Character Region Awareness for Text Detection
摘要
以前用严格的词边界训练方法来表示一个任意形状的文本区域存在一定的限制。本篇论文我们提出了一个新的自然场景下检测文本区域测方法,它通过探索每个字符以及字符之间的相似性来实现。为了克服单个字符水平标注的缺陷,我们的方法不仅探索了合成图像的字符标注同时也评估了真实图像字符集水平的标注通过学习的中间模型。为了评估字符之间的相似性,网络提出了新的紧密型表示。在6个数据集上的结果,表明提出的方法在复杂自然场景下,如任意方向、弯曲、以及形变文字都具有较高的灵活性。
引言
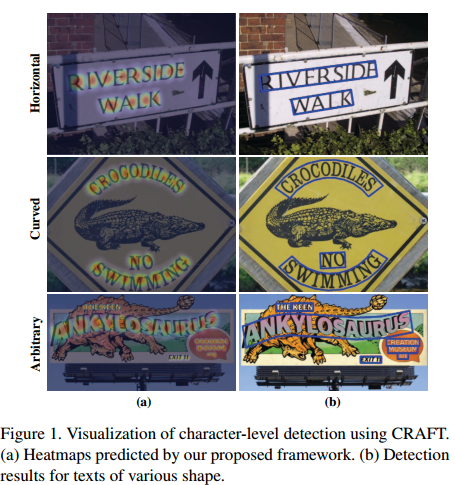
文本我们提出了一个新颖的检测器,对于一个文本区域定位单个字符以及与已定位字符的联系。我们的框架CRAFT,会产生一个字符区域得分和一个紧密得分。区域得分是用来定位图像中的单个字符,关联得分是用来分组每个字符成为一个单独实例。为了补偿字符水平标注的缺点,我们提出了弱监督学习框架来评估真实数据集中字符水平的标注。如图1是一些检测样例结果。
- 基于回归的文本检测方法
不像一般的物体检测方法,文本经常是不规则的形状以及各种长宽比。为了处理这些问题,TextBoxes++系列修改卷积核以及anchor boxes来捕获各种文本形状。Rotation-Sensitive Regression Detector (RSDD)充分利用旋转不变形特征来进行检测。这种检测方法只能检测矩形以及旋转矩形的文本区域,因此存在较大限制。 - 基于语义的文本检测方法
另一种方法是通过语义分割的方法来实现,通过像素级的水平来寻找文本区域。SSTD通过注意力机制结合回归与语义分割方法在特征水平来增强文本区域联系减少背景的干扰。最近,TextSnake被提出通过预测文本区域以及几何特征的文本线。 - 端到端的文本检测
端到端的方法能同时检测文本以及识别文本,而且识别结果有助于增强检测结果。FOTS和EAA聚合了流行的检测与识别方法,以端到端的方式训练它们。Mask TextSpotter利用它模型统一的优势来对待识别任务作为一个语义分割任务。很明显,识别模块能帮助检测器更好的检测文本。
大多数检测文本的方法把单词作为基本单元,但是对于检测来说定义一个单词的大小是困难的,因为单词可以被各种规则分割,如含义,空格以及颜色。此外,单词分割的边界不能被严格的限制,所以单词分割本身没有明显的语义含义。这种单词模糊的标注无论对于回归还是对于语义分割方法来说都淡化了真实标注的意义。 - 字符级别的文本检测
Seglink 寻找部分文本区域并且联系这些区域用额外的连接预测。虽然Mask TextSpotter预测一个字符级水平的概率图,它是被用来文本识别而不是定位。
