基于CRAFT改进,提出的字符得分图有助于识别器更好地关注字符中心点,并且识别损失向检测器模块的传播会增强字符区域的定位。
ECCV2020
论文地址:https://arxiv.org/pdf/2007.09629
1. 总述
典型的场景文字检测识别分为检测和识别模块两个单独的分支,并且通常使用RoI Pooling来让这两个分支共享视觉特征。 然而这种方式不是在训练整个网络,而是利用检测和识别损失来训练共享特征层。所以拥有一个统一的模型不仅可以提高模型的大小和速度,还可以帮助模型学习提高整体性能的共享特征。
本文立足于:当采用使用基于注意力的识别器和表示字符区域空间信息的检测器时,仍然存在在模块之间建立更多互补连接的机会,因为这两个模块共享一个共同的子任务——查找字符区域的位置。 通过这两个模块的紧密集成,检测级的输出有助于识别器更好地关注字符中心点,而从识别器到检测器的损失传播增强了字符区域的定位。
基于这些分析,本文构建了紧密耦合的single pipeline模型。
- 通过利用识别器中的检测输出并传播识别损失到检测阶段来形成此模型。
- 字符得分图的使用帮助识别器更好地关注字符中心点,并且识别损失向检测器模块的传播增强了字符区域的定位。
- 增强的共享阶段允许对任意形状的文本区域进行特征校正和边界定位。
2. 总体结构
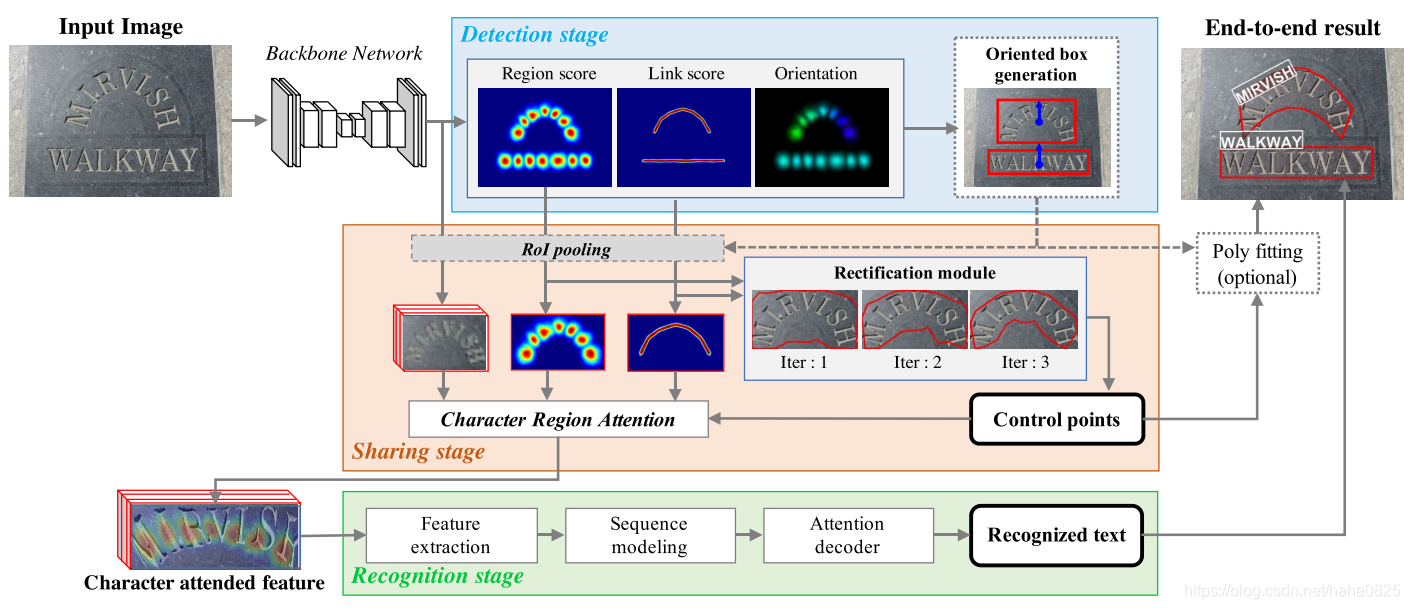
- 检测阶段接收一个输入图像并定位定向文本框。
- 共享阶段然后pool主干高层次特征和检测器输出。然后使用校正模块校正pooling的特征,并将其连接在一起以形成字符注意力特征。
