V1:以mask rcnn为基础,基于分割来进行端到端的文本识别。mask分支不仅能预测分割图来分割文本区域还可以预测字符概率图。
V2:在v1基础上在识别部分加入空间注意力以提升框架的文本识别能力。
V3:在v2基础上又加入SPN,替换RPN,用以生成proposal,生成的proposal更精准。
1. Mask TextSpotter v1
1.1 总体结构
总体主要包括两个部分:一个基于实例分割的检测部分和一个基于字符分割的识别部分。
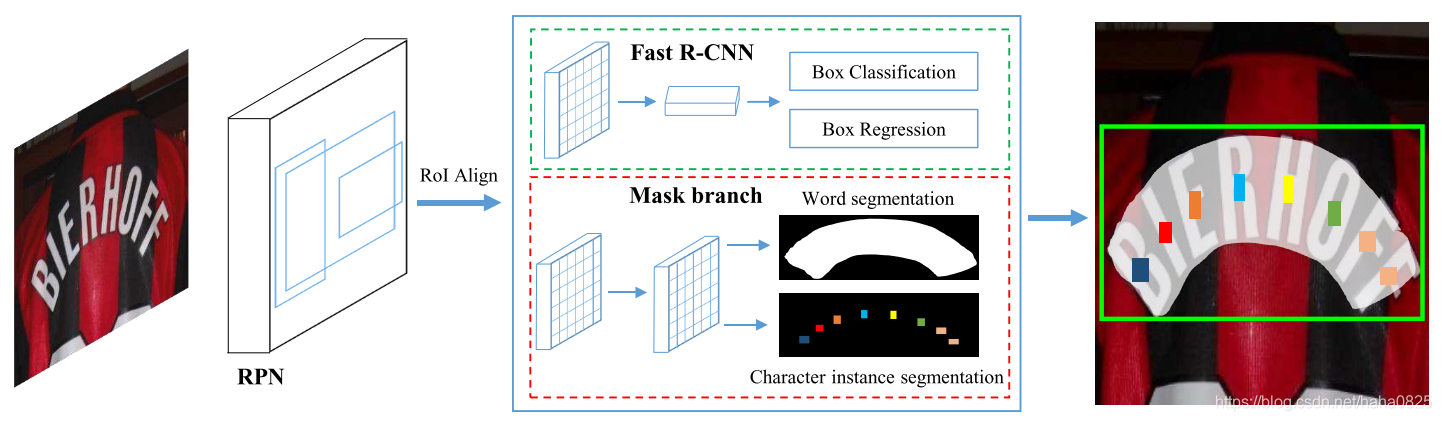
Backbone部分是ResNet-50+FPN,首先RPN得到proposals,然后将RoIAlign的特征分别送入fast rcnn分支和mask分支,前者得到精确的文本框,后者得到文本实例分割图和字符实例分割图,然后将这两个分割图用于识别文本。
1.2 Mask分支