本文工作是受WordSup思想的启发,用一个弱监督框架来训练字符级水平的检测器。该方法的一个缺点是字符表示是以矩形框的锚来展示的,由于不同角度拍摄造成的字符形变不容易被检测出来,而且它受到基本骨架性能的影响(如SSD的anchor数量以及尺寸大小)。
方法
我们的主要目标是精确的定位自然场景中每个字符,我们训练一个深度学习网络来预测字符区域以及字符间的紧密程度,因为没有公共的数据集可以利用,因此模型是以弱监督的方式来进行训练。
整体架构
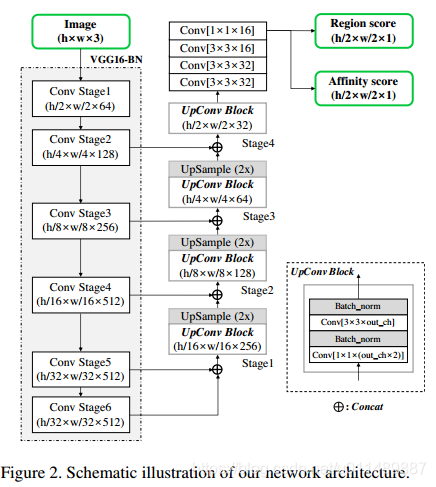
一个带有BN的VGG-16的全卷积网络架构被采用作为我们的网络骨架。我们的模型在解码阶段跳过连接,就像U-net聚合底层特征一样。最后的输出有两个通道作为分数图,区域分数和紧密连接分数,网络架构如图2所示。
训练
真实标签的生成
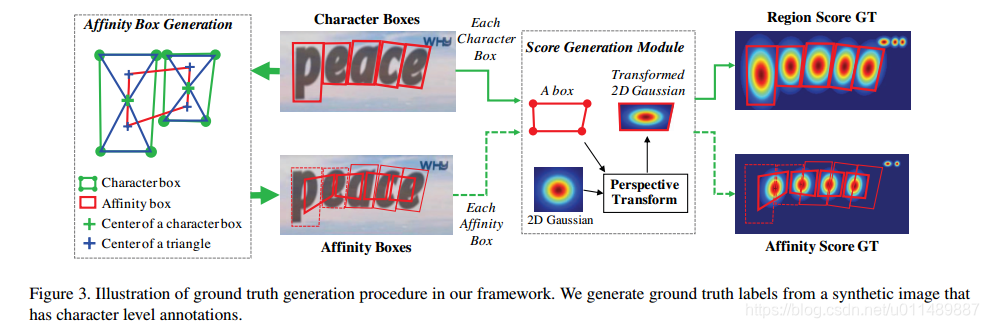
分数区域表示了所给像素是字符中心的概率,连接分数表示了相邻字符分开的概率。不像语义分割,对每个像素打标签。我们用高斯热力图编码字符的中心区域。热力图表示在其它应用中也经常被用到,像姿态估计。用热力图来学习区域分数和连接分数。图3展示了合成图像标签的生成。
- 计算二维高斯图
- 计算视角变换
- 用高斯图进行覆盖
提出的标注方法使得模型能够检测大的或长文本实例,无论是否用小的感受野。另一方面,先前的回归方法需要大的感受野,字符水平的检测使得仅关注内在字符特征,而不是整个文本实例。
弱监督学习
真实数据集有单词级别的标注,我们借助单词基本的标注生成字符框以弱监督方式,如图4,真实图片单词级别的标注提供时,学习模型预测字符分割生成字符水平的边界框。为了反应预测的真实性,预测的字符个数与实际的字符个数之比作为学习权重。
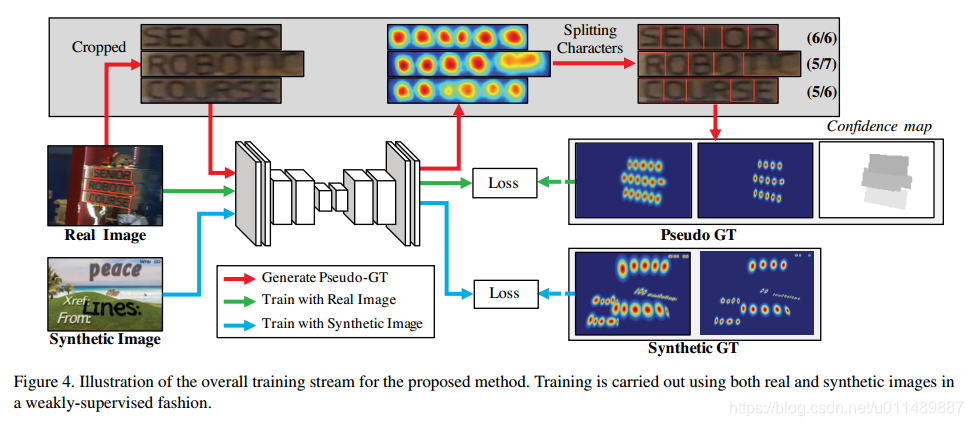
图6展示了字符分割的整个流程。首先,从原图像裁剪单词级别的图像块;然后训练的模型预测区域分数;再用watershed算法来分割字符区域,即获得字符的标注框。最后再将标注转换到原图上。生成的真实标注对应的区域分数和连接分数通过图3的流程来生成。
当弱监督训练时,我们强迫用不完整的生成的标注来训练。如果模型用不精确的区域分数来训练,字符区域的输出可能是模糊的。为了防止这种情况,我们用模型测量每个生成标签的质量。幸运的是文本标注有一个非常强的线索,就是单词长度。大多数数据集,单词的描述和单词的长度是提供的,可以被用来评估生成标签的可信度。
对于一个单词级别的标注样例W,让R(w)表示边框区域,l(w)表示w的长度。通过字符分割过程,我们可以获得字符边界框以及它们对应的长度,置信度sconf(w)的得分计算为:
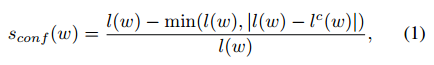
像素置信图Sc被计算为,
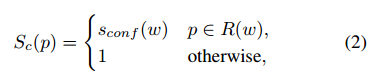
p表示区域R(w)的像素,目标L被定义为:
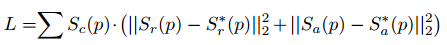
S*r( p ) 表示生成标注的区域分数,S*a( p )的变量表示连接分数图。Sr( p )和Sa( p )分别表示预测的区域分数和连接分数。当用合成数据训练时,我们可以获得真实标注,所以Sc( p )设置为1.
当训练执行完毕时,CRAFT模型能够更加准确的预测字符,置信度分数Sconf(w)也逐渐的增加。图5展示了训练期间字符区域分数。在训练的早期阶段,对于自然场景中的不熟悉的文本区域分数相当低。与SynthText数据集不同,模型学习新文本的外观,像不规则的字体和合成的文本有不同的数据分布。

如果Sconf(w)置信度分数小于0.5,预测得到的字符边界框应该被忽视,因为在训练过程中它们会产生不利的影响。在这种情况下,我们假定单个字符的宽是固定的,通过R(w)和l(w)来计算预测的字符。然后,Sconf(w)是被设置为0.5来学习看不见的文本的外观。
推理
在推理阶段,最后的输出可以被发布为各种形状,如单词框或字符框或多边形。对于ICDAR系列的数据集,评估标准使用单词级别的IOU,所以这里我们描述如何从预测的Sr和Sa来产生单词级别的包围框。
寻找包围框的后处理阶段总结如下。首先,二进制图M覆盖原图像初始化为0.M( p)被设置为1,如果Sr( p )>Thr或Sa( p )>Tha。Thr和Tha分别表示各自的阈值。M上的连接部分(CCL)被执行。最后,四边形包围框通过寻找包围连接部分的最小旋转矩形来获得。像connectedComponents以及minAreaRect的功能Opencv是提供的。
CRAFT的一个优势是不需要后处理方法,如NMS。因为我们有通过CCL进行单词区域分割的图像块。对于一个单词的包围框是通过封闭的矩形来定义的。特别指出的是,我们的字符连接过程是在像素水平进行的,与其它显式依靠搜寻文本连接部分连接方法不同。
除此之外,我们可以在整个字符区域生成一个多边形来高效的处理弯曲文本。多边形生成的流程在图7中描述,伴随着扫描方向第一步来寻找字符区域的局部极大线,如图中蓝色箭头所示。
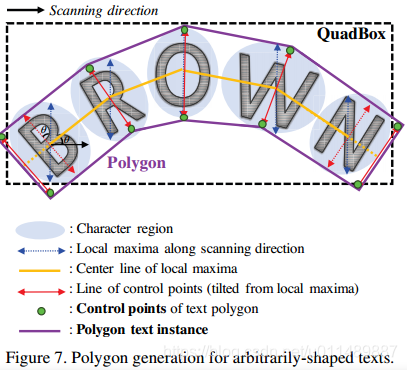
极大线的长度被设置为它们的最大值以防最后的多边形结果不规则的。连接极大线的中央点的线叫做中央线,如黄色所显示的。红色的线是由极大线旋转得到并垂直于中央线反映了文本倾斜的角度,它也是控制端点的线。为了获得完整的文本区域,我们把最外端的文字的端点沿着中央线向外移。得到最终的控制结果。