- 在识别阶段,基于注意的解码器利用字符注意力特征(character attended feature-CAF)来预测文本。
- 最后,可以选择使用一种简单的后处理技术来实现更好的可视化。
2.1 检测阶段
选择CRAFT[Baek, Y., Lee, B., Han, D., Yun, S., Lee, H.: Character region awareness for text detection]作为基础网络,因为它能够表示字符区域的语义信息。CRAFT的输出代表字符区域的中心概率以及将它们连在一起。作者认为这种字符中心信息可以用来支持识别器中的注意力模块,因为这两个模块都是为了定位字符的中心位置。
在本文的工作中,对原始的CRAFT模型做了三个改变:主干替换(Backbone replacement)、链路表示(Link representation)和方向估计(Orientation estimation)。
检测部分的最终输出为4个通道,分别为字符区域映射 S r S_r Sr、字符链接映射 S l S_l Sl和两个方向映射 S s i n 、 S c o s S_{sin}、S_{cos} Ssin、Scos。
这部分总体结构如图:
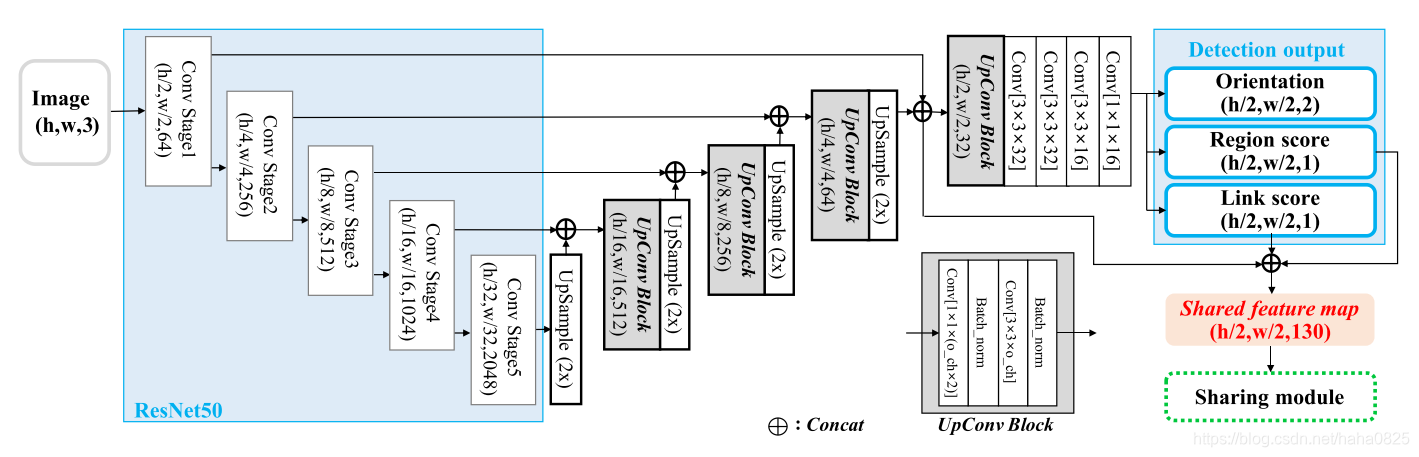
2.1.1 Backbone replacement
VGG-16替换为ResNet-50
2.1.2 Link representation
