4.1 人脸识别
人脸识别通常是指人脸校验和人脸识别。
人脸校验是指输入一张图像和一个人的ID,输出是这个图像是不是这个人。
人脸识别是有一个K个人的数据库,输入一张图像,如果这个图像属于K个人中的一个,输出他的ID。

4.2 One-shot 学习
人脸识别的挑战之一是你需要解决单样本学习问题。
也即是说对于大多数人脸识别的应用,需要在只见过一次照片或一个人的脸部的前提下识别出这个人。
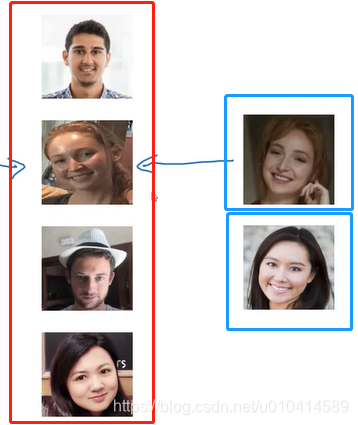
举个例子:
左侧是数据库中已有的四个人,我们希望再输入一个已存在的人,能够识别出是数据库中的哪个人。而输入数据库中不存在的人,则识别出不是数据库中四个人中任一个。
因此在单样本学习中,我们必须从一个样本中学习,就可以做到认出这个人。(大多数人脸识别系统都需要做到这样的能力,因为可能数据库中只有一张员工的照片。)
一种尝试的方式,是输入这个人的照片,经过卷积网络,然后通过5个类别的softmax,输出一个标签。
但这种通常效果不好,因为数据集太小,不足以训练出一个可以解决这个任务的足够鲁棒的神经网络。而且每当数据库中的员工增加或者减少时,还需要修改最后softmax层的输出个数,对模型进行重新训练。
因此,人脸校验是学习一个相似性函数,特别的,我们需要用一个神经网络来学习一个函数,

