1 模型结构
这是来自ACL2016的论文,它修改基本的端到端结构,使其可以更好的存储QA所需的先验知识。其结构如图所示。从上图可以看出key embedding和value embedding两个模块跟端到端记忆网络里面的Input memory和Output memory两个模块是相同的,不过这里记忆是使用key和value来表示。而且每个hop之间有R矩阵对输入进行线性映射。此外,求每个问题时会进行一个key hashing的预处理,从知识源里选择出与之相关的记忆,然后再进行模型的训练。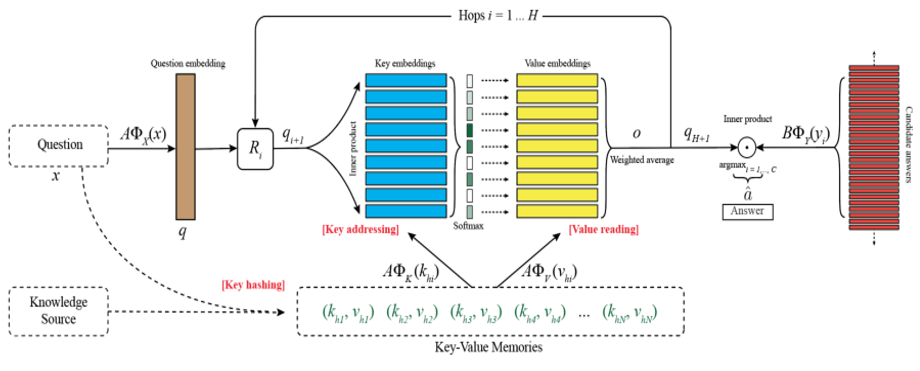
这个模型看起来有点复杂,于是我将其进行了分解
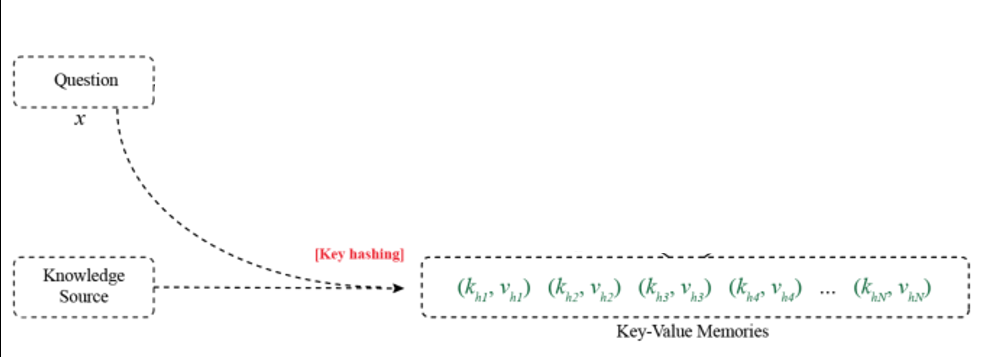
Key hashing:首先根据输入的问题从知识源中检索出与问题相关的事实,检索的方法可以是至少包含一个相同的实体等多种方法。也就是图中下面的绿色部分,相当于一个记忆的子集。这部分工作可以在处理数据的时候进行。然后将其作为模型输入的一部分,训练的时候输入模型即可。而知识源可以是知识图谱,维基百科,或者通过搜索引擎得到的结果。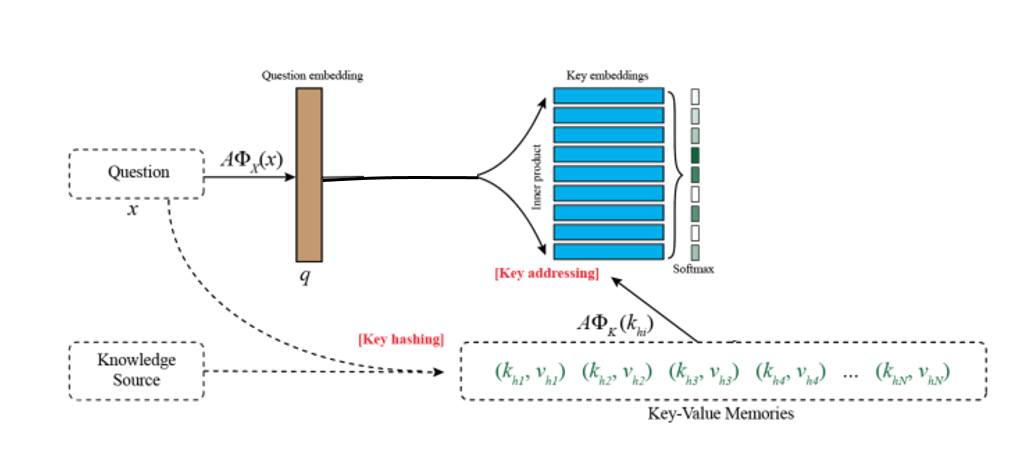
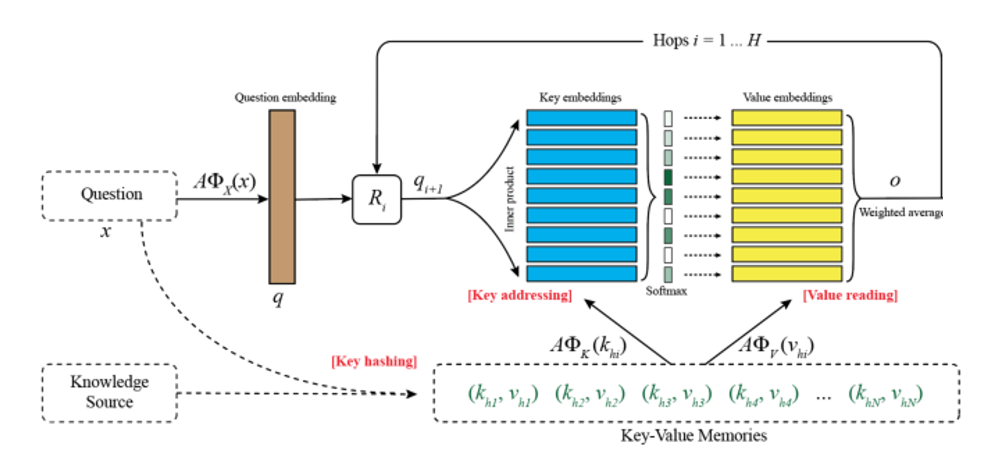
Key addressing:寻址,也就是对记忆单元进行相关性评分。用key memory与输入的问题相乘之后做softmax得到一个概率分布。概率大小就表明了相关程度。ox和ok都是embedding模型,对问题和key进行编码得到其向量表示。
