1. 前言
Scrapy中的所有组件如下所示:
引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。调度器从引擎接收请求,并使它们排队,以便在引擎请求时提供这些请求。。下载器负责获取网页并将其返回给引擎,引擎又将其返回给Spider。Spider是Scrapy用户编写的自定义类,用于解析响应并从中提取内容或其他需要跟踪的请求。- 一旦
Spider 提取出了items,则item pipeline负责处理这些items。 典型的任务包括清理,验证和持久性(例如将项目存储在数据库中)。 Downloader 中间件是位于引擎和Downloader之间的特定钩子,它们处理从引擎传递到Downloader时处理请求,以及从Downloader传递到Engine的响应。Spider 中间件是位于引擎和Spider之间的特定钩子,能够处理Spider的输入(响应)和输出(item和请求)。Scrapy用Twisted编写,Twisted是一种流行的Python事件驱动的网络框架。 因此,它是使用非阻塞(又称为异步)代码并发实现的。
Scrapy的体系架构如下:
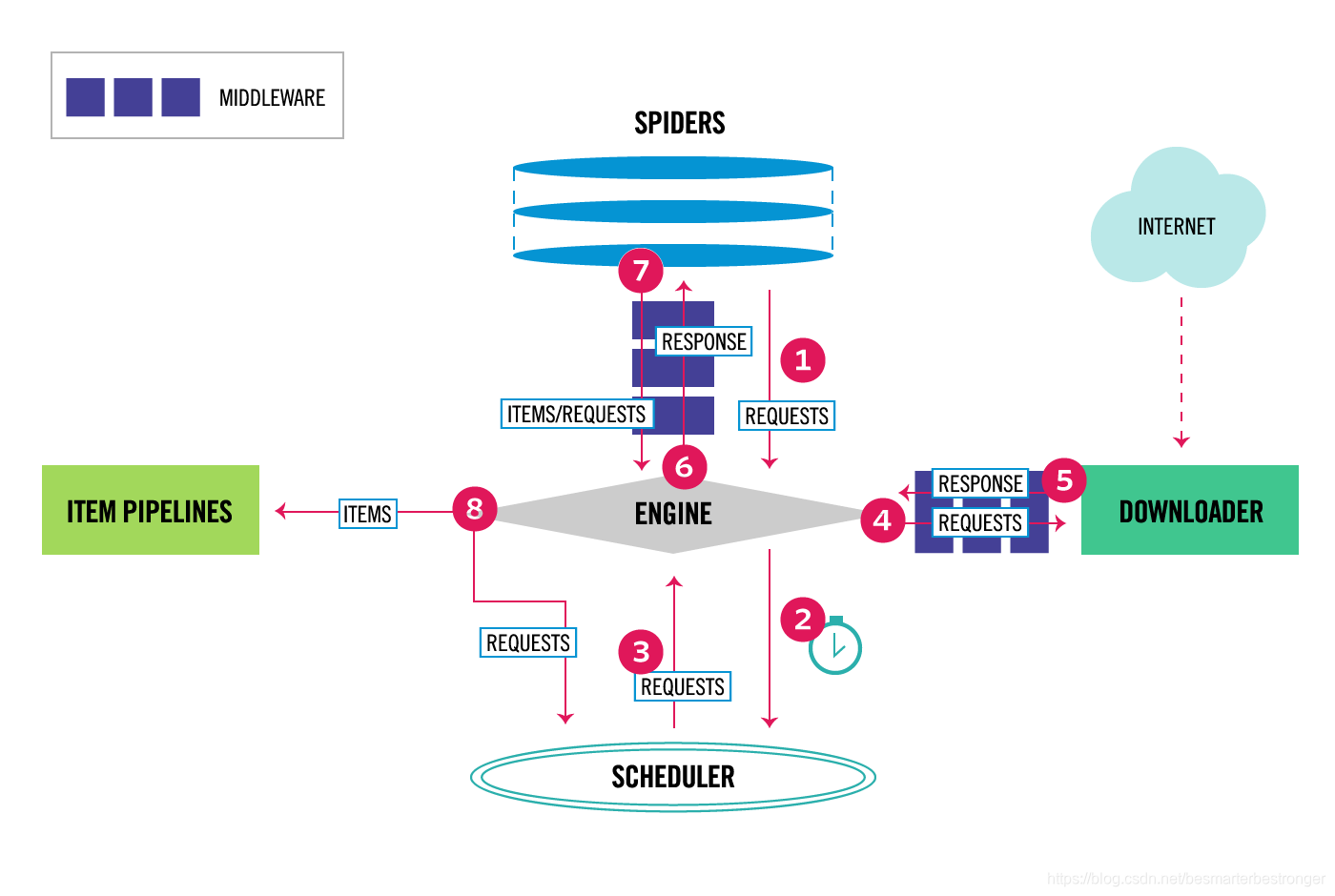
在Scrapy中数据流由 execution engine 控制, 过程如下:
Engine从Spider中获取到爬取的初始请求;Engine在Scheduler中调度请求,并请求下一个要爬取的请求。Scheduler返回下一个请求给Engine。Engine发送请求给Downloader, 需要经过Downloader Middlewares(见process_request()).- 一旦页面下载完成,
Downloader会生成该页面的响应,并将响应发送给Engine, 需要经过Downloader Middlewares(见process_response()). Engine从Downloader接收到响应,并将响应发送给Spider处理,需要经过Spider Middleware(见process_spider_input()).Spider处理响应并返回item和需要跟踪的新请求给Engine, 需要经过Spider Middleware(见process_spider_output()).Engine发送处理过的item给Item Pipelines, 然后将已处理的请求发送到调度程序,并要求进行爬取的下一个请求。- 从第一步开始重复,直到
Scheduler中没有请求了。
1.1 什么是Scrapy?
