CPNDet论文链接
一.背景
anchor-based方法将大量框密集分布在feature map上,在推理时,由于预设的anchor与目标差异大,召回率会偏低。而anchor-free不受anchor大小限制,在任意形状上会更加灵活,但是像CornerNet这种,先进行角点检测,将有效的角点枚举组合成大量候选预测框,容易带来大量的FP。而FCOS需要回归关键点到边界的距离,对于长宽大的物体也比较难以预测。

二.网络介绍
1.网络结构以及loss函数

Stage 1: Anchor-free Proposals with Corner Keypoints
假定每个目标都由两个关键点进行定位,先根据CornerNet输出一对左上右下的heatmap,选择top-k个左上角点以及top-k个右下角点。将有效的关键点组合成目标的候选框,关键点组合是否有效主要有两个判断:
-
左上右下关键点是否属于同一个类别
-
左上角点坐标比右上角点小
同时作者认为cornernet那种embedding向量组合不是保证能够学习到的,在未见过的场景和目标挨得比较近时都会造成性能下降。

Stage 2: Two-step Classification for Filtering Proposals
由于产生heatmap的feature map较大,在角点进行组合时,虽然极大提高了召回率但同时特提升了误检率,还加大了过滤的计算量。所以先进行二分类,过滤掉80%候选框,然后在对剩下的框进行多分类。

首先在feature map上选用7*7RoIAlign提取每个候选框的特征,在使用1个32*7*7输出二分类的分类score。

二分类loss采用focal loss变种。
N:正样本数量;
IoUm:第m个候选框和所有gt box的IOU;
p m:第m个候选区域的分类score;
τ:IOU阈值,一般选择0.7;
α :超参,为2,用来平滑loss函数。
第二步对剩下的框进行多分类,用一个256*7*7输出C维向量,进行C分类,C分类loss也采用focal loss变种。
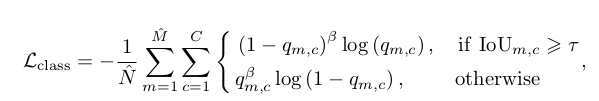
M̂:上一步过滤后的候选框;
N̂:正样本框
IoU m,c:类别是c为第m个候选框和所有gt box的IOU;
qm,c:类别是c,第m个候选区域的分类score;
α,β:超参,为2,用来平滑loss函数
2.总的loss函数

Ldetcorner:角点定位和cornernet一样;
Loffsetcorner:角点偏移
Lprop:二分类fcoal loss
Lclass:多分类fcoal loss
3.推理阶段
第一个阶段先使用0.2阈值,过滤掉大部分框,在对剩下的框进行多分类。在进行soft Nms即可。
![]()
s1:角点的分类score(两个角点的平均)
s2:多分类的score
当两个中一个大于0.5时,才采用上述式子得出预测的类别score,在归一化为[0,1]之间。
三.实验结果
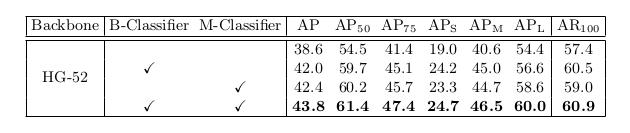
1.是否带二分类的实验结果对比
2.和各种检测框架的实验结果对比
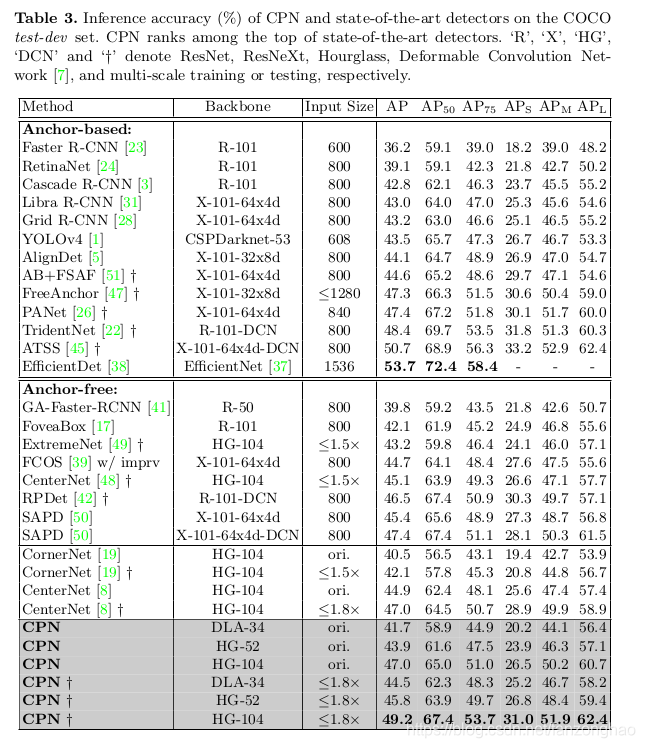
3.速度和精度的对比