确预测三维空间中物体的三维位置、大小和方向
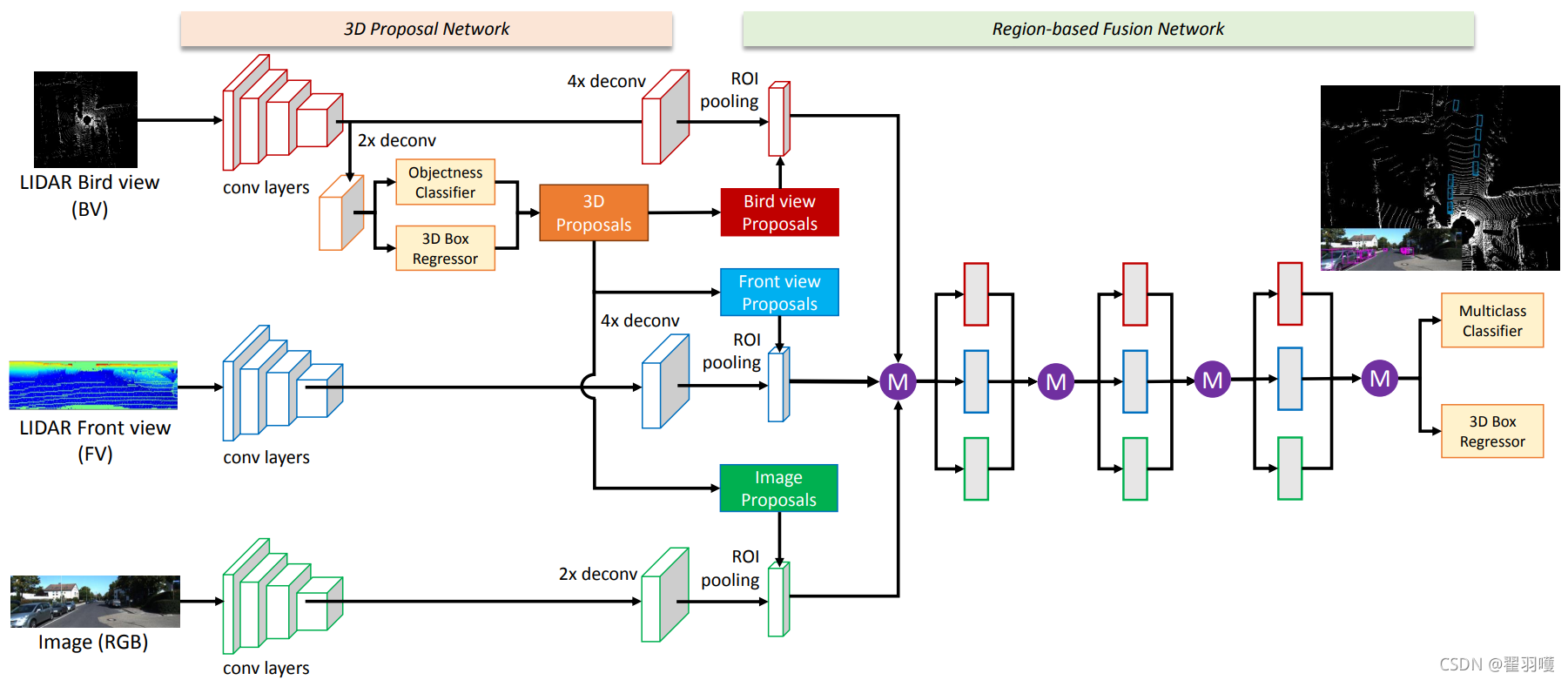 多视图3D物体检测网络(MV3D):该网络以激光雷达点云的鸟瞰图和前视图以及图像作为输入。它首先从鸟瞰图生成3D目标候选框,并将它们投影到三个视图。深度融合网络用于对每个视图进行区域特征的融合。融合后的特征用于联合预测对象类别,并进行3d目标框的检测与回归。
多视图3D物体检测网络(MV3D):该网络以激光雷达点云的鸟瞰图和前视图以及图像作为输入。它首先从鸟瞰图生成3D目标候选框,并将它们投影到三个视图。深度融合网络用于对每个视图进行区域特征的融合。融合后的特征用于联合预测对象类别,并进行3d目标框的检测与回归。
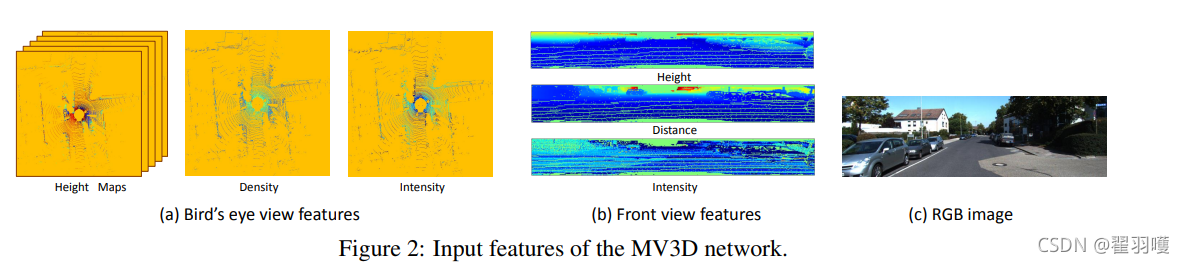
鸟瞰图
鸟瞰图的表示是由高度、强度和密度编码的。我们将投影点云离散化为分辨率为0.1m的2D网格。对于每个单元,高度特征计算为单元中点的最大高度。为了对更详细的高度信息进行编码,将点云平均分为M个切片。为每个切片计算一个高度图,因此我们获得M个高度图。强度特征是每个单元中具有最大高度的点的反射率值。点云密度表示每个单元中点的数量。
为了规范化特征,将其计算为:
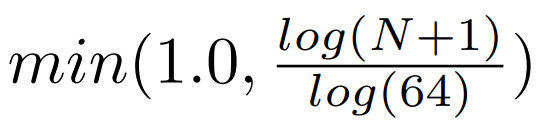
其中N是单元中的点数。
前视图
前视图表示为鸟瞰视图表示提供补充信息。由于LIDAR点云非常稀疏,因此将其投影到图像平面中会生成稀疏的2D点图。相反,我们将它投影到一个柱面来生成一个密集的前视图映射。
给定3D点p =(x,y,z),可以使用以下公式计算其在前视图中的坐标Pfv=(r,c)
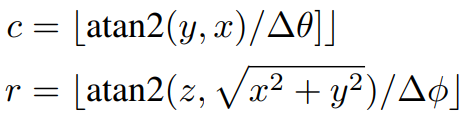
其中∆θ和∆φ分别是激光束的水平和垂直分辨率。我们使用三通道特征(高度,距离和强度)对前视图地图进行编码,如图2所示。
代码阅读
参考文章:
https://zhuanlan.zhihu.com/p/86312623
https://www.pianshen.com/article/96221256621/