垂直文本的出现在拉丁语文本中并不常见,但在东亚语言如汉语、日语和韩语中却经常出现。在本文工作中,一个二进制中心线被用来连接序列字符区域。这种改变是因为在垂直文本上使用原始的相似性映射(original affinity maps )通常会产生不适定的透视变换(ill-posed perspective transformation),从而生成无效的框坐标。为了生成GT链接图,在相邻字符之间绘制一条厚度为t的线段。这里, t = m a x ( ( d 1 + d 2 ) / 2 ∗ α , 1 ) t=max((d1+d2)/2*α,1) t=max((d1+d2)/2∗α,1),其中 d 1 d_1 d1和 d 2 d_2 d2是相邻字符框的对角线长度, α α α是缩放系数(本文设置为0.1)。使用该公式可以使中心线的宽度与字符的大小成比例。
2.1.3 Orientation estimation
获得文本框的正确方向非常重要,因为识别阶段需要较好的文本框坐标来正确识别文本。为此,在检测阶段添加两个通道输出,分别用于预测字符沿x轴、y轴的角度。为了生成方向图的GT,将GT字符边界框的向上角表示为 θ b o x ∗ θ_{box}^* θbox∗,预测x轴的通道值为 S c o s ∗ ( p ) = ( c o s θ + 1 ) × 0.5 S_{cos}^*(p)=(cosθ+1)×0.5 Scos∗(p)=(cosθ+1)×0.5,预测y轴的通道值为 S s i n ∗ ( p ) = ( s i n θ + 1 ) × 0.5 S_{sin}^*(p)=(sinθ+1)×0.5 Ssin∗(p)=(sinθ+1)×0.5。通过用 S c o s ∗ ( p ) S_{cos}^*(p) Scos∗(p)和 S s i n ∗ ( p ) S_{sin}^*(p) Ssin∗(p)的值填充字框区域中的像素p来生成GT方位图。三角函数不直接用于让通道具有与区域映射和链接映射相同的输出范围;介于0和1之间。
