Hadoop
Linux -> Hadoop -> HBase -> Spark
Hadoop分布式计算基础是什么?
1、存储
2、计算
电影评分数据统计分析实验
【项目目标】
1)掌握Hive的查询语句的使用
2)掌握R的可视化分析
【实验原理】
一、Hive支持多种不同长度的整型和浮点型数据类型,支持布尔类型,也支持无长度限制的字符串类型。
二、查询语句是所有数据库都包括的,并且很常用,所以需要熟练掌握。
三、R中的可视化非常漂亮,我们需要熟练使用。
【实验环境】
CentOS6.5、JDK1.7、Hadoop2.4.1、Hive0.12.0、R-3.2.2
【实验数据】
hot_movie
| 字段 | 定义 |
|---|---|
| m_id | (电影id) |
| score | (系统评分) |
| m_name | (电影名称) |
user_movie
| 字段 | 定义 |
|---|---|
| u_name | (用户昵称) |
| m_id | (电影id) |
| u_score | (用户评分) |
【实验步骤】
一、项目准备阶段
1.1在任意目录下运行start-all.sh.启动hadoop。如图1所示。
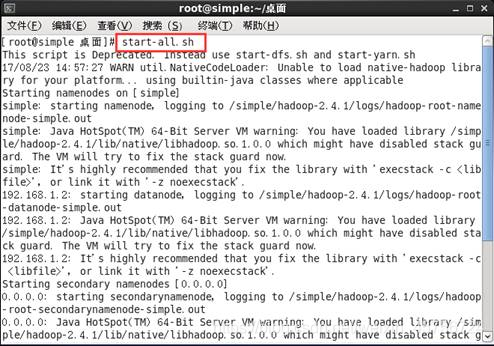
图1
1.2 输入jps检查是否启动成功。如图2所示。
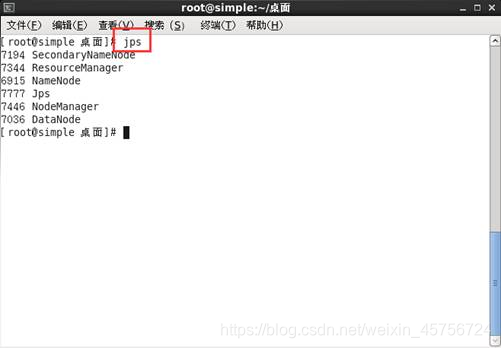
图2
1.3 进入hive下bin目录。如图3所示。
图3
二、数据分析以及数据准备
2.1 统计电影的系统评分,并查看结果。如图4-5所示。
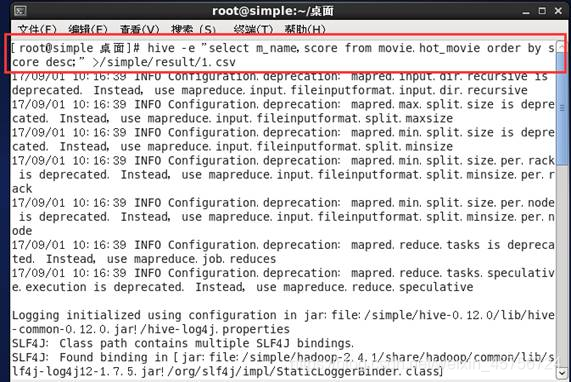
图4
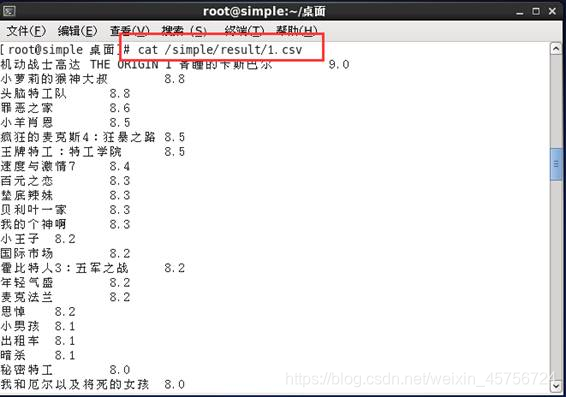
图5
2.2 统计一个电影被观看的次数。如图6-7所示。
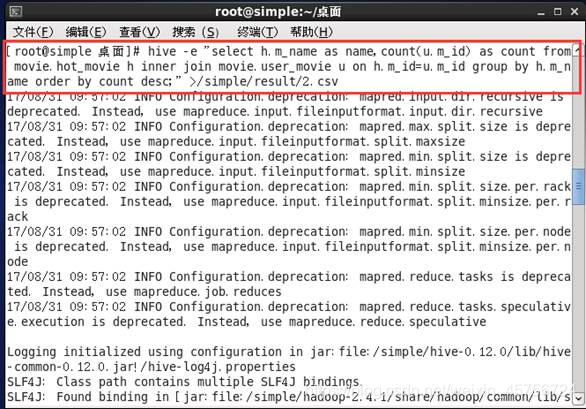
图6
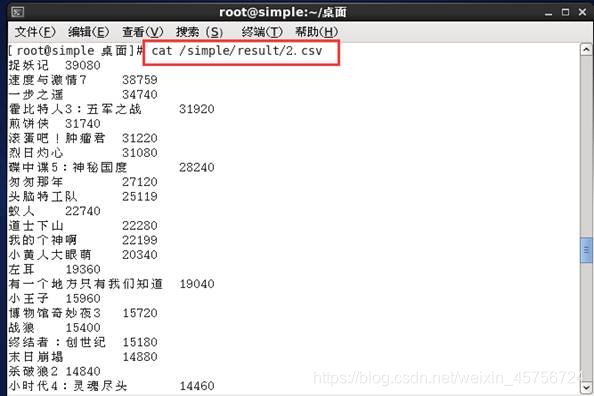
图7
2.3 统计前10名观众看电影的次数。如图8-9所示。
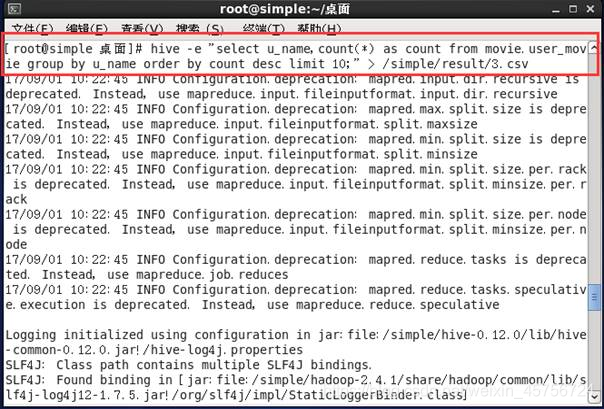
图8
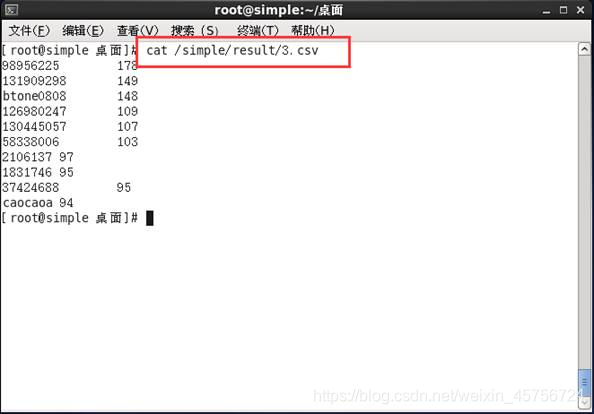
图9
三、R可视化
