2.1 为什么要进行实例探究
在上一周,我们已经学习了组成神经网络模型的基础构件,如卷积层、池化层、全连接层等内容。本节课主要介绍在计算机视觉领域近些年发展过程中积累的优秀实例,通过实例能够了解学习如何对基础的构件进行组合。从而在以后自己做计算机
视觉相关任务时能够有所启发。
网络总览:
经典的网络模型:
- LeNet-5
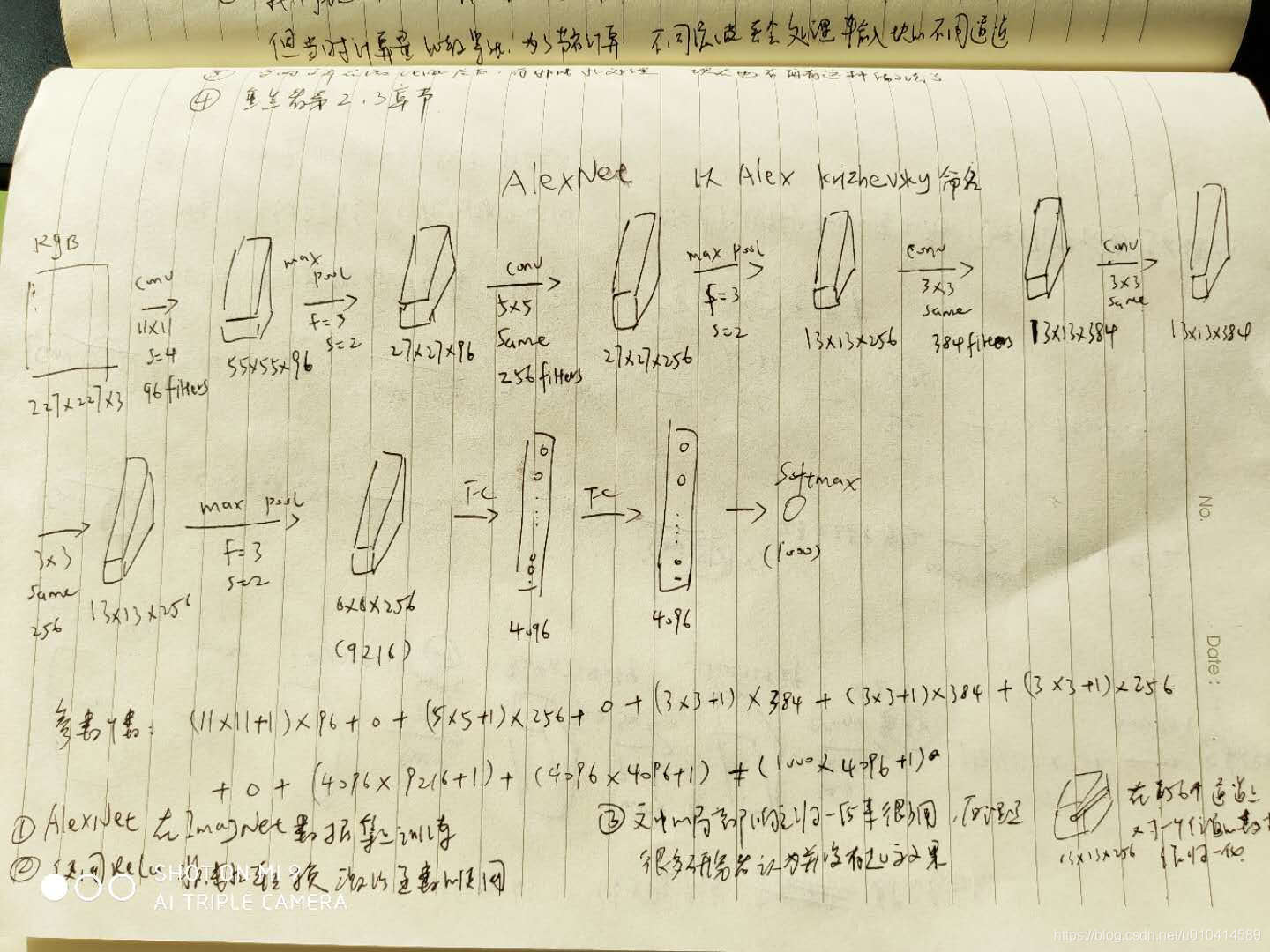
- AlexNet
- VGG
卷积残差网络:
- ResNet (152层的神经网络)
2.2 经典网络


2.3 残差网络
太深的神经网络训练起来很难,因为有梯度消失和爆炸这类问题。
在本节课中,我们将学习到跳跃连接(skip connection),它能让你从一层中得到激活,并突然将它传递给下一层,甚至更甚的神经网络层。利用它,可以训练网络层很深很深的残差网络(ResNet)。
残差网络是利用了残差结构的网络。

2.4 残差网络为什么有用?