2.1.4 loss 函数
方向预测的loss为:
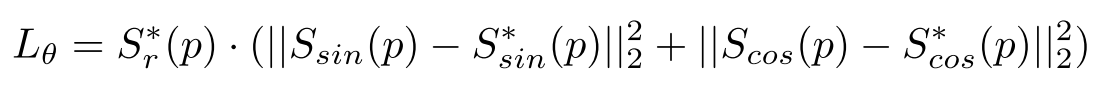
其中, S c o s ∗ ( p ) S_{cos}^*(p) Scos∗(p)和 S s i n ∗ ( p ) S_{sin}^*(p) Ssin∗(p)表示文本方向的GT,这里,字符区域分数 S r ( p ) S_r(p) Sr(p)被用作权重因子,因为它表示字符中心的置信度。通过这样做,方向损失只计算在正面字符区域。
检测部分总的loss为:
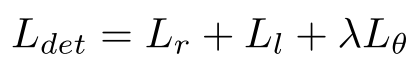
L r L_r Lr和 L l L_l Ll表示字符区域损失和链路损失,这两个和CRAFT完全相同。 L θ L_θ Lθ是方向损失,乘以 λ λ λ(本文设为0.1)来控制权重。
2.2 共享阶段
2.2.1 文本纠正模块
为了校正任意形状的文本区域,采用了thin-plate spline(TPS)[Shi, B., Yang, M., Wang, X., Lyu, P., Yao, C., Bai, X.: Aster: An attentional scene text recognizer with flexible rectification]变换。本文的校正模块采用迭代TPS来获得文本区域的更好表示。通过有吸引力地更新控制点,可以改善图像中文本的曲线几何。(实验发现三次TPS迭代就足以进行校正)
