文章目录
1. 前言
Scrapy的架构图如下所示:
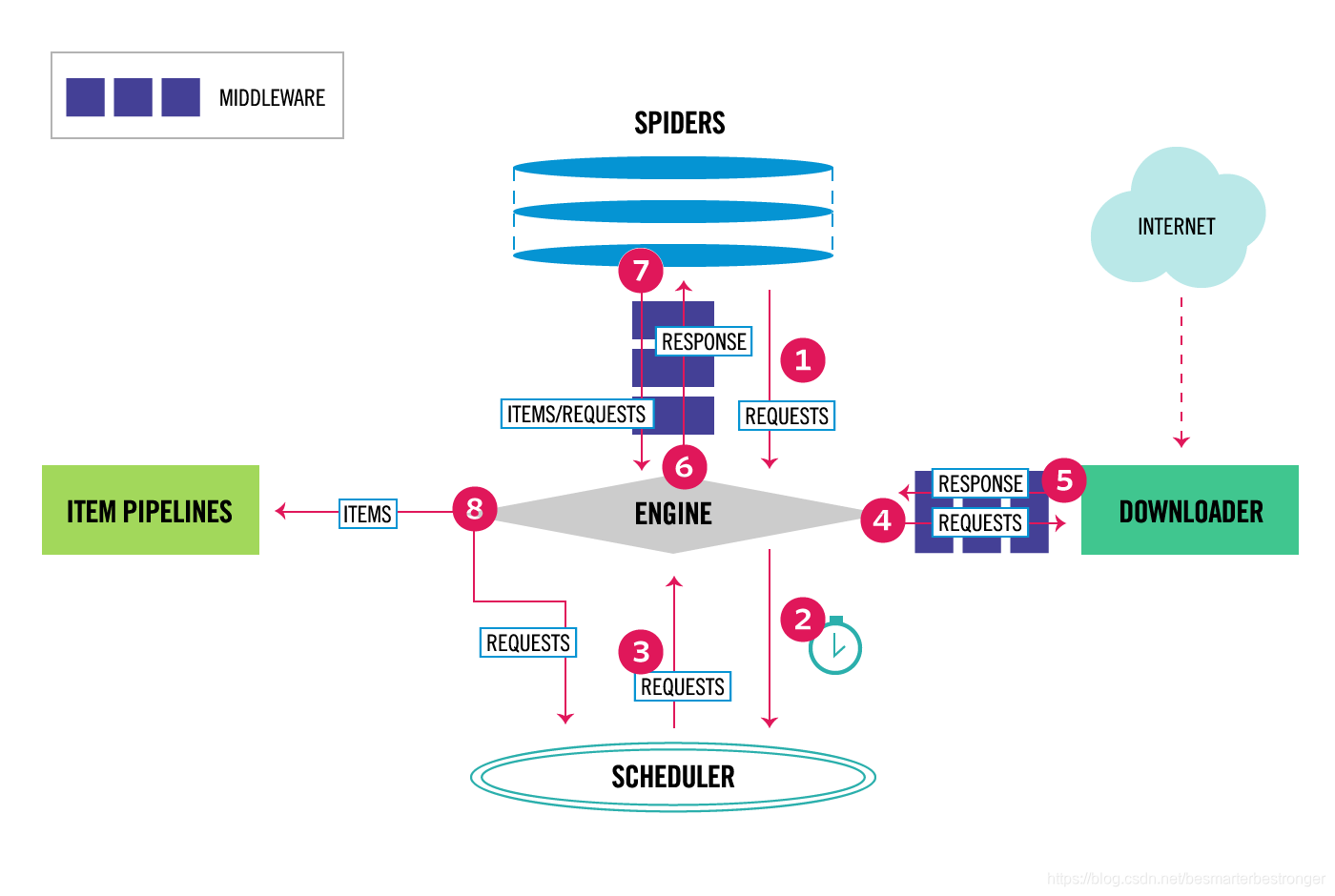
2. Downloader 中间件
downloader 中间件是 Scrapy 框架中处理 request/response 的钩子,它十分轻量,可以在全局修改 Scrapy 的 requests 和 responses。
2.1 激活downloader中间件
要激活一个 downloader 中间件,只需要在 settings 文件中的 DOWNLOADER_MIDDLEWARES 中设置该中间件即可。键是中间件类的路径,值是中间件的顺序值。
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES 设置会合并Scrapy中的默认设置中的 DOWNLOADER_MIDDLEWARES_BASE (也就是说,就算你什么 downloader 中间件都没有启用,仍然会有一些 Scrapy 的默认 downloader 中间件会执行。)然后会将合并的 downloader 中间件进行从小到大排序。按照从小到大的顺序执行中间件类的process_request()方法,然后从大到小执行中间件类的process_response()方法。
中间件的顺序很重要,因为每个中间件执行不同的操作,有些操作可能取决于中间件的执行先后。
如果想要禁用内置的中间件(定义在Scrapy中的DOWNLOADER_MIDDLEWARES_BASE,默认启用),你需要在你的项目中的 DOWNLOADER_MIDDLEWARES 设置中将 None 赋值给需要禁用的中间件。如下所示。
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
最后,请记住,可能需要通过特定设置来启用某些中间件。 有关更多信息,请参见中间件文档。
2.2 写自定义的 downloader 中间件
每一个 downloader中间件其实就是一个 Python 类,必须在这些类中实现某些方法。
主要入口点是 from_crawler() 类方法,该方法接收 Crawler 实例。 借助Crawler对象,您可以访问例如设置,等数据。

class scrapy.downloadermiddlewares.MyDownloaderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
# 调用此类方法,根据crawler创建一个该middleware的实例对象,通过crawler可以获取settings和signals等。这是中间件访问它们并将其功能连接到Scrapy中的一种方式
pass
def process_request(self, request, spider):
# 每个request都会调用downloader中间件的此方法。
pass
def process_response(self, request, response, spider):
# 每个response都会调用downloader中间件的此方法。
pass
def process_exception(self, request, exception, spider):
# 当download handler或者 process_request()方法raise异常的话,Scrapy 会调用每一个downloader中间件的此方法。
pass
Scrapy 有很多内建的downloader 中间件,详情见 Scrapy 官方文档 Dowanloder 中间件
3. Spider 中间件
spider 中间件是 Scrapy 框架中处理 spider 的钩子。看看上面的架构图,此种中间件是用来处理发送给spider的response,处理由spider产生的requests和items。
3.1 激活spider中间件
将要激活的spider中间件,添加到settings文件的 SPIDER_MIDDLEWARES 设置中。键是中间件类的路径,值是中间件的顺序值。
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
}
SPIDER_MIDDLEWARES 设置会合并Scrapy的默认设置中的 SPIDER_MIDDLEWARES_BASE,然后排序之后得到最终的启用的中间件的list。按照从小到大的顺序执行每一个中间件的process_spider_input()方法,从大到小的顺序执行每一个中间的process_spider_output()方法。