Scrapy是一个应用框架,常用于爬取网站和抽取结构化数据。
1.2 scrapy、BS 和 lxml
BeautifulSoup 是解析 HTML 的库。在Python程序员中是一个非常流行的Web抓取库,它基于HTML代码的结构构造了一个Python对象,并且能够很好地处理错误的标记,但是它有一个缺点:速度慢。
lxml 是一个XML解析库(它也解析HTML),使用基于 ElementTree . (LXML不是Python标准库。)
scrapy 是爬虫应用框架
1.3 爬取顺序
默认的爬取顺序是DFS,因为默认使用栈来存放爬虫请求。
1.4 需要解析的数据过大怎么办?
在使用XPath选择器解析HTML数据时,需要在内存中构建整个HTML的DOM,这可能会导致解析很慢并且会占用大量内存。
因此,为了避免一次在内存中解析所有的HTML数据,我们可以使用 scrapy.utils.iterators 模块中的 xmliter 和 csviter 。
1.5 部署 Scrapy 爬虫
有两种部署方式:
Scrapyd (open source)Scrapy Cloud (cloud-based)
1.6 Scrapy的依赖
Scrapy是纯python写的,它依赖于如下几个关键的python包。

lxml, 高效的XML和HTML解析器parsel, 是在lxml之上编写的HTML/XML数据提取库w3lib, 用于处理URL和网页编码的多功能帮助器twisted, 异步网络框架cryptographyandpyOpenSSL, 处理各种网络级安全需求
2. 创建Scrapy项目
在当前目录下,创建一个名为 recruitment 的爬虫项目。
scrapy startproject recruitment 项目目录(不写,则在当前目录创建该项目)
recruitment中的目录结构如下:
recruitment/
scrapy.cfg # deploy configuration file
recruitment/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
爬虫的主要逻辑代码写在spiders 目录中。比如,定义最初的爬取网站的url,选择如何遵循页面中url,如何解析下载的页面,如何提取数据等。
import scrapy
class RecruitmentSpider(spcrapy.Spider):
# spider的标识,在一个项目中,此name必须是唯一的。在同一个项目不能为两个不同spider取相同的name。
name = "recruitment"
def start_requests(self):
"""
返回请求的可迭代对象,标识spider从哪些url开始爬取。后序的请求都是由此请求产生。
"""
urls = [
'https://www.zhipin.com/',
'https://www.lagou.com/',
'https://landing.zhaopin.com/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
"""
response参数必须是 TextResponse的实例对象,
解析每一个URL响应、抽取数据、发现新的需爬取的URL。
"""
page = response.url.split("/")[-2]
filename = 'recruitment-{}.html'.format(page)
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file {}'.format(filename))
3. 如何运行spider
在项目目录下运行如下命令,这里 recruitment 是上面定义的spider的name。
scrapy crawl recruitment
终端中会有一些输出信息。
start_requests方法的返回值是 scrapy.Request 对象。
start_requests() 方法的快捷方式。很多时候可以不用我们来实现start_requests()方法,而是直接在start_urls这个类属性中定义需要爬取的URL,scrapy会使用自己start_requests()方法的默认实现。
所以上面的代码可以简化一下:
import scrapy
class RecruitmentSpider(scrapy.Spider):
# spider的标识,在一个项目中,此name必须是唯一的。在同一个项目不能为两个不同spider取相同的name。
name = "recruitment"
start_urls = [
'https://www.zhipin.com/',
'https://www.lagou.com/',
'https://landing.zhaopin.com/',
]
def parse(self, response):
"""
response参数必须是 TextResponse的实例对象,
解析每一个URL响应、抽取数据、发现新的需爬取的URL。
"""
page = response.url.split("/")[-2]
filename = 'recruitment-{}.html'.format(page)
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file {}'.format(filename))
4. Scrapy中的基础概念
4.1 命令行工具
命令行工具控制Scrapy。
Scrapy从如下文件中查找配置:
/etc/scrapy.cfg或c:\scrapy\scrapy.cfg(系统范围的配置)~/.config/scrapy.cfg($XDG_CONFIG_HOME) 和~/.scrapy.cfg($HOME) ,这是全局配置(用户范围的配置)- 项目根目录下的
