python拥有强大的requests库和BeautifulSoup库,通过这两个库就可以对网站数据进行简单的爬取。最近刚自学了一些简单的爬虫知识,下面我将以豆瓣电影榜top250 (https://movie.douban.com/top250)为例子来爬取一些数据。
(一) 观察网页的构成
1. 首先我们用浏览器打开网站(https://movie.douban.com/top250),找到开发者工具,由于我用的是谷歌浏览器,直接快捷键shift+ctrl+i直接打开开发者工具,我也推荐大家使用谷歌浏览器,我觉得还是比较好用的。
下载地址:http://wie.rwbzx.com/
2. 打开开发者工具后,点击右上角的元素审查按钮。

3. 点了它之后,然后将移动到网页中任意内容上并点击,开发者工具会自动找到并点亮该内容对应的 HTML 代码。这个功能可以方便我们找到想要爬取的 HTML 代码。由于我们需要的数据是电影名及其对应网址,所以先点击第一部电影名:肖申克的救赎。我们可以发现它的电影名和网址都包含在一个class='td’的div下,网址和电影名又分别包含于该div下的元素a和第一个class='title’的span中。
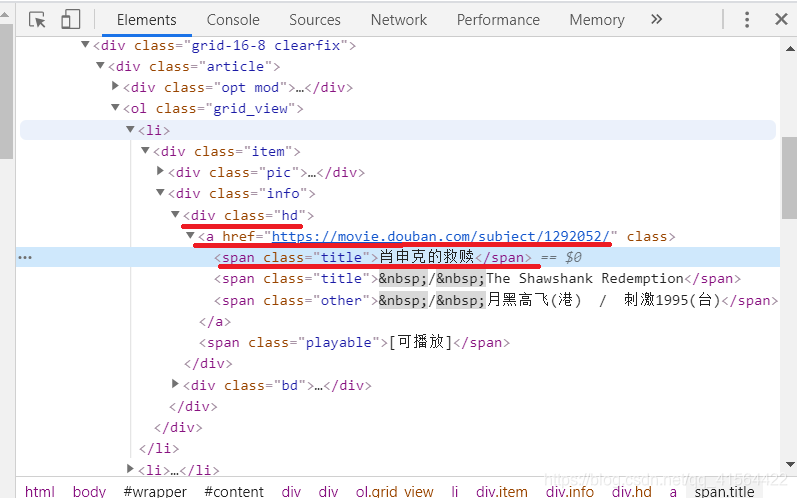
4. 重复上述步骤观察其他的电影名字,我们可以发现,都是一样的,这下我们就完成了前期的观察工作了。
(二) 对单个网页进行爬取
在完成了对网站代码的观察后,我们就开始正式进行对数据的爬取,爬取数据时我们要用到python的requests库和BeautifulSoup库,我用的IDE是pycharm,大家如果有对关于requests库和BeautifulSoup库导入问题的可以参考我上一篇博客。下面是对单个网页进行爬取的代码。
import requests
from bs4 import BeautifulSoup
# 设置反爬虫的请求头
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 请求网站的连接
res = requests.get('https://movie.douban.com/top250', headers=headers)
# 将网站数据存到BeautifulSoup对象中
soup = BeautifulSoup(res.text, 'html.parser')
# 爬取网站中所有标签为'div',并且class='pl2'的数据存到Tag对象中
items = soup.find_all('div', class_='hd')
for i in items:
# 再筛选出所有标签为a的数据
tag = i.find('a')
# 只读取第一个class='title'作为电影名
name = tag.find(class_='title').text
# 爬取书名对应的网址
link = tag['href']