如图所示,这个分支包括四个卷积层和一个反卷积层。输入大小固定为16×64的RoI特征,预测38个map(大小为32×128),包括全局文本实例map、36个字符map和字符的背景map。全局文本实例map可以精确定位文本区域,而不管文本实例的形状如何。36个字符的map,包括26个字母和10个阿拉伯数字。后处理还需要不包括字符区域的字符背景map。
1.3 Label Generation
对于检测分支:首先将多边形转换成水平矩形,以最小的面积覆盖多边形。然后根据[fast rcnn,fpn,faster rcnn]为RPN和Fast R-CNN生成target。
对于mask分支,有两种类型的target map需要生成,即一种用于文本实例分割的全局映射和一种用于字符语义分割的字符映射(可能没有,数据集未提供就无法生成)。给出一个正的proposal-r,首先利用[[fast rcnn,fpn,faster rcnn]的匹配机制来获得最佳匹配的水平矩形。可以进一步得到相应的多边形和字符(如果有的话)。接下来,对匹配的多边形和字符框进行移动和调整大小,以将proposal和大小为H×W的target map对齐,如下公式所示: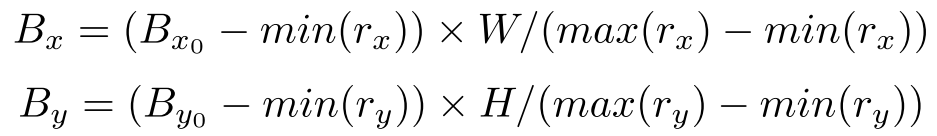
其中, ( B x , B y ) (B_x,B_y) (Bx,By)和 ( B x 0 , B y 0 ) (B_{x0},B_{y0}) (Bx0,By0)分别是多边形和所有字符框的更新后的顶点和原始顶点, ( r x , r y ) (r_x,r_y) (rx,ry)是proposal-r的顶点。
然后,在初始化为零的mask上绘制归一化的多边形并用值1填充多边形区域,就可以生成target global map。

对于生成target character map,首先通过固定字符边界框的中心点并将边缩短到原始边的四分之一来缩小所有的字符边界框。然后,将收缩字符边界框中的像素值设置为相应的类别索引,并将收缩字符边界框外部的像素值设置为0。如果没有字符边界框批注,则所有值都设置为−1。
1.4 Inference
图片输入基础网络提取特征,然后送入fast rcnn得到文本预测框,然后NMS后将剩下的框
送入到mask分支,生成全局映射和字符映射;最后通过计算全局map上文本区域的轮廓线,直接得到预测的多边形,并利用本文提出的字符map像素投票算法生成字符序列。
像素投票算法:

左:预测的字符映射;右:对于每个连接区域,通过平均相应区域中的概率值来计算每个字符的分数。

具体来说,首先对背景图B进行二进制化,其中的值从0到255,阈值为192。然后得到所有字符区域根据二值化map中的连接区域R。接着计算所有字符映射C的每个连通区域的平均值。这平均些值可以看作是该区域的字符类概率。平均值最大的字符类将分配给该区域。然后,根据英语的写作习惯,把所有的字符从左到右分组。
Weighted Edit Distance
编辑距离可以用来在给定的词库中找到预测序列的最佳匹配词。然而,在同一时间内,可能会有多个词与最小编辑距离匹配,算法无法确定哪一个是最佳的。产生上述问题的主要原因是原编辑距离算法中的所有操作(删除、插入、替换)的代价都是相同的,这实际上是没有意义的。