典型的TPS模块以文字图像作为输入,但由于字符区域图和链接图都封装了文本区域的几何信息,所以本文给它们提供字符区域图和链接图。使用20个控制点来紧密覆盖曲线文本区域。为了使用这些控制点作为检测结果,它们被转换到原始输入图像坐标。然后可以选择执行二维多项式拟合来平滑边界多边形。
迭代TPS和最终平滑多边形输出的示例如图所示:
2.2.2 字符注意力模块
CRA模块是实现检测与识别模块紧密耦合的关键部件。通过简单地将校正后的字符得分图与特征表示相连接,该模型建立了以下优点:
- 在检测器和识别器之间建立一个链接,可以使识别丢失在检测阶段传播,从而提高字符评分图的质量。
- 此外,附加字符区域映射到特征有助于识别器更好地关注字符区域。
2.3 识别阶段
主要分为三个阶段,特征提取,序列建模,预测。
- 特征提取模块采用高层语义特征作为输入,使得特征提取模块比单独的识别器更轻;
- 在提取特征后,采用双向LSTM进行序列建模;
- 使用基于注意力的解码器进行最终的文本预测。
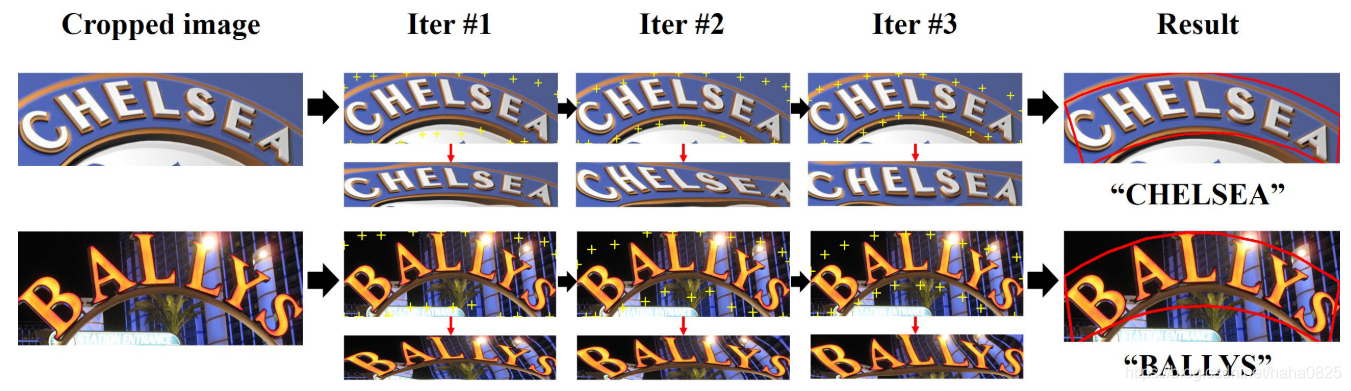
在每一个时间步,基于注意力的识别器通过mask注意力的输出到特征上来解码文本信息。虽然注意力模块在大多数情况下都能很好地工作,但当注意力点错位或消失时,它无法预测字符。下图显示了使用CRA(字符区域注意力)模块的效果。恰当的注意力点可以进行健壮的文本预测。

红点代表解码字符的注意力点。缺少的字符用蓝色表示,错误识别的字符用红色表示。
识别阶段的损失为:
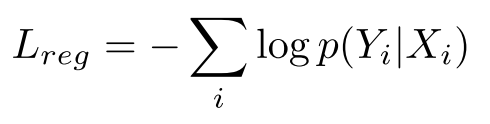