3.1 进入R命令行,并载入相关程序包,(程序包已安装完毕直接使用即可)。如图10-11所示。
图10
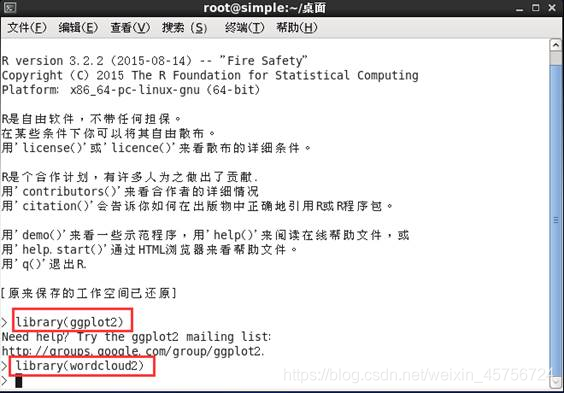
图11
3.2 画出系统电影评分的词云图。如图12-14所示。
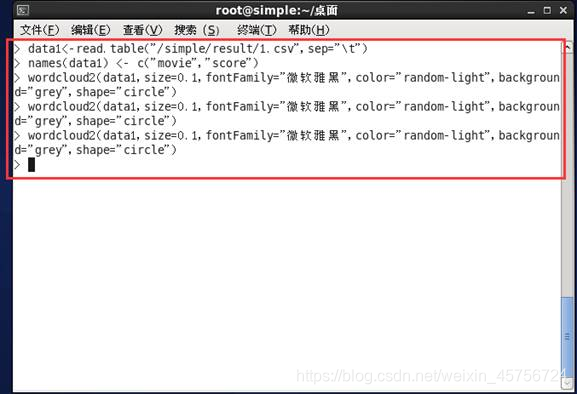
图12
第一次执行可能会像是这样,不要担心,别关闭浏览器,将程序的最后一句再执行一遍,就可以正常显示。
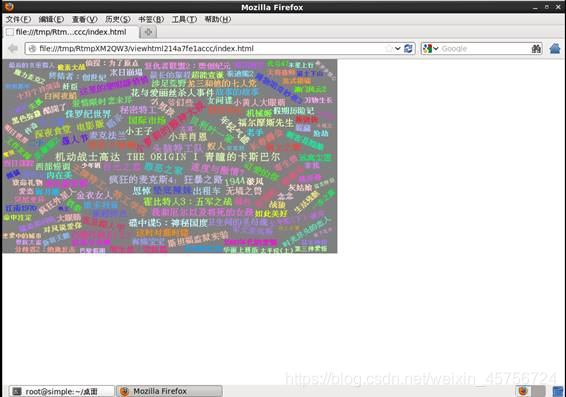
图13
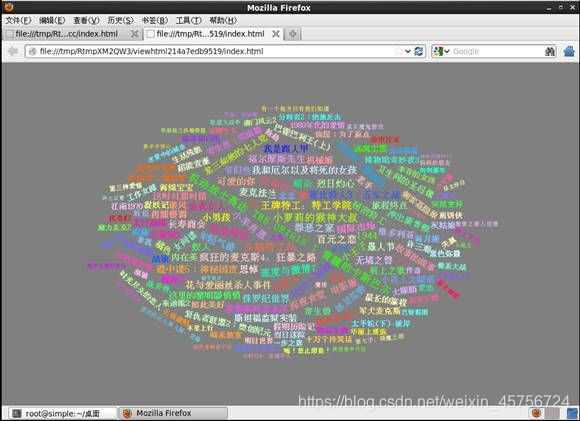
图14
3.3 画出每个电影观看次数的词云图,同样将程序的最后一句执行两遍。如图15-16所示。
图15
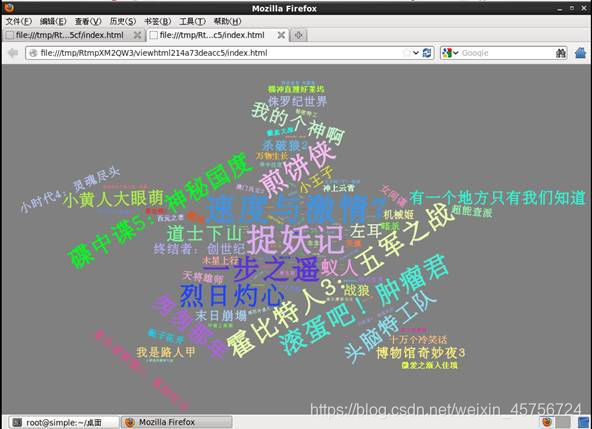
图16
3.4 画出前10名观众看电影的次数的条形图。如图17-18所示。
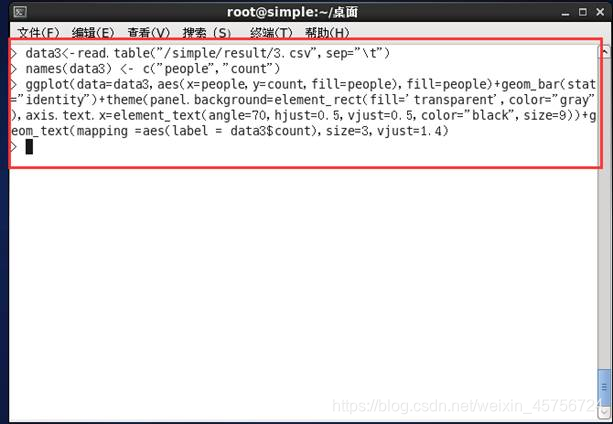
图17
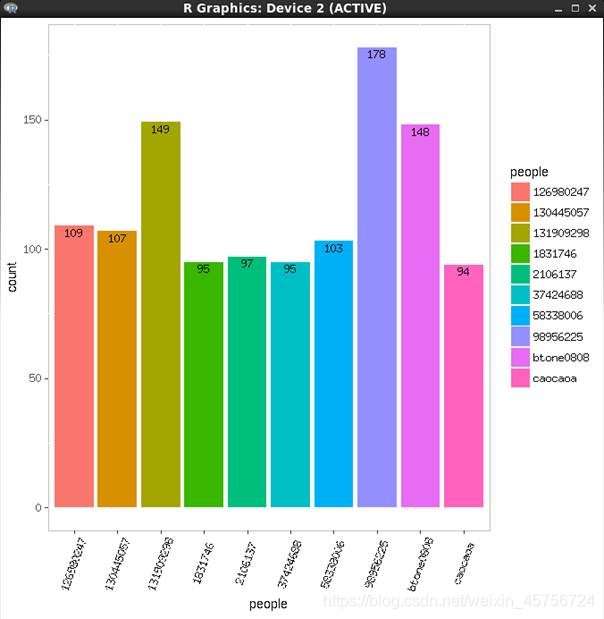
图18