4.3 Siamese network
在上一节中,我们学习函数d 接收两张脸到的输入,并输出他们是多相似或者多不相似。
实现这个的一个好办法是siamese network 。
我们输入一张图像,经过卷积网络,得到一个128个数字组成的向量,看作是对输入图像的编码。
那么构建人脸识别系统的方法,如果你想比较两张图像,就分别把两张图像输入同一个网络,使用相同的参数,得到一个不同的128维的向量,也就是第二张图像的编码。
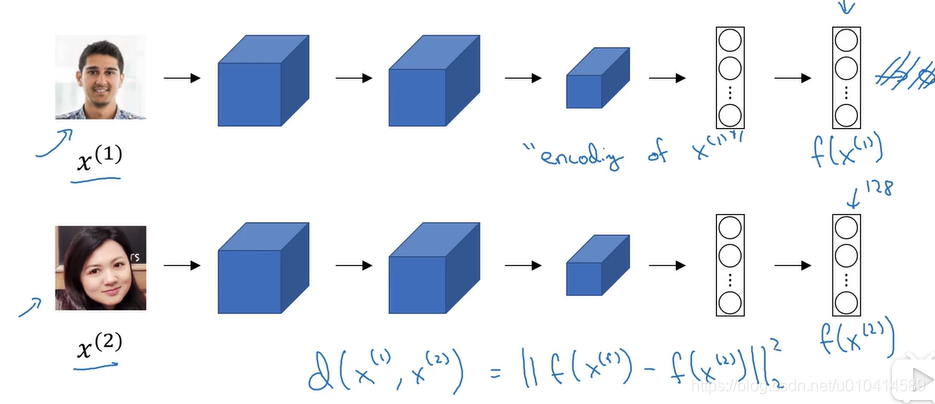
这种方法,用两个完全相同的卷积神经网络对两张不同的图像进行计算,然后比较两者的结果。我们称之为孪生网络架构。
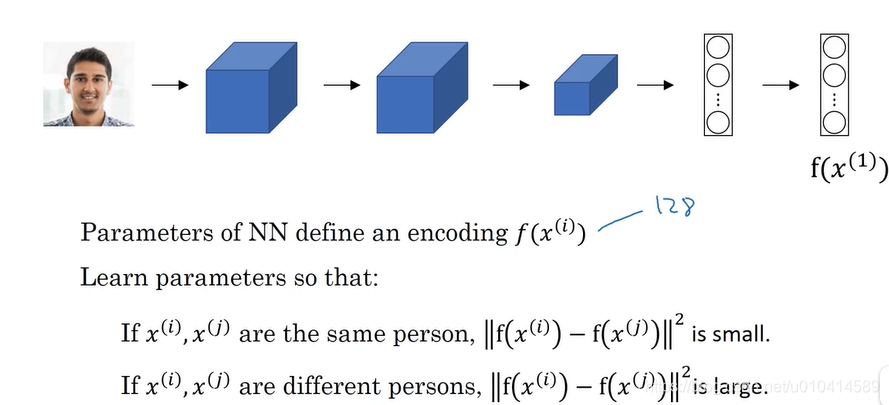
因此,我们说卷积神经网络的参数决定了图像的编码表达。
我们训练学习参数,目的是使得如果两张图像是一个人,那么两个编码表达的函数值很小;
如果两张图像不是一个人,那么两个编码表达的函数值很大。
我们一旦改变了卷积神经网络的参数,对一张图像来说就会有不同的编码。我们不断的训练参数,使得满足上面的目的。
4.4 Triplet 损失
为了学习卷积神经网络的参数,以获得一个优良的人脸图像的编码。
有一种方法是定义一个应用了梯度下降的三元组损失函数(triplet loss function)
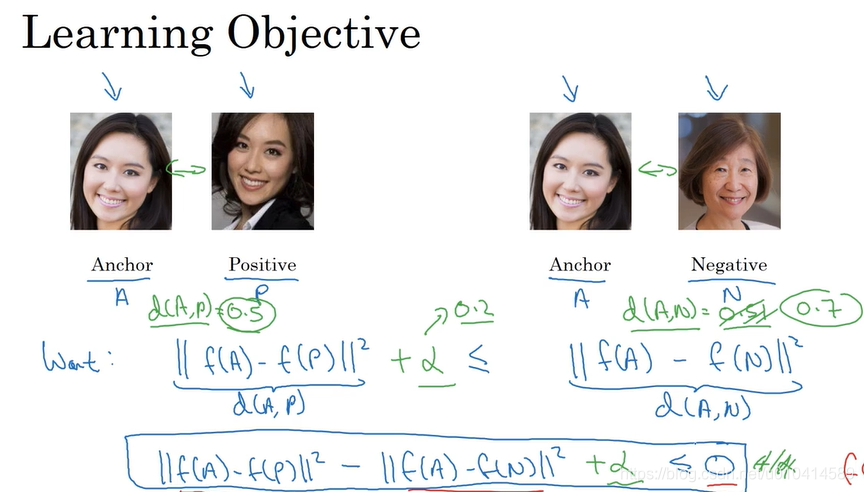
为了使用三元组,我们需要使用对照组,需要一张anchor 图像,一张正例图像,一张负例图像。作为一个组合。
我们希望做的,anchor 图像编码和正例图像编码的差平方,小于等于anchor图像编码和负例图像编码的差平方。
但是会有一种情况使得这个式子的条件轻易满足,就是所有图像的编码都为0或者说都一样。
为了确保神经网络不会把所有图像的编码训练的一样,我们需要在式子中加上一个margin 。margin 用来拉大d(A,P)和d(A,N)之间的差距。
下面我们正式定义三元组损失函数
通过定义一个L(A,P,N), 目标是使得L(A,P,N)最小,从而使我们上述公式小于等于0
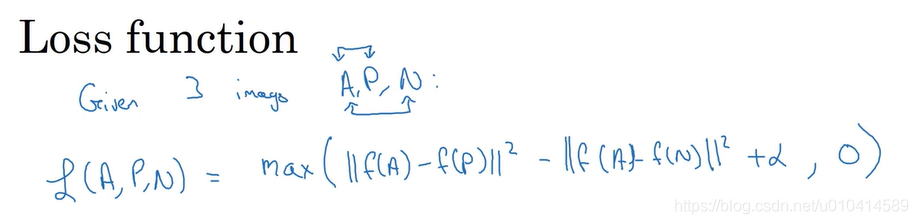
神经网络中全部训练数据集整体损失函数,是训练集中不同三元组对应的损失总和。
假设有一个训练数据集,其中包含1000个不同的人组成的10000张图像(平均1人10张图像),我们可以基于这10000张图像去生成三元组。然后用整体损失函数去训练学习算法。
注意在 训练阶段,至少确保一部分人需要有多张图像,来组成三元组。如果每个人都只有一张图像,则无法组成训练数据集。
那么如何选择正确的三元组呢?
这里的问题之一是如果随机的选择A,P,N,那么上述的约束很容易满足。
因为如果有两张随机选择的图像A,N,那么A和N的差异通常会远远大于A和P中间的差异。
那么神经网络将无法从中学习到更多有用的东西。
因此,要建立一个训练数据集,我们需要选择很难的训练数据三元组,