其中, p ( Y i ∣ X i ) p(Y_i | X_i) p(Yi∣Xi)表示第 i i i个词框( X i X_i Xi)的裁剪特征表示( Y i Y_i Yi)的字符序列的生成概率。
2.4 总的loss
总的loss为检测loss加上识别loss,具体的loss传播流程如图:
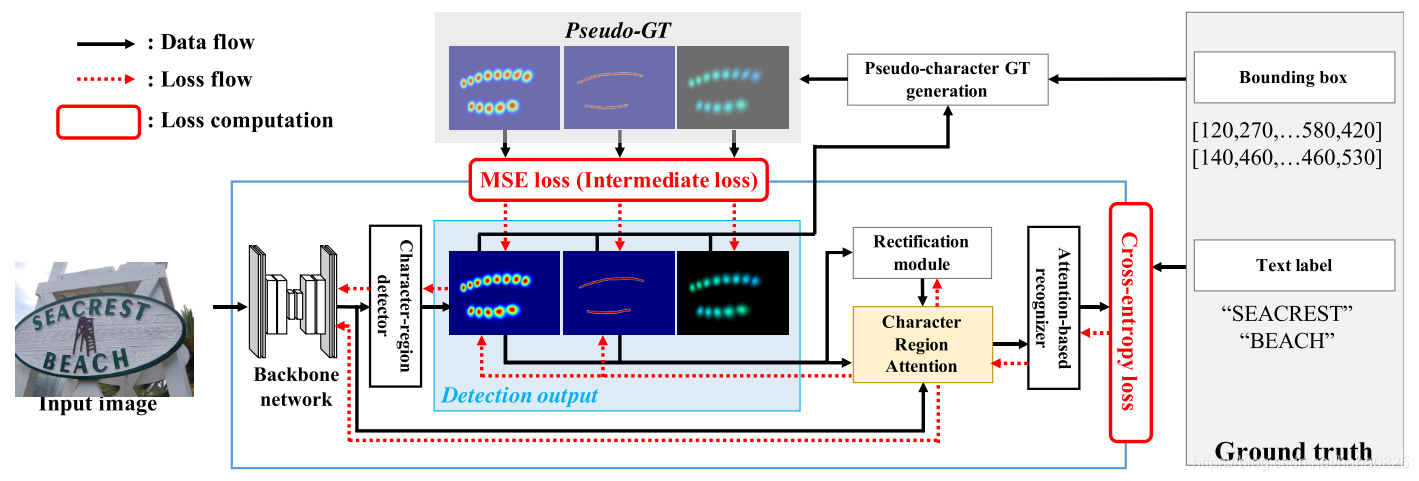
损失在识别阶段通过权重流通,通过字符区域注意力模块向检测阶段传播。另一方面,检测损失被用作中间损失,因此检测阶段之前的权重同时使用检测和识别损失进行更新。
3. 实验
(1)水平拉丁语数据集(ICDAR13和15)的结果:
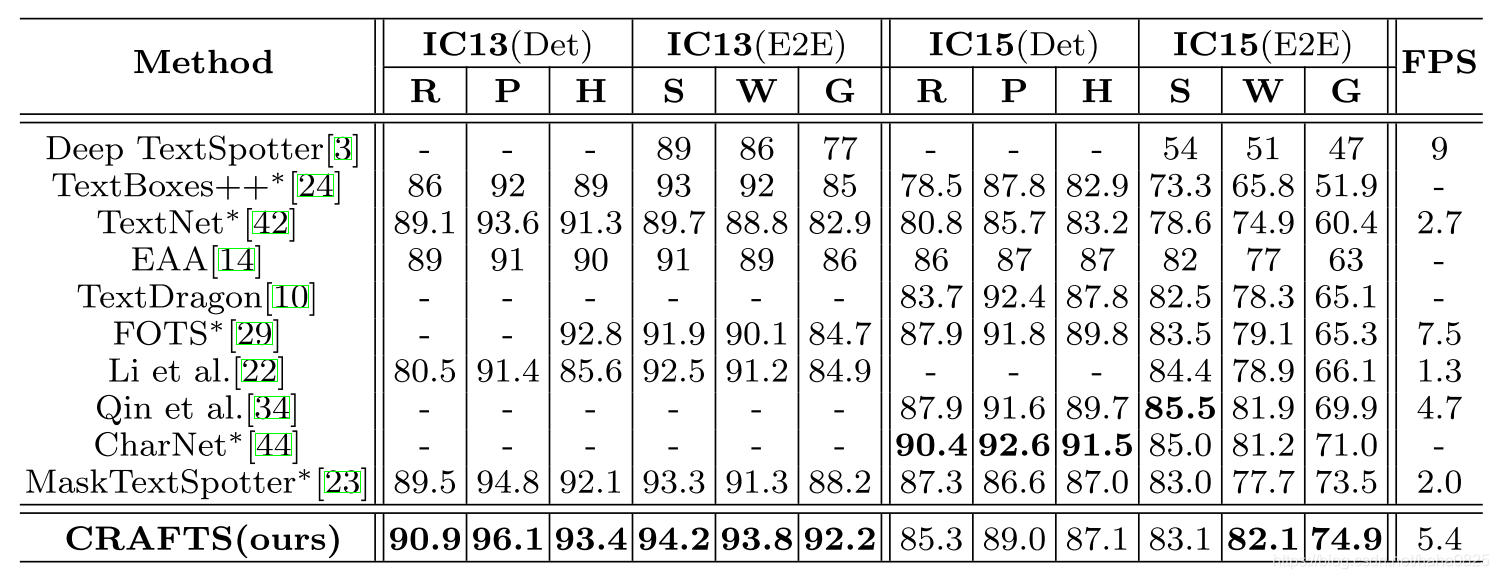
*表示基于多尺度测试的结果。R、 P和H分别表示召回率、精密度和H均值,S、W和G分别表示强、弱和一般语境化结果。最好的分数用粗体突出显示。ICDAR 2013检测任务的评估指标为Deeval,其他三个案例采用IoU指标。由于实验环境不同,FPS仅供参考。
(2)弯曲文本数据集(TotalText)的结果:
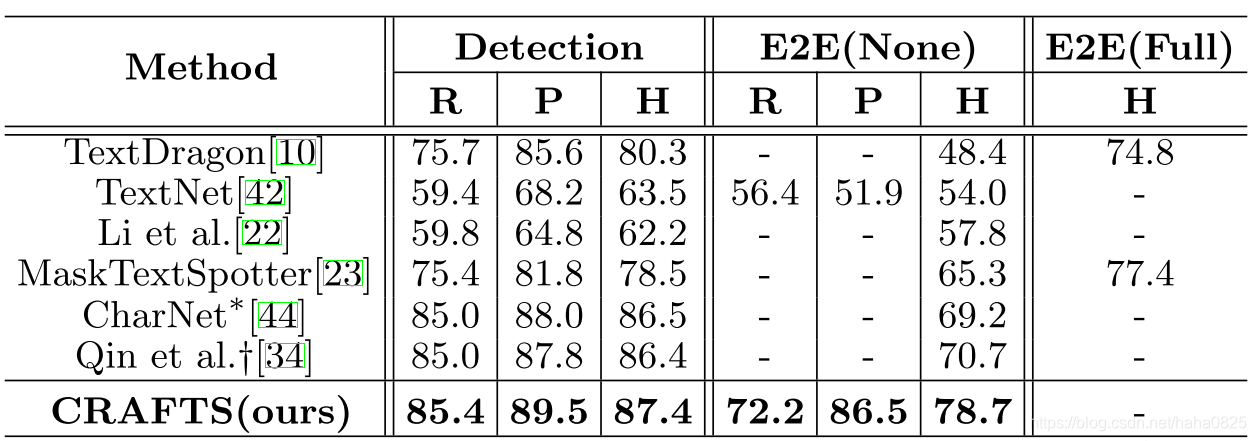
None意味着没有词汇用于语境化。Full词典包含测试集中的所有单词。*表示多尺度推理,而†表示在私有数据集上训练的模型。
(3)多种语言文本数据集(ICDAR2019)上的结果:

(4)消融实验
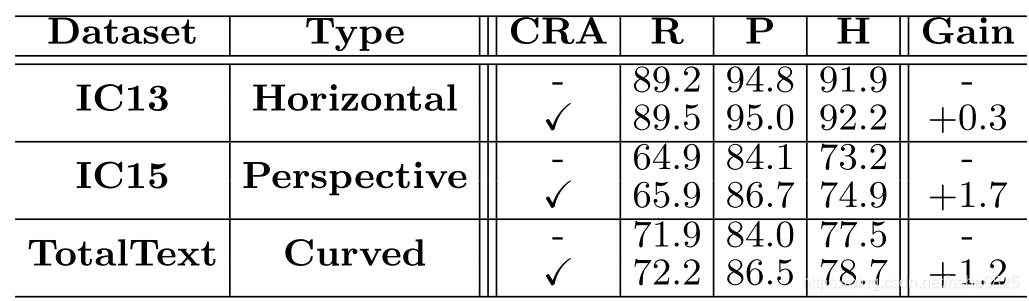
TotalText上结果和IC13结果相差巨大,这意味着在处理不规则文本时,输入字符注意力信息可以提高识别器的性能。