scrapy.cfg。(项目范围的配置)
这些文件中的设置将按照优先顺序进行合并。从上到下,优先级越来越高。
一个项目的根目录(包含scrapy.cfg的目录)可以被多个Scrapy项目共享,每个Scrapy项目都有自己的设置模块。
# 创建一个项目
scrapy startproject myproject 项目目录
cd myproject
# 查看help
scrapy -h
scarpy 命令 -h
4.2 spiders
主要的爬取逻辑在这里。怎么爬,怎么提取数据等等。
抓取周期如下:
- 首先,生成对爬取第一个
URL的初始请求,然后指定一个回调函数,该函数在调用时会使用从这些请求下载的响应。 要执行的第一个请求是通过调用start_requests()(默认)方法 生成的对应start_urls的Request,然后将parse()方法作为Request的回调函数。 - 在回调函数中,解析
response并返回Item对象,或Request对象,或者是它们的可迭代对象。这些Requests还将包含回调函数(可以相同,可以不同),在scrapy下载之后,会由指定的回调函数来处理该request对应的response。 - 在回调函数中,通常使用
选择器(也可以使用beautifulsoup、lxml或任何喜欢的机制)来解析页面内容,并使用解析的数据生成item。 - 最后,从
spider返回的项目通常被持久化到数据库(通过Item Pipeline)或者使用Feed 导出写入文件中。
内置了几个通用spider类:
CrawlSpider。这是最常用的爬行常规网站的蜘蛛,因为它通过定义一组规则为跟踪链接提供了一种方便的机制。XMLFeedSpider。CSVFeedSpider。SitemapSpider。
4.3 选择器
使用选择器从页面中提取数据。
Scrapy选择器支持如下:
CSS选择器。其实,CSS选择器也是在后台转换为XPath的XPath表达式。是Scrapy选择器的基础,很强大。
scrapy使用自己的机制来提取数据,这就是scrapy的selector。在scrapy中要提取HTML中的数据,可以使用3种方式:
response.selector.css()或response.selector.xpath()response.css()。::text表示提取该元素的文本内容,::attr(name)表示提取该元素的某属性值。response.xpath()
他们的返回值都是SelectorList的实例对象,对此实例对象调用get()或.getall()方法,分别获得第一个符合条件的元素,和所有符合条件的元素的list。使用.attrib属性可以获取提取的元素中的某属性值。
嵌套调用
由于.xpath()和.css()的返回值都是selector,所以还可以继续调用.xpath()和.css()方法。
elem_div = response.xpath("//div")
elem_a = elem_div.xpath(".//a").getall()
选择元素属性
从HTML元素中提取元素属性的值,有如下3种方法。
response.xpath("//a/@href").getall()response.css("a::attr(href)").getall()[a.attrib['href'] for a in reponse.css('a')]
使用正则表达式
Selector还可以使用.re()方法来提取数据。返回值是unicode字符串的list。 .re_first() 提取满足正则表达式的第一个结果。
.get()的别名是.extract_first().getall()的别名是.extract()
因为使用前者更清晰明了,所以推荐使用前者。
XPaths
在使用.xpath()的时候,/开头表示是绝对的xpath路径。
./开头表示相对的xpath路径。
>>> divs = response.xpath('//div')
>>> for p in divs.xpath('//p'): # this is wrong - gets all <p> from the whole document
... print(p.get())
# correct way
>>> for p in divs.xpath('.//p'): # extracts all <p> inside
... print(p.get())
按照 class来查询时,使用.css()是更好的选择。
# class名为 shout 的 <a>标签的href属性
>>> response.css('.shout').xpath('./a/@href/').getall()
4.4 Items
Spiders会将提取的数据存放在items中,这是一个key-value的Python对象。
Scrapy支持一下类型的Item:
字典Item对象dataclass 对象attrs对象。
声明一个Item
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
tags = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
Scrapy中的Item定义有些像Django中的Model,但是更简单,没有不同的Field之分。
声明field
Field对象是用来指明每一个字段的元数据的。Scrapy中没有对Field对象所能接受的值做限制。
需要注意的是,在Item子类中定义的这些字段,并不是该子类的类属性,而是应该通过Item.fields来获取这些字段。
其实Field类就是Python中dict类的别名,,它并没有任何其它的功能或属性。
创建items
>>> product = Product(name='Desktop PC', price=1000)