在之前的课程中介绍到,如果我们设计了更深层的网络,它会使得你用训练集训练神经网络的能力下降。这也是为什么有时你不希望有太深的神经网络。
ResNet 与之不同,下面看一个例子

下面是论文图例,展示ResNet 和 Plain 的区别
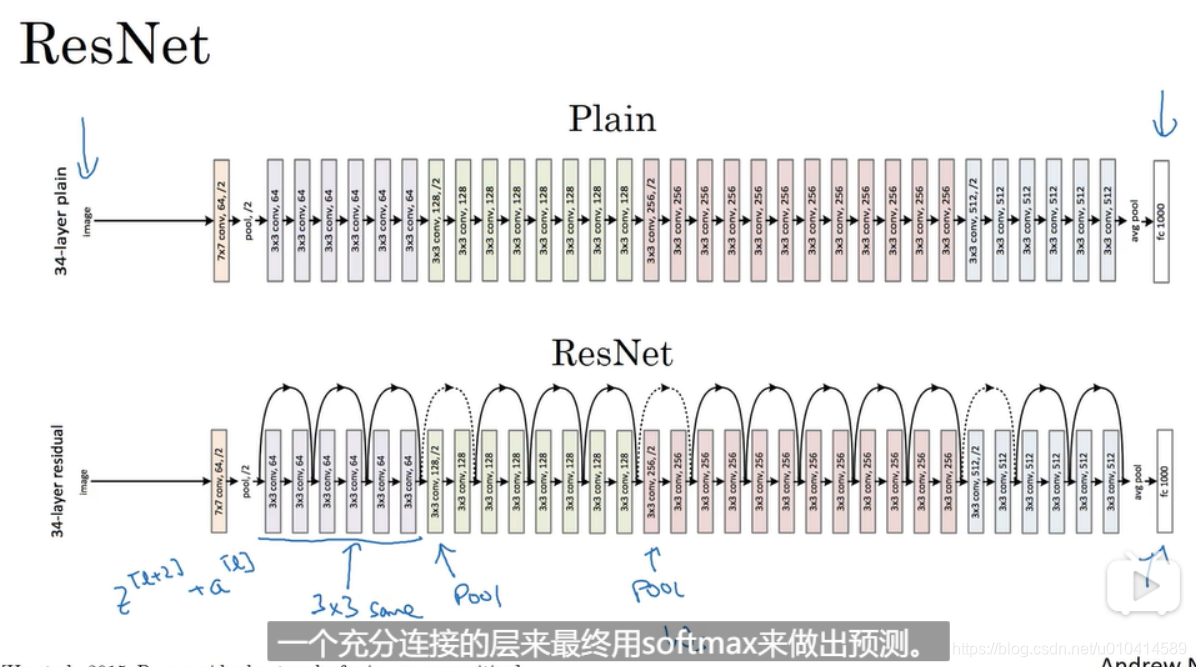
这里值得注意的是,ResNet 中使用到很多填充方式为same的3*3的过滤器,这样能使得输出后的维度和输入前的维度一致,更有利于残差块中的计算。对于维度不同的地方,需要使用ws矩阵去与a[l]相乘,来进行维度调整。
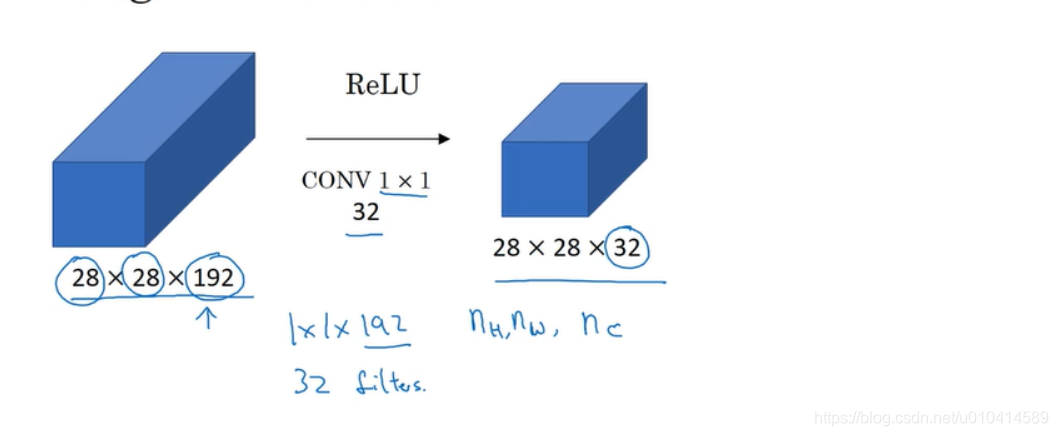
2.5 网络的1*1 卷积
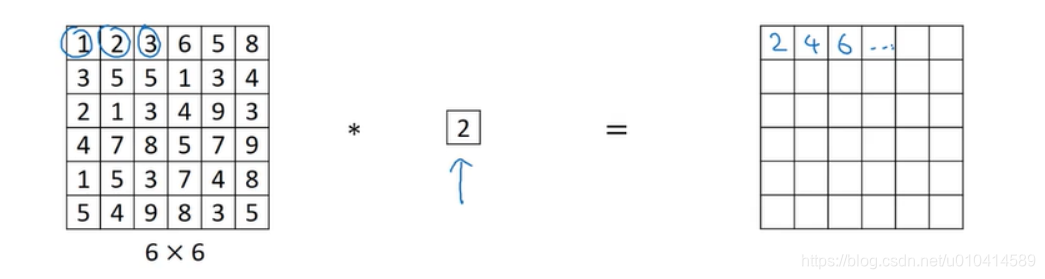
