简介:
- RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的(内存意失);也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
- Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
RDD的查点机制:
-
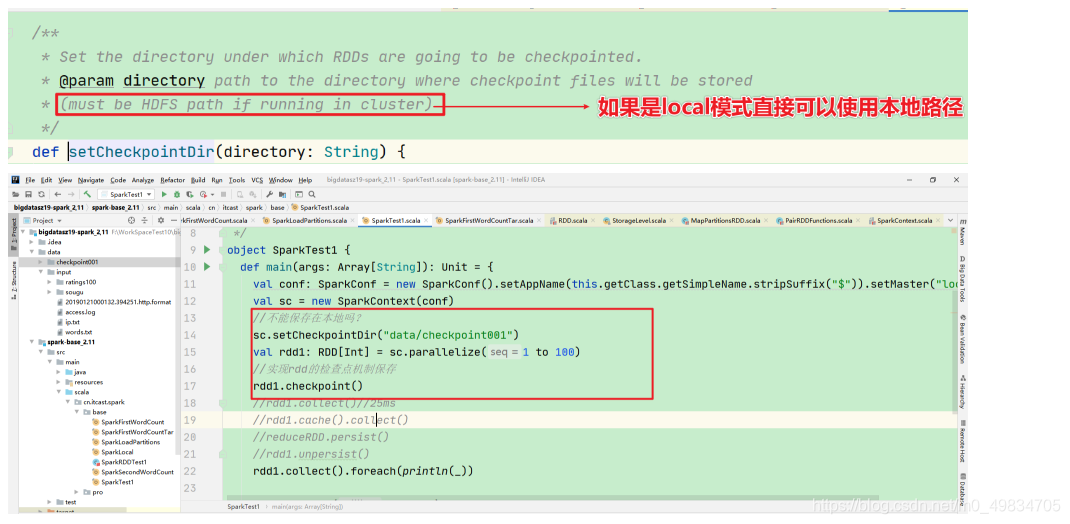
1-什么是检查点机制
- 就是使用CheckPoint将数据保存在HDFS等非易失的介质中
-
2-检查点机制实现的目的是什么
- 就是为了解决RDD缓存在易失的介质中无法保证数据的安全性,这里通过Checkpoint检查点机制将数据保存在HDFS中,就可以借助HDFS的高容错和高可靠性实现检查点机制
-
3-如何使用检查点机制
- sc.checkPoint(“hdfs的路径”)
-
4-检查点机制和RDD的缓存有什么区别和联系?

-
5-注意:
Spark如何实现容错机制? -
(1)首先Spark会查找内存中是否会有RDD进行cache或persist,如果没有继续
-
(2)继续查找Spark中是否设置CheckPoint检查点机制
-
(3)根据RDD的血缘或依赖关系重新计算