有时间的话去看看FaceNet 。
商业的人脸识别系统通常是使用几百万张图像,一千万图像甚至更多。
4.5 面部验证与二分类
Triplet loss 是一种学习用于人脸识别的ConvNet 的参数的好办法。
这节课介绍另一种学习参数的方法,
另一种训练人脸识别的方法是利用这一对神经网络,这个siamese 网络让他们都计算这些embeddings ,然后将这些输入到一个逻辑回归中做出预测,如果输入图像是同一个人,则目标结果将输出1,如果不是同一个人,则输出0。
所以,这是一种将人脸识别当做二元分类的方法。
对于逻辑回归部分的输入,是将两种不同编码之间逐个元素做差的绝对值求和,
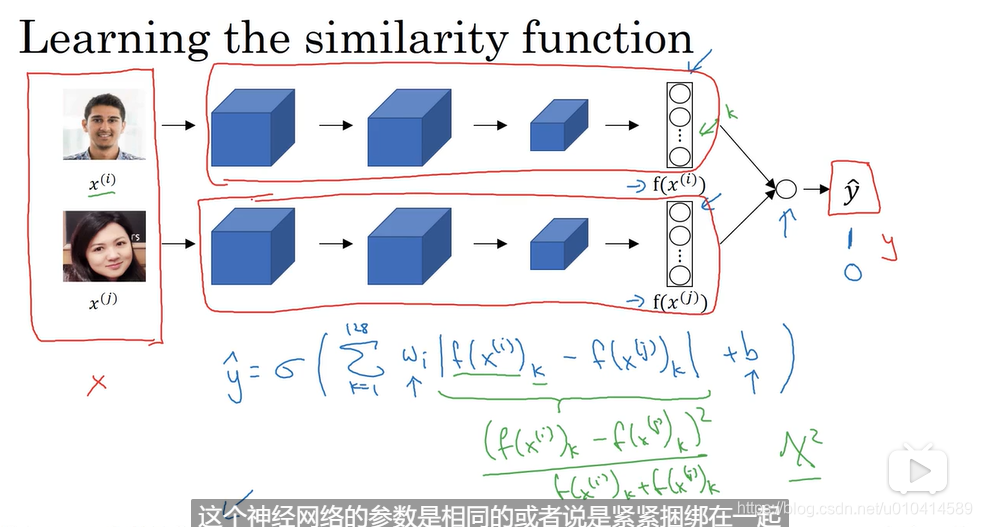
另外介绍一个计算的小技巧:
对于数据库已有的图像,不需要在每次预测的时候去计算它的编码。而是可以做预先计算。

4.6 神经风格转换

为了实现 神经风格转移,我们需要查看卷积神经网络在不同层中提取的特征值。包括浅层和深层的特征值。
4.7 什么是深度卷积网络
深度ConvNet 真正在学习什么?
本节课会展示一些可视化 的结果,帮助我们训练直觉,了解ConvNet 中很深的层真正在做什么。

阅读论文:Visualizing and understanding convolutional networks
4.8 代价函数
为了构建一个神经风格转移系统,我们为生成的图像定义一个代价函数。
我们有内容图像C,风格图像S,目的是生成具有与图像S风格、具有图像C内容的图像G。
我们要顶一个生成图像G的代价函数J,来衡量某个生成图像的质量有多好。

为了生成图像G:
- 随机初始化G
- 定义代价函数J,并使用梯度下降法来优化
在这个过程中,图像G由原始的充满噪点的图像,逐渐变成具备S风格C内容的图像。