在设计网络架构时,一种很有用的想法是用1*1卷积。
对于一个通道为1的来说,没什么作用,就是把原来的输入乘以了某个数字。
对于多通道的输入来说,可以理解为接收同一高度和同一宽度下不同通道的输入值,分别与1*1过滤器中对应通道的值相乘,然后将ReLU作用于它,输出结果。
同时因为有多个过滤器,意味着你有不止一个单元,而是多个单元在接受输入图像中一面中的所有数作为输入。
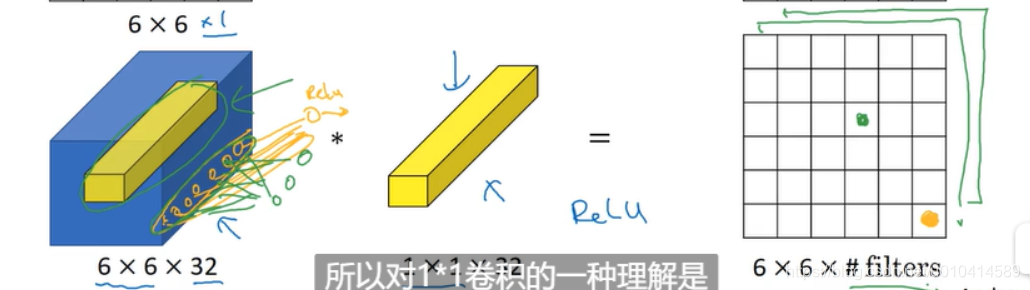
所以对1*1的卷积,本质上是一个完全连接的神经网络。
举一个1*1卷积的应用例子:
如果我们打算对输入数据的宽度和高度进行调整,可以通过一层池化层来解决。
如果我们觉得通道数过大,想缩小它,可以使用1*1的卷积。
2.6 谷歌 Inception 网络简介
