《Hadoop大数据技术》测试试题
题 目: 基于hadoop豆瓣电影数据分析
学生姓名: 学 号:

学 院: 专业班级:
完成日期: 年 月 日
成绩(百分制):
授课教师:
| 试题题目:基于hadoop豆瓣电影数据分析 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 试题内容及要求 试题说明: 豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。 为了分析电影产业的发展趋势,你需要对这些信息做统计分析。 豆瓣网站的数据形式为文本文件(必须将导入到hive中做处理)。 文件的内容如下:
待分析指标如下: 1、什么类型的电影平均评分最高。 要求输出:类型 平均分 2、哪个国家是烂片之王(平均评分小于6分的国家)。 要求输出:国家 平均分 各项统计指标需要添加到hbase,以方便查询,分别添加到2个表(一个指标一个表),且在hbase shell中显示你写入的结果数据。 另外,本次操作需要留下日志,在hdfs 的 /log 下 上传自己的操作记录。 操作记录的格式为: 学号 姓名 操作时间 2019xx xxx 2020-12-21 10:52:12 试题说明:
列式数据库中有文件描述这个表,那么‘张三’同学的表应该命名为zs_201902003。
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 评分标准:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| 任务一: 操作过程:
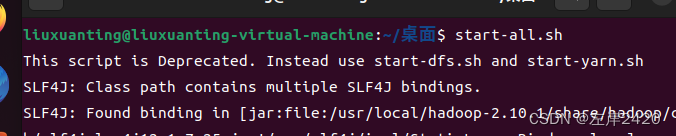
代码:start-all.sh
代码:hive;
3、将数据粘贴进主目录中
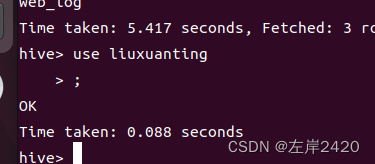
4、打开自己的数据库 代码:use liuxuanting;
5、新建一个表,表名为:lxt_2021900406 代码: create external table lxt_2021900406(id int,name string,people int,stype string,country string,atime string,timelong int,year int,score double,here string) row format delimited fields terminated by ','
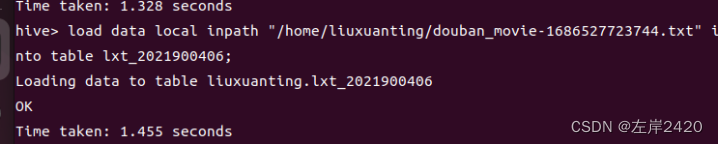
6、导入数据 代码:load data local inpath "/home/liuxuanting/douban_movie-1686527723744.txt" into table lxt_2021900406;
7、查看数据导入情况 代码:select * from lxt_2021900406;
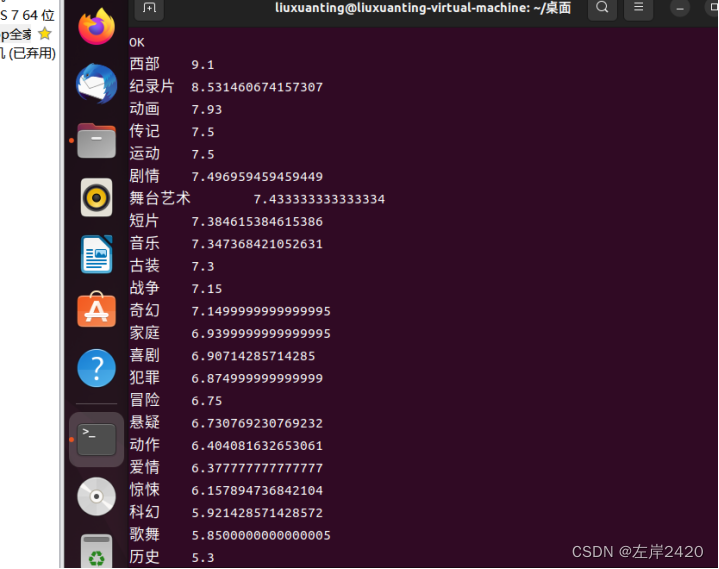
任务二: 1、什么类型的电影平均评分最高。 要求输出:类型 平均分 代码:SELECT stype,AVG(score) as scores FROM lxt_2021900406 GROUP BY stype order by scores DESC;
输出结果:
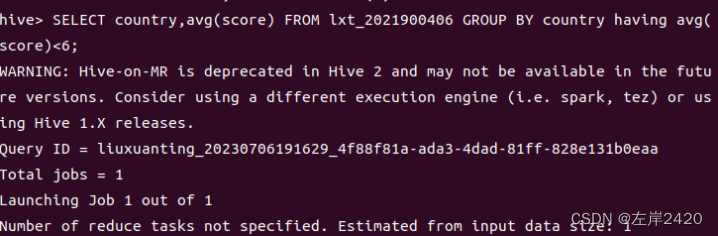
2、哪个国家是烂片之王(平均评分小于6分的国家)。 要求输出:国家 平均分 代码: SELECT country,avg(score) FROM lxt_2021900406 GROUP BY country having avg(score)<6;
输出结果:
任务三: 1、打开hbase 代码:start-hbase.sh
2、进入hbase shell 代码:hbase shell 3、在hbase中创建表lxt_2021900406 代码:creat 'lxt_2021900406','info'
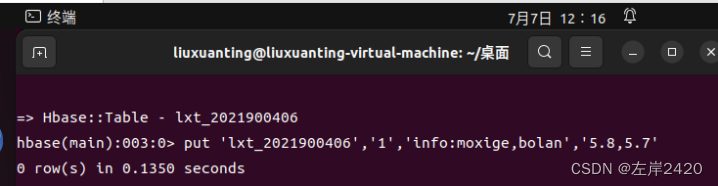
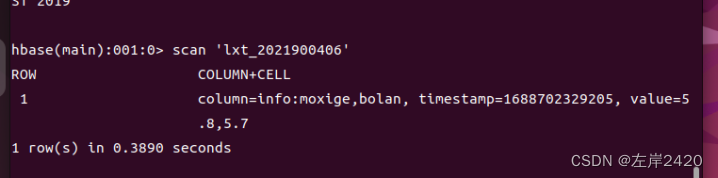
4、在表lxt_2021900406中手动插入数据 代码:put ‘lxt_2021900406’,’1’,’info:moxige,bolan’,’5.8,5.7’
5、查看hbase表的插入情况 代码:scan ‘lxt_2021900406’
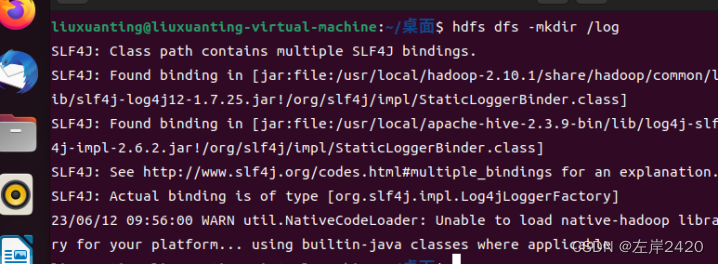
6、在hdfs中新建表/log 代码:hdfs dfs -mkdir /log
6、编辑日志 代码:vi liuxuanting1
7、上传操作日志在/log中 代码:hdfs dfs -copyFromLocal /home/liuxuanting/liuxuanting1 /log/
8、查看日志上传情况 代码:hdfs dfs -cat /log/liuxuanting1
|