本文提出了一种加权编辑距离算法。如上图所示,与为不同操作分配相同成本的编辑距离不同,本文提出的加权编辑距离的成本取决于像素投票产生的字符概率 p i n d e x c p_{index}^c pindexc。数学上,长度分别为 ∣ a ∣ | a | ∣a∣和 ∣ b ∣ | b | ∣b∣的两个字符串a和b之间的加权编辑距离可以描述为 D a , b ( ∣ a ∣ , ∣ b ∣ ) D_{a,b}(| a |,| b |) Da,b(∣a∣,∣b∣),其中:
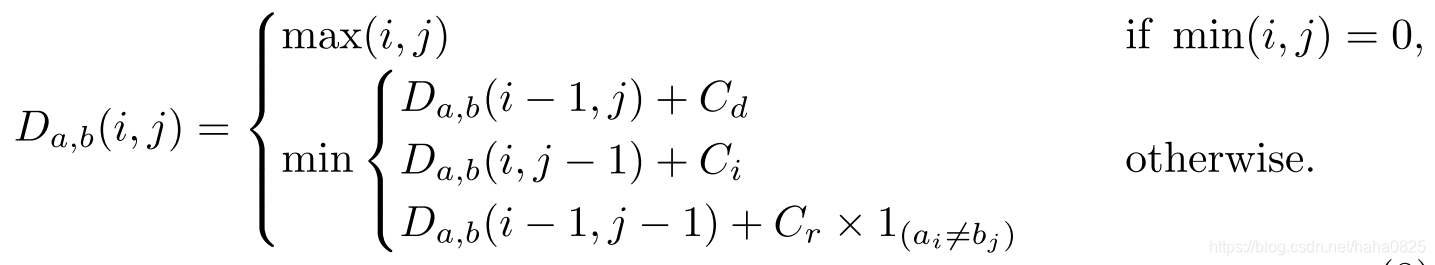
式中, 1 ( a i ≠ b j ) 1_{(a_i≠b_j)} 1(ai=bj)是指示函数,当 a i = b j a_i=b_j ai=bj时等于0,否则等于1; D a , b ( i , j ) D_{a,b}(i,j) Da,b(i,j)是a的前i个字符与b的前j个字符之间的距离; C d C_d Cd、 C i C_i Ci和 C r C_r Cr分别是删除、插入和替换成本。
2. Mask TextSpotter v2
V2版本主要的贡献是将空间注意力应用到识别部分,所以主要介绍空间注意力部分。
字符分割有一些局限性:
- 首先,字符分割需要字符级注释来监督训练。
- 其次,需要一种特殊设计的后处理算法从分割图中生成文本序列。
- 第三,不能从分割图中获得字符的顺序。
虽然通过一些规则可以将字符组合成文本序列,但通用性仍然有限。为了克服这些局限性,本文引入了一个空间注意模块(SAM),以端到端的方式从特征图中解码文本序列。与之前的方法[B. Shi, M. Yang, X. Wang, P. Lyu, C. Yao, and X. Bai. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell., 2018]不同,前者先将特征映射编码为一维特征序列,然后进行解码,SAM直接解码二维特征映射,以更好地表示各种形状。
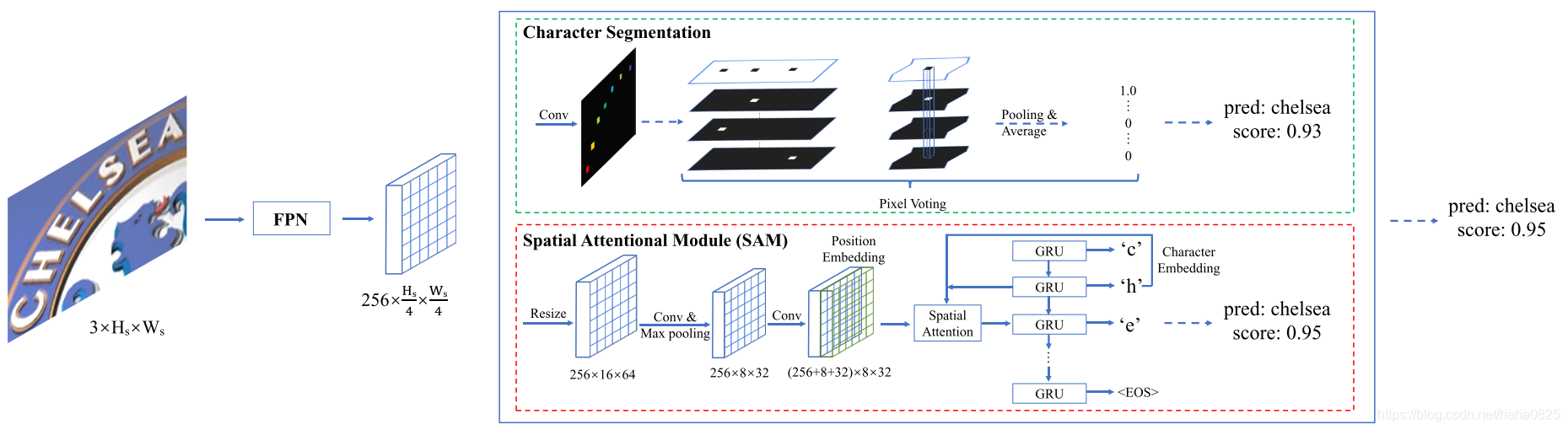
图中这两个模块(字符分割以及空间注意力)都可以提供识别结果以及它们的置信度,然后动态地选择置信度较高的作为最终的识别结果。实线箭头表示训练和推理阶段的步骤;虚线箭头仅表示推理阶段的步骤。
SAM的整个流程如图所示。首先,通过双线性插值将给定的特征映射调整为固定形状,该特征映射可以是Mask TextSpotter中的RoI特征,也可以是独立识别模型中的主干特征图。然后,依次执行卷积层、最大池化层和卷积层。最后,利用RNNs的空间注意力生成文本序列。
Position Embedding
由于SAM的变换算子对位置不敏感,所以采用位置嵌入,在最后一个卷积层上加入位置嵌入。位置嵌入特征图 F p e F_{pe} Fpe的shape为 ( W p + H p , H p , W p ) (Wp+Hp,Hp,Wp) (Wp+Hp,Hp,Wp), H p H_p Hp和 W p W_p Wp分别设置为8和32,位置嵌入特征图计算方式为:

其中 o n e h o t ( i , K ) onehot(i,K) onehot(i,K)表示长度为K的向量V,其中索引为i的元素的值设置为1,而其余值设置为0。将位置嵌入特征映射与原始输入特征映射进行Concat。拼接特征映射F的形状为 ( C + H p + W p , H p , W p ) (C+H_p+W_p,H_p,W_p) (C+Hp+Wp,Hp,Wp),其中C是原始输入特征图的通道的数目(256)。
Spatial Attention with RNNs
注意机制基于[D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014],不过作者将其扩展到一个更一般的形式,即在二维空间中学习注意力权重。
假设它迭代T步来预测一个字符类序列 y = ( y 1 , … , y T ) y=(y_1,…,y_T) y=(y1,…,yT)。在步骤 t 中,有三个输入:
- (1)前面提到的输入特征映射-F
- (2)最后的隐藏状态 s t − 1 s_{t−1} st−1
- (3)最后的预测字符类 y t − 1 y_{t−1} yt−1
首先,通过复制将向量 s t − 1 s_{t−1} st−1扩展到形状为 ( V , H p , W p ) (V,H_p,W_p) (V,Hp,Wp)的特征图 S t − 1 S_{t−1} St−1,其中V是RNN的hidden size,设置为256:

然后计算注意权重 α t α_t αt如下:

式中, e t e_t et和 α t α_t αt的形状为 ( H p , W p ) (H_p,W_p) (Hp,Wp)。 W t 、 W s 、 W f W_t、W_s、W_f Wt、Ws、Wf和 b b b是可训练的权重和偏差。
接下来,可以通过对原始特征映射F应用注意力权重来获得第t步的glimpse g t g_t gt:

RNN的输入 r t r_t rt由glimpse g t g_t gt和最后预测的字符类 y t − 1 y_{t−1} yt−1的字符嵌入拼接:
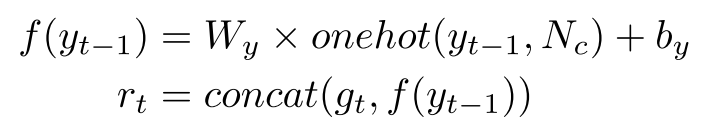
其中 W y W_y Wy和 b y b_y by是线性变换的可训练权重和偏差。 N c N_c Nc是序列译码器中的类数,设置为37个,其中字母数字字符36个,序列结束符号(EOS)1个。然后将RNN的输入 r t r_t rt和RNN的最后一个隐藏状态 s t − 1 s_{t-1} st−1送入RNN单元:

最后,通过一个linear transformation 和一个 softmax function计算步骤t的条件概率:

3. Mask TextSpotter v3
V3主要工作是提出SPN模块替代RPN来生成proposals,SPN不基于Anchor,而是基于分割mask,所以更加精确,可以处理极端宽高比、不规则的文本实例。而精确的proposal可以使得使用mask ROI特征来分离相邻文本实例,使得识别精度不受附近文本或噪声的影响。所以这里主要介绍SPN。

SPN采用U-Net网络结构(对尺度具有鲁棒性)提取特征,然后融合不同层次的特征进行分割得到F,然后生成proposals,接着使用Hard RoI masking提取proposal特征,最后送入识别网络进行识别。
Segmentation label generation
为了分离相邻的文本实例,采用Vatti裁剪算法 [Vatti, B.R.: A generic solution to polygon clipping. Communications of the ACM 35(7), 56–64 (1992)],通过裁剪像素d来缩小文本区域。像素d的offset定义为: d = A ( 1 − r 2 ) / L d=A(1-r^2)/L d=A(1−r2)/L,A和L分别为代表文本区域的面积和周长,r为收缩率(本文设置为0.4)。下面是一个示例:

左:红色和绿色多边形分别是原始注释和收缩区域。
右:分段标签;黑色和白色分别表示0和1的值。
Proposal generation
给定一个文本分割图S,值的范围在[0,1]之间,然后首先将S二值化为二值图B:
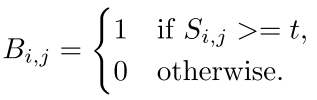
i和j是图的索引,t设置为0.5,得到的B是和S一样的size。
然后将B中的连接区域进行分组。这些连接区域可以被视为收缩文本区域,因为文本分段标签是收缩的,如3.1所述。因此,再使用Vatti剪裁算法通过取消剪裁像素来扩展它们为收缩前的区域,其中 d ^ \hat{d} d^计算为 d ^ = A ^ × r ^ / L ^ \hat{d}=\hat{A} × \hat{r}/\hat{L} d^=A^×r^/L^。这里, A ^ \hat{A} A^和 L ^ \hat{L} L^是预测的收缩文本区域的面积和周长。 r ^ \hat{r} r^对应于收缩率r的值设置为3.0.
Hard RoI masking
由于自定义RoI Align操作符只支持轴对齐的矩形边界框,因此本文使用多边形proposal的最小、轴对齐的矩形边界框来生成RoI特征,以保持RoI Align操作的简单性。
Qin等人将mask概率图与RoI特征相乘得到RoI mask,但它的mask概率图由mask rcnn生成,不够准确,一个proposal中可能包含多个文本实例。而本文的proposal是精确的多边形,所以可以通过Hard RoI masking从proposal提取RoI特征。
Hard RoI masking将二值多边形mask与RoI特征相乘以抑制背景噪音或相邻文本实例,其中多边形mask M表示轴对齐的矩形二值图,其中多边形区域中的所有值为1,多边形区域之外的所有值为0。
假设 R 0 R_0 R0是RoI特征,M是多边形mask,其尺寸为32×32,则masked RoI特征 R R R可以计算为 R = R 0 ∗ M R=R_0∗M R=R0∗M,其中 ∗ ∗ ∗表示按元素的乘法。通过在多边形proposal区域填充1,同时将多边形外部的值设置为0,可以轻松生成M。
通过使用masked RoI 特征抑制了背景区域或相邻文本实例,降低了检测和识别错误。
损失函数
SPN使用DICE Loss [Milletari, F., Navab, N., Ahmadi, S.A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: Int. Conf. on 3D Vision. pp. 565– 571 (2016)] ,DICE Loss讲解
假设S和G是分割图和目标图,则分割损失 L s L_s Ls可计算为:
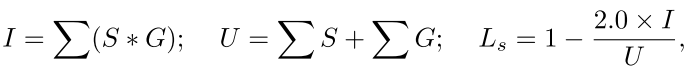
其中I和U表示两个映射的交集和并集,而*表示元素乘法。