为卷积网络设计某一层时,您可能需要选择11的卷积核、或者33的卷积核、5*5的卷积核,又或者需要一个池化层,谷歌Inception 网络就是指构造复杂的网络结构,将各种层都用上,这样的效果也很好。
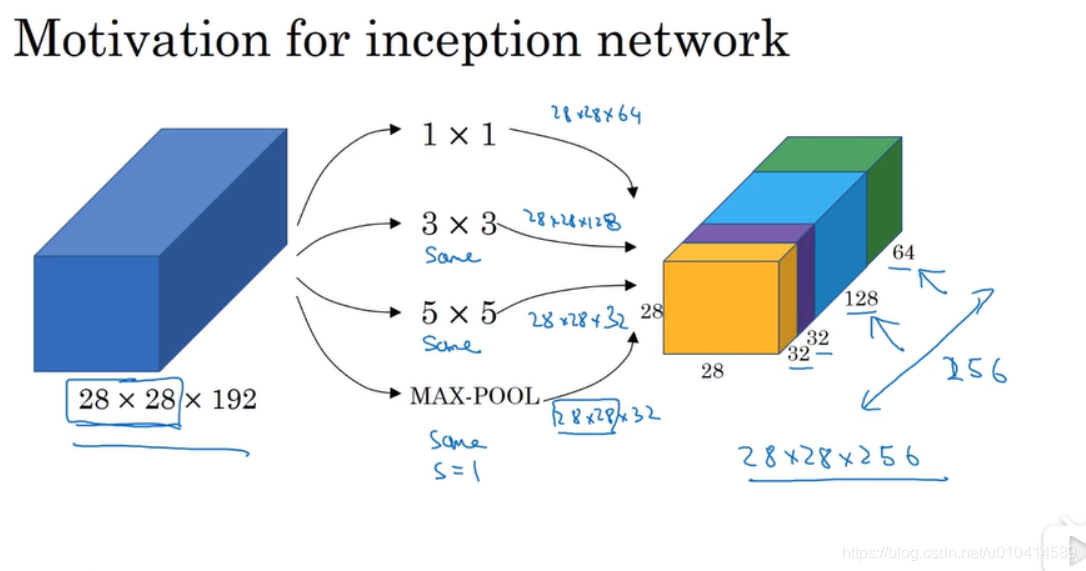
以上就是Inception 网络的核心,它使用到了11、33、5*5的卷积核,同时也使用到了最大池化。这里需要注意的是为了保证输出的宽和高的维度相同,在使用卷积或者池化过程中,都需要使用填充操作。
这样的一个优点就是我们不用再选择使用哪一种卷积核,而是交给神经网络自己去学习每一个卷积核的参数。
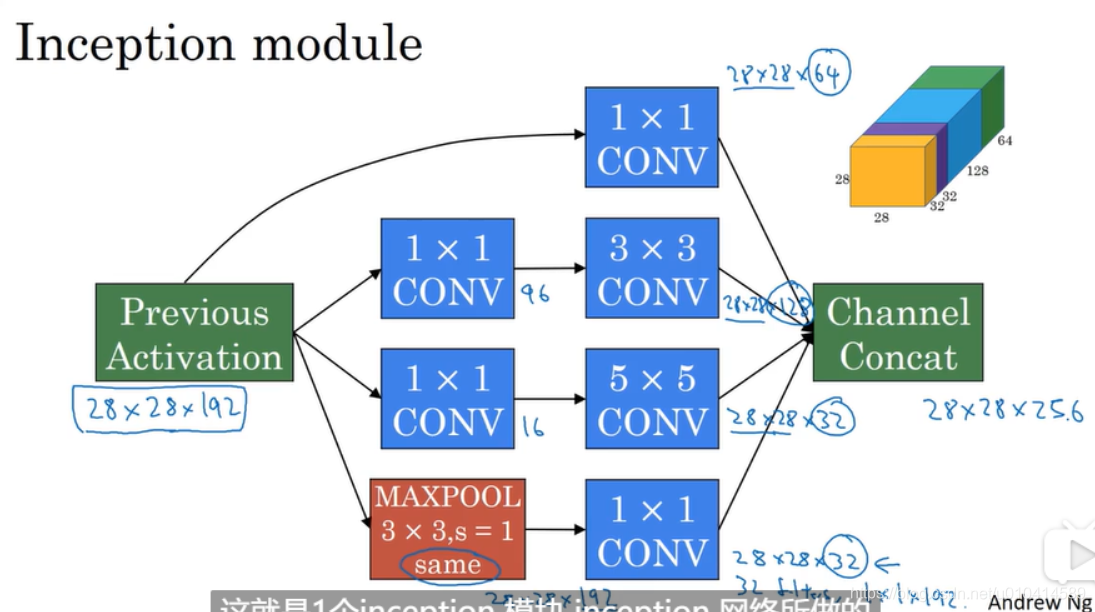
下面我们关注下Inception 中计算成本,我们以其中的5*5的卷积核来计算:

如此剧烈的缩小特征表示的大小,会不会影响神经网络的性能?答案是只要合理的设计这个瓶颈层,就既能够缩小输入张量的维度,又能够不影响神经网络的性能,同时也减少了计算成本。
2.7 Inception 网络
和上一节介绍的那样,为了减少计算成本,增加了一个11的卷积层作为瓶颈层。
在最大池化层后面为了缩小宽和高的维度,也增加了一个11的卷积层。
最后做了一个通道的连接。
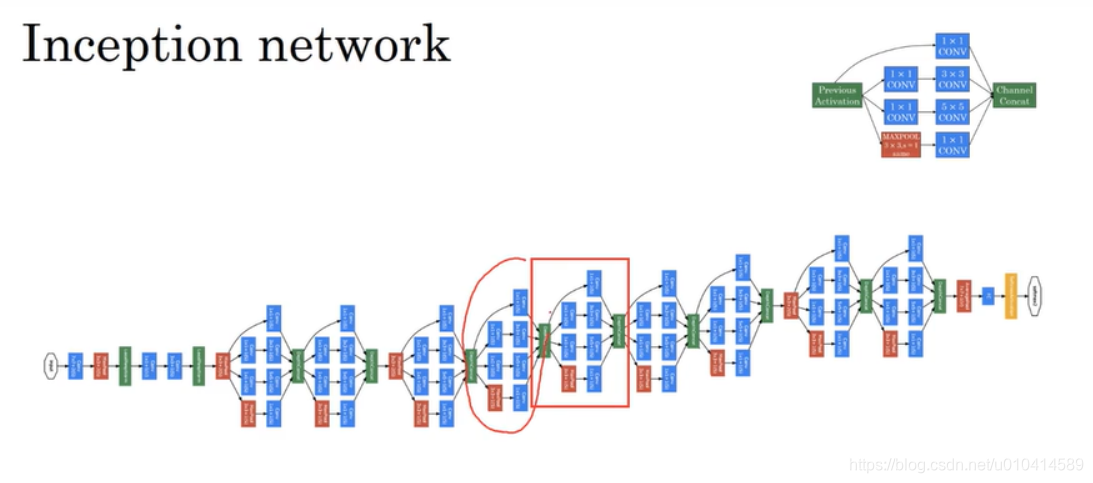
这里是Incepetion network 主要的网络结构,这里可以看到使用了很多重复的Inception模块。同时为了缩小宽和高的维度,也在Inception模块之间加了最大池化层。网络最后是全连接层,和softmax输出层。
这个网络是Google工程师开发的,称之为GoogleNet.