实验
数据集
IC13包含229张训练,233张测试;IC15包含1000张训练集和500张测试集;IC2017包含7200训练以及1800验证集还有9000张测试集包括9种语言。TotalText包含1225张训练以及300张测试,含有弯曲文本是单词级别的多边形标注。CTW1500是14个顶点标注的多边形。
训练策略
训练程序包含两个步骤,首先用SynthText数据集来训练网络50K次迭代,每个数据集都是微调模型。“DO NOT CARE"的文本区域不参与训练通过将Sconf(w)设置为0.用ADAM优化器来训练所有的进程。对于多GPU训练,训练和监督GPU是分离的,通过监督GPU生成的标签存在内存中。在微调阶段,SynthText数据集以1:5的比例使用确认字符区域能够分开。为了过滤掉像文本一样的文本,On-line Hard Negative Mining 被应用以1:3的比例。基本的数据增强像裁剪,旋转,颜色变换等被应用。
弱监督训练要求两类数据,裁剪单词的四边形标注以及计算单词长度的描述。符合条件的由IC13,IC15以及IC17.因此我们训练模型在ICDAR数据集上,然后在其他数据集上测试。一个模型是在IC15上训练和测试。另一个模型是在IC13和IC17上一块训练,然后在其它5个数据集上测试。微调的迭代次数设置为25K,所有的实验在NSML平台上执行。
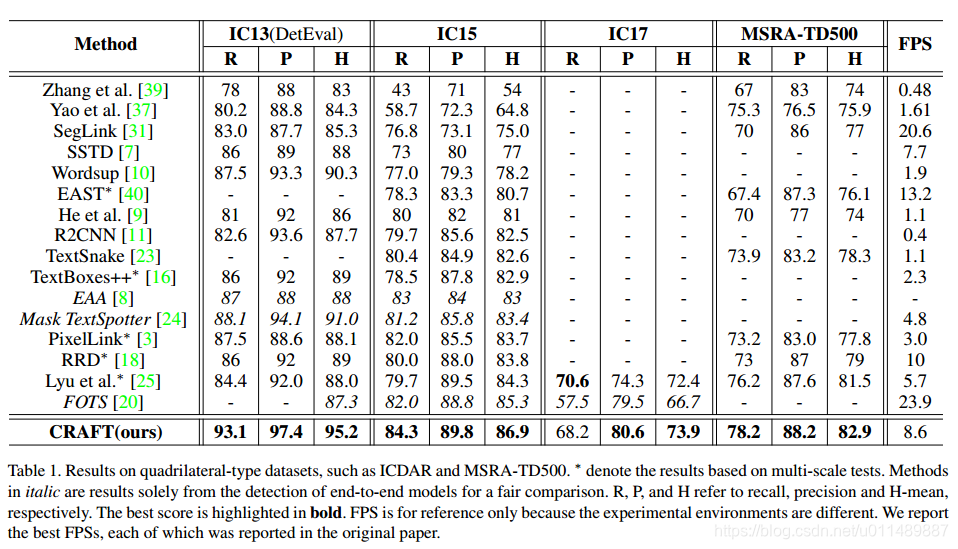


实验结果
对于MSRA-TD500数据集,标注是行级别的标注,单词之间包含空格。因此本方法检测得到单词后需要对相邻的单词的进行合并处理。对于TotalText和CTW-1500图像的长边固定为1280和1024.对于CTW-1500,两个困难存在,行级别的标注和任意形状,为了补救这种情况,一个小的连接改善网络LinkRefiner被运用。
讨论
- 尺度不变性的粗壮性:本方法在所有数据集上都进行单尺度的测试,不像其它数据集依靠多尺度测试来解决尺度变化大的问题。这个优势来自于模型的对字符的定位。
- 多语言问题:我们的模型不能辨别孟加拉和阿拉伯字符,因为在合成的训练集不包含这些。
- 与端到端的方法对比:我们的方法仅仅来检测,但是它可以跟端到端的方法相媲美。
- 通用能力:我们的方法不用额外的数据在3个数据集上实现了最好的性能。这展现了我们模型的普遍适用性。
结论
我们提出了一个新的文本检测器叫做CRAFT,它可以检测单个字符即使字符级别的标注不给出。真实数据集很好提供单个字符级别的标注,我们提出了一个弱监督的学习方式来生成标注从中间标注。未来的工作我们希望训练出一个端到端的网络来。