>>> print(product)
Product(name='Desktop PC', price=1000)
获取字段的值
# 用法就跟字典很相似
>>> product['name']
Desktop PC
>>> product.get('name', 'unknown field')
Desktop PC
设置字段的值
>>> product['name'] = 'Desktop PC for sjl'
获取所有填充了的值
>>> product.keys()
['price', 'name']
>>> product.items()
[('price, 1000), ('name', 'Desktop PC for sjl')]
复制 items
# 可以选择浅拷贝和深拷贝,浅拷贝和深拷贝这里就不多讲了
product2 = product.copy()
product2 = product.deepcopy()
Scrapy并不是直接填充items,而是有自己的机制。
items为爬取的数据提供容器,Item Loader为该容器提供了填充机制。
4.5 Item Loader
Item Loader用来填充数据进item中。
from scrapy.loader import ItemLoader
from myproject.items import Product
def parse(self, response):
l = ItemLoader(item=Product(), response=response)
l.add_xpath('name', '//div[@class="product_name"]')
l.add_xpath('name', '//div[@class="product_title"]')
l.add_xpath('price', '//p[@id="price"]')
l.add_css('stock', 'p#stock]')
l.add_value('last_updated', 'today') # you can also use literal values
return l.load_item()
输入和输出处理器
一个Item Loader 为每一个 item的字段都指定了一个输入处理器和输出处理器。
- 当提取的数据被
Item Loader接收(如:add_xpath(),add_css(),add_value()方法)时会使用输入处理器处理它们,并保存在ItemLoader中。 - 然后调用
ItemLoader.load_item()方法获得Item对象并在输出处理器处理这些数据之后进行填充到item中。
4.6 Scrapy shell
用于开发和调试你的spiders代码的。
scrapy shell <needing_scraped_url>
4.7 item pipeline
详情见 初识 Scrapy - Item Pipeline
在item被spider抓取之后,它会被发送到Item Pipeline,该管道通过几个按顺序执行的组件来处理它。
每一个item pipeline组件都是Python的类。它们接收item,并对它执行操作,还决定该项目是否应继续通过管道,或者是否应删除并不再处理。
item pipeline的典型用途有:
- 清理
HTML数据 - 验证抓取的数据(检查项目是否包含某些字段)
- 检查重复项(并删除它们)。通过
pipeline的process_item()方法实现 - 将爬取的项目存储在数据库中
4.8 feed导出
详情见 初识 Scrapy - Feed导出
在实现scraper时,常需要的功能之一是能够正确地存储被抓取的数据,这意味着用被抓取的数据(通常称为“导出提要”)生成一个“导出文件”,供其他系统使用。
Scrapy通过Feed导出提供了这样一个开箱即用的功能。允许你根据抓取的items使用多种序列化格式和存储后端生成feeds。
4.9 Scrapy的Request和Response
Scrapy使用Request和Response对象来爬取网站。
通常,Request对象是在Spider中生成的,并在整个系统中传递,直到它们到达Downloader,该Downloader执行请求并返回Response对象,该Response对象返回到发出请求的Spider中。
4.10 link提取器
用于从repsonse中提取link。
LxmlLinkExtractor 中的 __init__ 方法决定应该提取什么样的link。
LxmlLinkExtractor.extract_links 接收 Response 对象并返回 scrapy.link.Link对象。
4.11 设置
设置的优先级:
- 命令行选项(最高优先级)
- 每一个spider的设置
- 项目的setting模块
- 每个命令的默认设置
- 默认的全局设置
在Spider中通过self.settings来访问设置。
4.12 异常
Scrapy中有一些内置的异常:
CloseSpider。在spider的request关闭或停止时,在request的回调函数中引发。DontCloseSpider。在spider_idle信号处理器中引发,以阻止关闭spider。DropItem。在item pipeline阶段引发,以停止处理某Item。IgnoreRequest。由Scheduler或任何downloader中间件引发,以表示此request应当被忽略。NotConfigured。由某些组件引发,以表示这些组件是禁用的。NotSupported。引发此异常表示不支持某特性。StopDownload。由bytes_received信号处理器引发,以表示response没有更多的可下载的bytes了。
5. 参考文献
[1] Scrapy 官方文档