1.缓存的引入
思考:
- 当在计算 RDD3 的时候如果出错了, 会怎么进行容错?
- 会再次计算 RDD1 和 RDD2 的整个链条, 假设 RDD1 和 RDD2 是通过比较昂贵的操作得来的, 有没有什么办法减少这种开销?

在上述两个问题的情况下就引入了RDD缓存机制.(目的是为了提高计算性能以及容错).
2. 缓存的分类
简介:RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
-
1)Cache
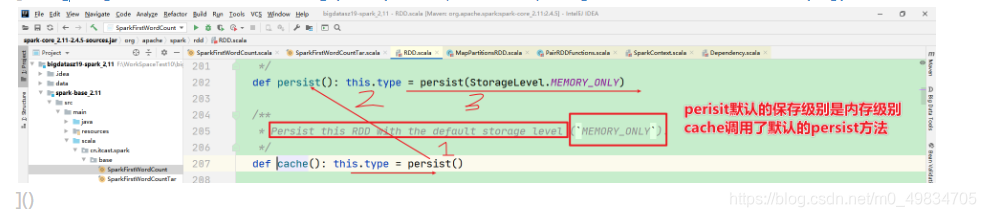
-2) Persist
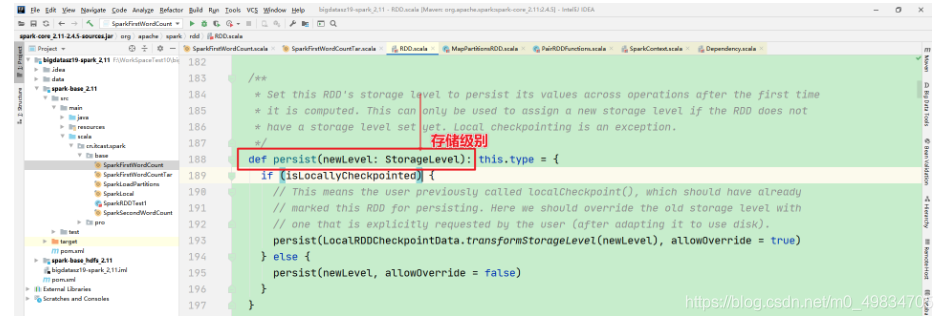
-
缓存的几种形式 源码
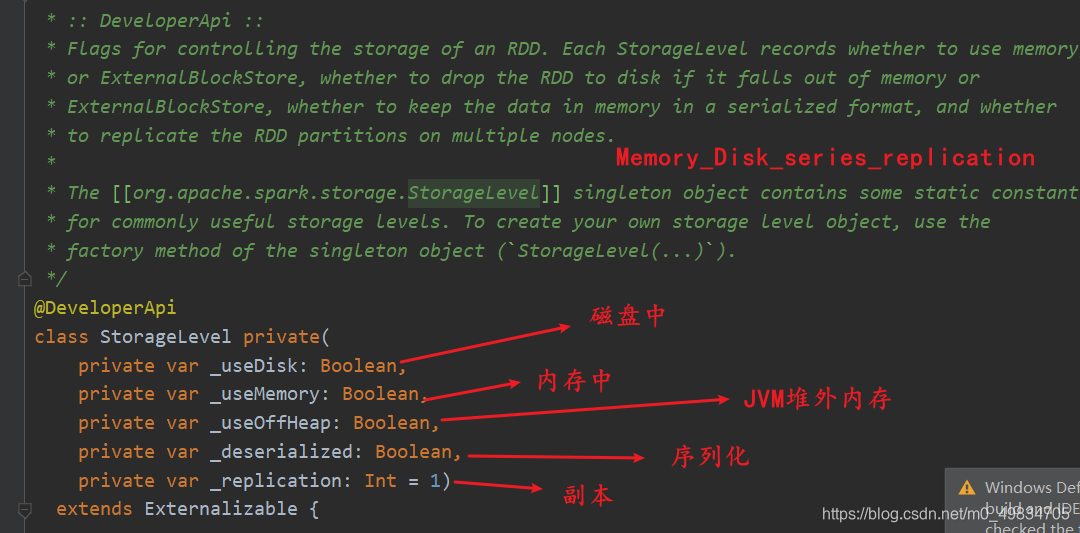
-
RDD缓存级别源码
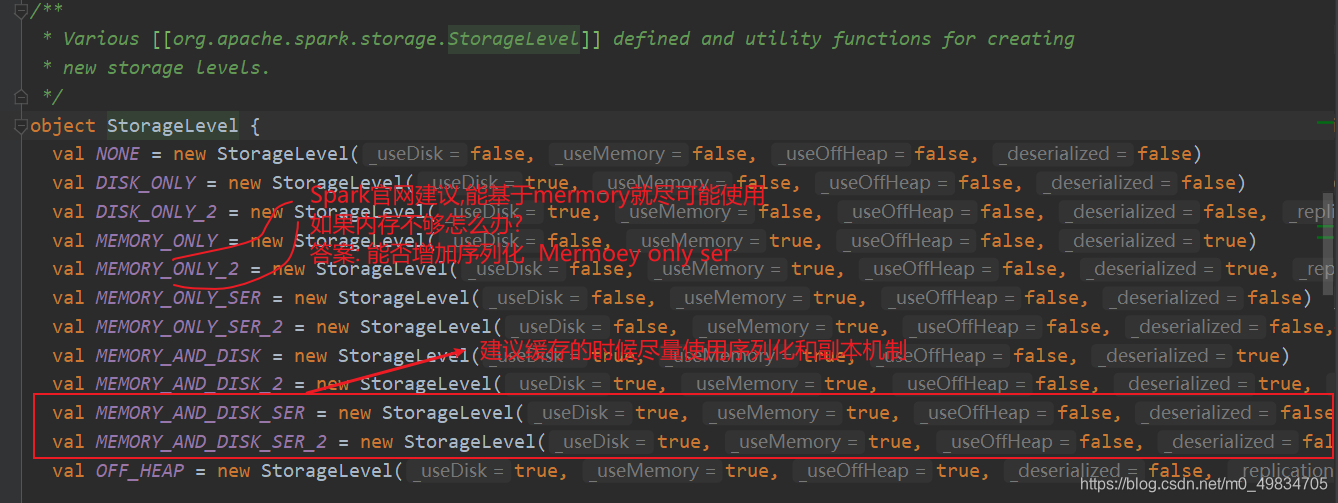

- 注意事项,如何选择分区级别
-
Spark 的存储级别的选择,核心问题是在 memory 内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择:
-
如果您的 RDD 适合于默认存储级别(MEMORY_ONLY),leave them that way。这是 CPU 效率最高的选项,允许 RDD 上的操作尽可能快地运行.
-
如果不是,试着使用 MEMORY_ONLY_SER 和 selecting a fast serialization library 以使对象更加节省空间,但仍然能够快速访问。(Java和Scala)
-
不要溢出到磁盘,除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
-
