提示:完整代码附在文末
一、需要的库
requests:获得网页请求
BeautifulSoup:处理数据,获得所需要的资料
二、爬取豆瓣电影Top250
爬取内容为:豆瓣评分前二百五位电影的名字、主演、以及该电影的简介。
首先先进入豆瓣电影Top250,打开审查元素,找到所要爬取的电影名、主演以及电影主页的链接都在标签<div class="info">中间,如下图所示
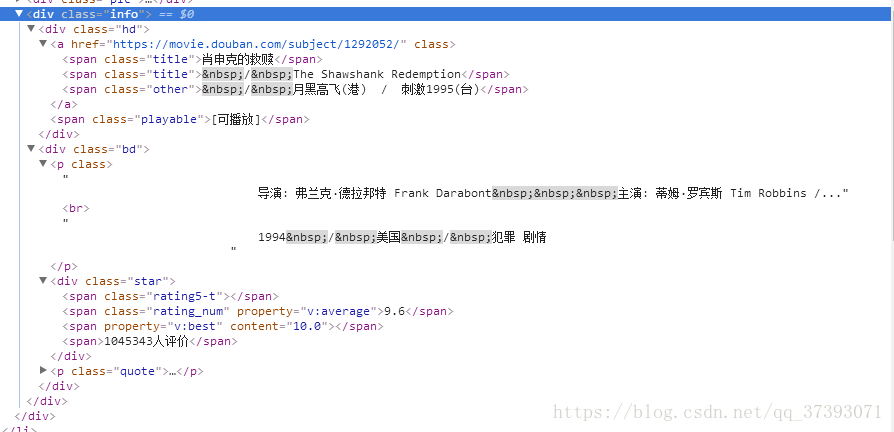
对于电影名和导演主演这些信息是可以直接获取的:

content_list中包含所有标签为<div class="info">的内容。
对于电影简介,则需要先进入该电影界面,再获取。而进入电影主页的链接就保存在div下第一个a标签的‘href’属性中,获取方法如下:
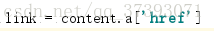
得到link之后,获取link内容,因为Top250中存在链接打不开的现象,所以我加了一个if语句,过滤掉无效的link。手动打开任意一个link,从审查元素中定位电影简介的位置,得知信息保存在<span property="v:summary">中,获取信息。

三、数据保存
我这里创建里一个文件夹,以每个电影名命名建立各自的TXT文件写入title、star、summary。

四、总结
这个实践时比较基础的,但在其中也发现了BeautifulSoup库定位时还是比较麻烦的,新手理解很快,但在实践中还是需要眼力的。
完整代码:
#encoding=utf-8
import bs4
from bs4 import BeautifulSoup
import requests
import os
def get_html(url):
try:
header = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"}
r = requests.get(url,timeout = 30,headers=header)
r.raise_for_status()
print(r.text)
return r.text
except :
return "error"
def print_content(html):
soup = BeautifulSoup(html,'html.parser')
content_list = soup.find_all('div',attrs={'class':'info'})
#os.mkdir(path)
print(type(content_list))
print(len(content_list))
for content in content_list:
title = content.find('span').text
star = content.find('p').text.replace(' ','').replace(' ','')
link = content.a['href']
title = content.find('span').text
print(link)
print(title)
html = get_html(link)
if(html != "error"):
soup = BeautifulSoup(html,'lxml')
summary = soup.find('span',{'property':'v:summary'}).text.replace(' ','')
#print(summary)
else:
print("None")
fpath = path + "\\" + title+".txt"
with open(fpath,'w',encoding="utf-8") as f:
f.write(title)
f.write(star)
f.write(summary)
f.close()
i =0
while i<250:
path = "E:\\Compile Tools\\python\\写的程序放在这里\\moive"
url = "https://movie.douban.com/top250?start="+str(i)
html = get_html(url)
print_content(html)
i = i+25