2.8 使用开源的实现方案
如果看到一篇论文想进行复现,可以先在开源社区查找是否有相关的实现。
2.9 迁移学习
如果想训练一个计算机视觉项目,而不想从零开始训练权重,最好的方式是下载已经训练好的网络结构,把它作为预训练。
迁移到你感兴趣的新任务上。
可以利用别人已经训练好的权重(这些可能是别人使用很多GPU经过很长时间,并经过不断调试得到的模型),为自己的神经网络做一个好的初始化开端。
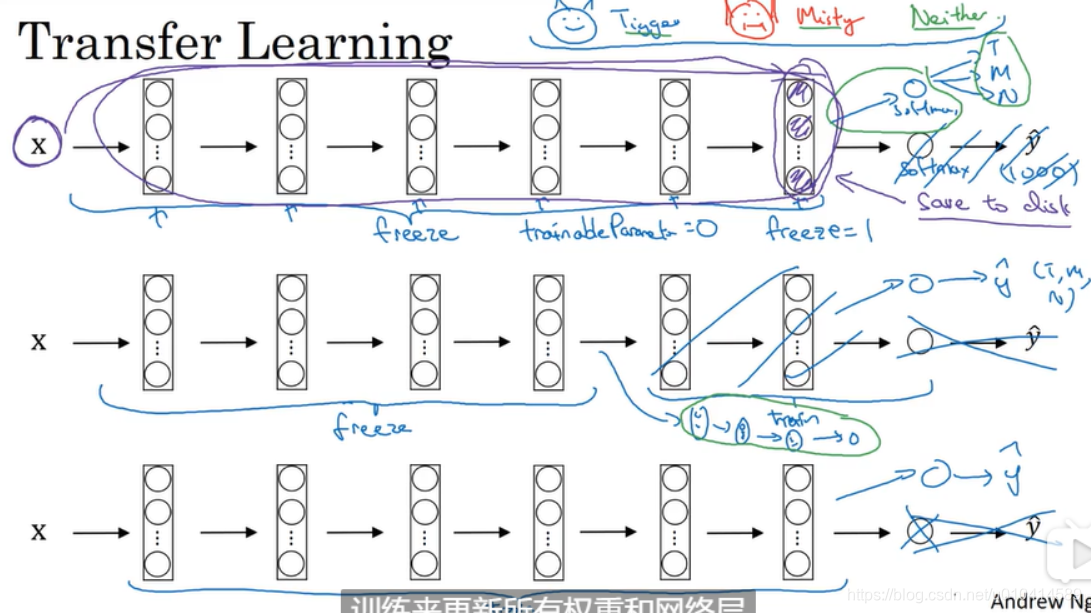
当自身数据集比较少时,选择冻结softmax 前面的所有层,也即冻结前面层的权重。修改softmax 层,修改为符合自己类别的输出层,然后只训练与自己softmax层的参数。
同时一个技巧是由于前面的层和权重都冻结了,所以为了避免每次迭代都需要计算从输入到中间每层的计算,可以把所有样本从输入到冻结的最后一层这个过程的输出提前计算出来,保存下来。以后再每次都可以直接使用。这样就会提高训练速度。
如果你的数据集更大,一个经验之谈是可以冻结较少的层, 然后接下来有几种方式:一种方式是使用原有的权重作为初始化,然后继续训练自己的权重;另一个方式是去掉原有的层,重新用自己的网络层和softmax输出。