print(name, link)
(三) 对整个网站进行爬取
上面代码只可以对单个页面进行爬取,要想对整个网站进行爬取的话,我们还得返回豆瓣电影榜top250(https://movie.douban.com/top250)的主页,再观察一次,我们发现整个页面共有25部电影,它一共分为10页,于是我们点击第二页,第三页…我们发现网址变化了。


红色的部分是变化的部分,而我们发现第二页跟主页的网址相比多了
?start=25&filter= 这个部分,这个部分叫查询字符串,这里我们可以把它理解为一个特殊的标签,每个子页都对应一个特定的标签。
通过依次点开第二页,第三页,第四页…我们发现这个查询字符串只有start=后面的值在改变,并且是每次增加25改变的,而这个25正好就是我们每页的电影数目,于是我们可以总结得出: start= 后面的值 等于 25 * (页码数-1)。得到这个结论后,我们就可以开始爬取整个网站了。以下是全部代码:
import requests
import time
from bs4 import BeautifulSoup
# 将获取豆瓣电影数据的代码封装成函数
def get_douban_movie(url):
# 设置反爬虫的请求头
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 请求网站的连接
res = requests.get('https://movie.douban.com/top250', headers=headers)
# 将网站数据存到BeautifulSoup对象中
soup = BeautifulSoup(res.text,'html.parser')
# 爬取网站中所有标签为'div',并且class='pl2'的数据存到Tag对象中
items = soup.find_all('div', class_='hd')
for i in items:
# 再筛选出所有标签为a的数据
tag = i.find('a')
# 只读取第一个class='title'作为电影名
name = tag.find(class_='title').text
# 爬取书名对应的网址
link = tag['href']
print(name,link)
url = 'https://movie.douban.com/top250?start={}&filter='
# 将所有网址信息存到列表中
urls = [url.format(num*25) for num in range(10)]
for item in urls:
get_douban_movie(item)
# 暂停 1 秒防止访问太快被封
time.sleep(1)
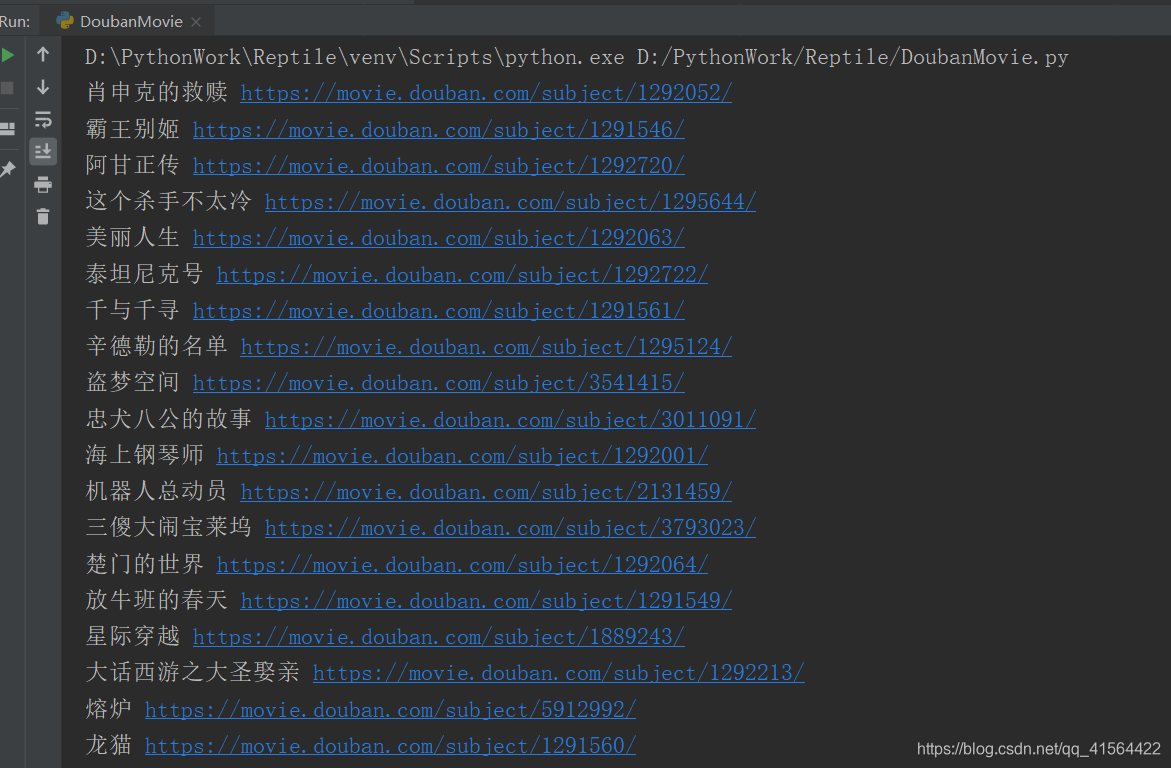
附上部分运行结果:
以上便是所有的代码与主要步骤,希望能对大家有所帮助,谢谢!