如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用 Spark 来服务 来自网络应用程序的请求)。All 存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在 RDD 上运行任务,而无需等待重新计算一个丢失的分区.
3. 关于RDD缓存的总结:
-
1-什么是缓存?— 需要将算子缓存内存或磁盘中
-
2-Spark设计的目的?---- 加快计算速度。实现容错机制
-
3-缓存分为哪些?cache,persist,cache底层调用的是persist的默认memoryonly的方法
-
4-官网中建议如何使用缓存?
- 1-尽可能缓存在内存中
- 2–如果内存放不下,尽可能实现序列化
- 3-除非计算算子非常昂贵,否则不要放到磁盘中
- 4-实现容错,需要副本机制
-
5-移除缓存的数据
- 1-Spark内部采用LRU机制自动移除不用的缓存
- 2-自己通过rdd.unPerist移除
-
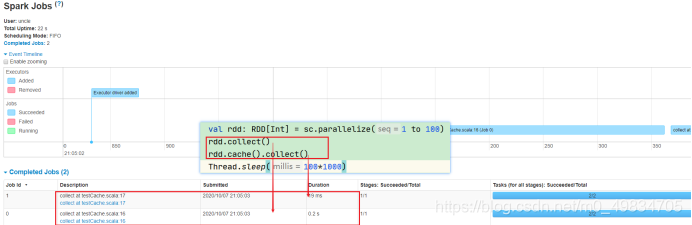
实验:
/**
* @author liu a fu
* @date 2021/1/14 0014 22:42
* @version 1.0
*/
object SparkTest1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(1 to 100)
rdd1.collect()
rdd1.cache().collect()
//reduceRDD.persist()
rdd1.unpersist()
Thread.sleep(100*1000)
sc.stop()
}
}
加了缓存时间明细缩短
4. RDD缓存的问题
- 1-如果将缓存数据存在易失的介质中,存在数据丢失的问题
- 2-RDD的缓存是通过将RDD的依赖链保存起来实现容错恢复,如果因为缓存的数据存储易失的介质,可能整个rdd的chain也会丢失