最后,假如你有足够多的数据和GPU资源,你可以用原有权重来初始化整个网络并开始训练。训练来更新所有的权重和网络层。
2.10 数据扩充
计算机视觉常见的数据增强方法:
1. 垂直镜像
2. 随机裁剪
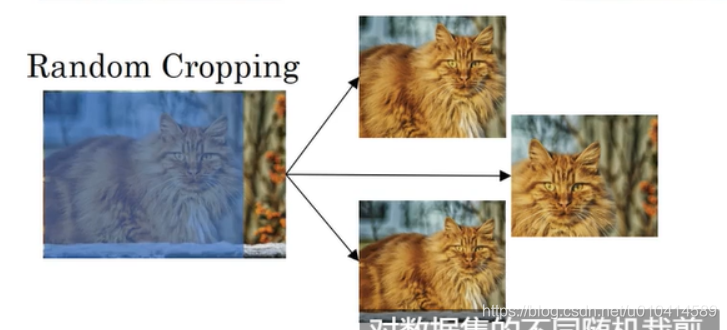
对数据集的不同随机裁剪,注意随机裁剪的大小要占原图较大的部分,不然可能会存在完全看不出特定物体的特征。
垂直镜像和随机裁剪在实际中比较常用,还有一些方式比如旋转、剪切、局部扭曲等也可以实现数据增强,但实际使用相对较少。
3. 色彩变化
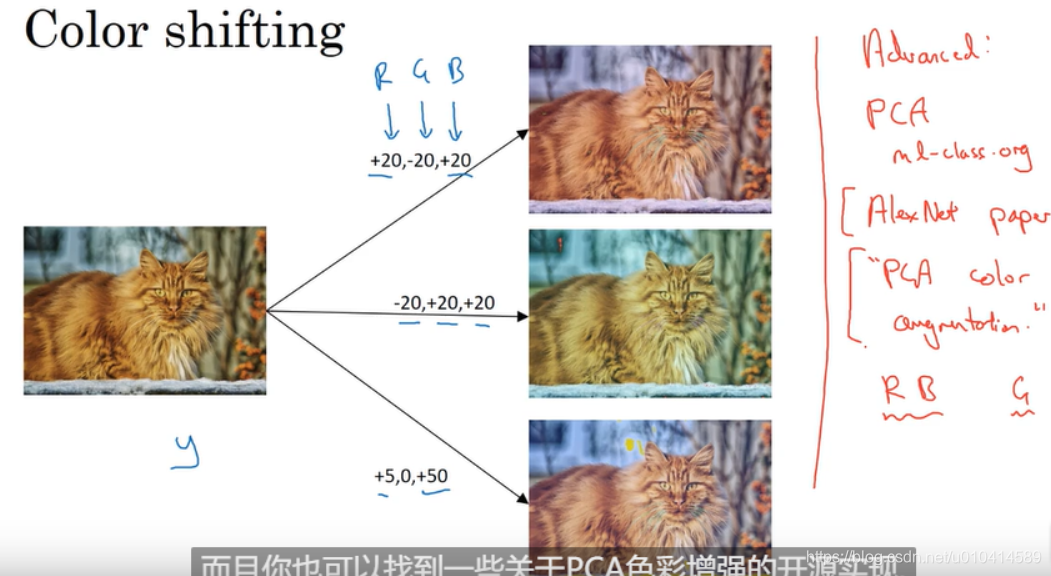
在三个通道上加入不同的扰动,这里样例中为了让大家能看清,设置的扰动值比较大,实际上都会小。
通过色彩变化,可以让学习算法在应用图像色彩变化时健壮性更好。
这里着重提一下PCA数据增强,在AlexNet 中有关于此算法的细节。
总结:
数据增强也有超参数,比如实现多大程度的色彩变化、用什么参数来做随机裁剪等。
一个有效的方式是直接用其他人用到的数据增强的开源实现,作为一个很好的开始。