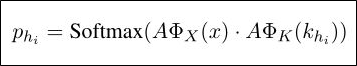
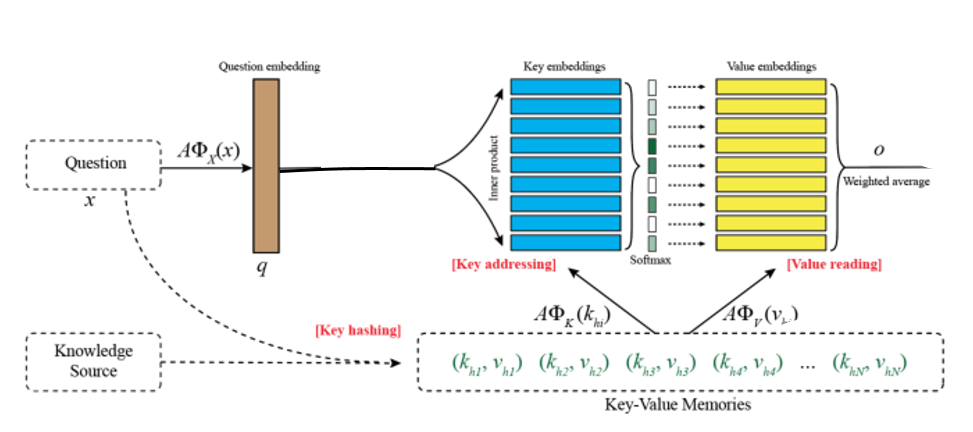
Value Reading:有了相关性评分,接下来就对value memory进行加权求和即可,得到一个输出向量o,计算公式如下。这样就完成了一个hop的操作。
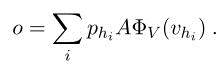
接下来将输出向量o与输入问题的向量表示q相加,经过矩阵进行映射,再作为下一层的输入,重复循环这个过程即可。
最后,使用一个答案的预测层即可,计算公式如下。yi可以理解为所有知识库中的实体或者候选的答案句子,使用交叉熵作为损失函数即可,然后就可以端到端的对模型进行反向传播训练。

2 模型创新点
整个过程其实跟端到端的模型很相似,最关键的地方就在于Key-Value的记忆如何表示,这也是本模型的创新所在。
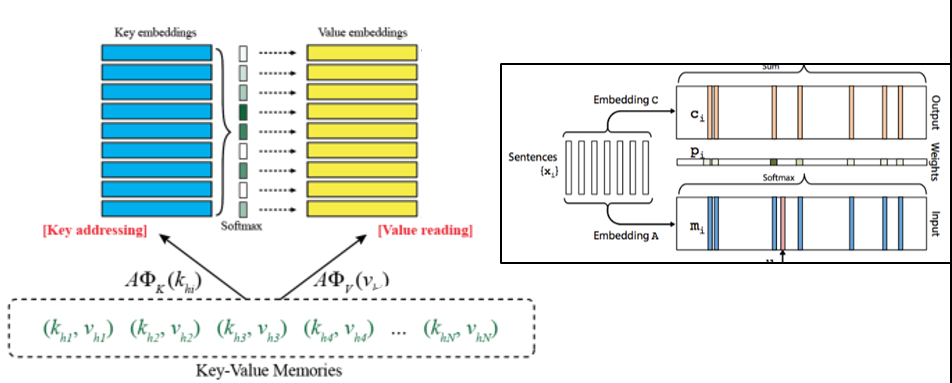
KV记忆网络的好处在于可以很方便的对先验知识进行编码,这样就可以让每个领域的人都方便的将本领域内的一些背景知识编码进记忆中,从而训练自己的问答系统,相比于端到端模型将相同的输入经过不同的矩阵分别编码到input和output模块中,KV模型则选择对输入首先进行一个(key, value)形式的表示,然后再分别编码进入key和value两个记忆模块,于是就有了更多的变化和灵活性。我们可以按照自己的理解对数据进行key索引和value记忆,而不需要完全依赖于模型的embedding矩阵,这样也可以使模型更方便找到相关记亿并产生与答案最相近的输出。
论文根据不同形式的输入(也就是不同的知识源),提出了几种不同的编码方式:
KB Triple:由于知识库是以三元组的形式构成,于是很方便就可以表示为(key, value)的形式。首先将知识库复制一份,并将其中一份进行反转,也就是将主谓宾反过来变成宾谓主,这样使得有些问题可以很方便的被回答。然后将每个三元组的主+谓作为key,宾作为value即可(可以想象,一般的问题都是主语干了什么事之类的,所以主+谓作为key可以更好的跟问题进行匹配,而宾语往往是答案,所以这样的组合很合理)
Sentence Level:以句子为单位进行存储的时候,与端到端的模型一样,都直接将句子的向量表示存入记忆槽即可,也就是key和value一样。
Window Level:主要以窗口长度W对原始文章进行切分(只取以实体作为窗口中心的样本),然后将整个窗口的向量表示作为key,该实体作为value。因为整个窗口的模式与问题模式更像,所以用它来对问题相关性评分可以找到最相关的记忆,而答案往往就是实体,所以将窗口中心的实体作为value对生成答案更方便。
Window + Title:该方式使用窗口的向量表示作为key,使用文章的标题title作为value(知识源是多篇文章的情况)。比如对于电影信息而言,文章标题往往就是电影名称,所以更贴近问题的答案。
3 参考资料
[1]论文原文
[2]参考笔记:
- 记忆网络之Key-Value Memory Networks(知乎-呜呜哈)
- 记忆网络之Key-Value Memory Networks tensorflow实现(知乎-呜呜哈)
- 记忆网络系列之Key Value Memory Network (北邮张博)
[3]参考代码:lc222、siyuanzhao