中间件的顺序很重要,因为每个中间件执行不同的操作,有些操作可能取决于中间件的执行先后。
禁用spider中间件的方式与downloader中间件类似。
3.2 写自定义spider中间件
每一个spider中间件就是一个Python类,这个类必须实现以下方法。
主要入口是 from_crawler()类方法,它接收一个Crawler实例对象。例如,通过Crawler可以获取设置。
class scrapy.spidermiddlewares.SpiderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
# 调用此方法创建一个中间件的实例。此方法必须返回一个中间的的实例对象。
pass
def process_spider_input(self, response, spider):
# 每一个通过spider中间件传递给spider的response都会调用中间件的此方法。
pass
def process_spider_output(self, response, result, spider):
# 处理完response之后,从spider返回的results时,调用中间件的此方法。
pass
def process_spider_exception(self, response, exception, spider):
# 当Spider或process_spider_output()方法(来自先前的Spider中间件)引发异常时,将调用此方法。
pass
def process_start_request(self, start_requests, spider):
# 以spider的start repsponse为参数调用此方法,工作原理与process_spider_output()相似。不同之处在于,它没有关联的response,必须返回requests。
pass
Scrapy 有很多内建的 spider 中间件,详情见 Scrapy 官方文档 Spider 中间件
4. 扩展
扩展框架提供了一种将自己的自定义功能插入Scrapy的机制。
扩展只是在初始化扩展时在Scrapy启动时实例化的常规类。
扩展使用Scrapy 设置来管理它们的设置,就跟其它Scrapy代码一样。
扩展名通常会在其设置前加上自己的名称,以避免与现有(和将来)扩展名冲突。 例如,用于处理Google Sitemaps的假设扩展将使用GOOGLESITEMAP_ENABLED,GOOGLESITEMAP_DEPTH等设置。
4.1 加载和激活扩展
通过实例化一个扩展类来实现扩展的加载和激活。因此,所有扩展的初始化代码都必须在类的__init__方法中执行。
将扩展设置加入项目的Scrapy的设置中,就可以使用该扩展了。与上面的中间件的设置也挺相似的。如下所示:
EXTENSIONS = {
'scrapy.extensions.corestats.CoreStats': 500,
'scrapy.extensions.telnet.TelnetConsole': 500,
}
如你所见,EXTENSIONS设置也是一个字典,键是扩展的路径,值是顺序值,这决定了扩展的加载顺序。EXTENSIONS设置会和Scrapy默认设置中的EXTENSIONS_BASE进行合并,最终得到拍好序的启用的扩展的list。
通常而言,扩展是不相互依赖的,即加载顺序不重要。这也就是为什么在Scrapy的EXTENSIONS_BASE设置中,所有扩展的顺序值都是0。当然,如果你写的扩展依赖于其他扩展,你就必须按顺序来加载扩展了,这都由你来决定。
4.2 可用、启用和禁用扩展
不是所有可用的扩展都会被启用,有些依赖于特殊的设置。比如,HTTP Cache extension 默认是可用的,但是只有在设置了HTTPCACHE_ENABLED后,才是启用的。
如果要禁用默认的扩展,则需要在你的settings文件中将该顺序值设为None。如下所示。
EXTENSIONS = {
'scrapy.extensions.corestats.CoreStats': None,
}
4.3 写自定义的扩展
每一个扩展就是一个Python类。主要入口点还是from_crawler()类方法。该类方法有一个参数Crawler,通过Crawler对象可以获取到settings,signals,stats并且可以控制爬虫的行为。
通常,可以将扩展和signals关联起来,当触发signal时执行某些任务。
最终,如果from_crawler()类方法引发了NotConfigured异常,则该扩展会被禁用,否则启用。
一个自定的扩展示例代码如下所示:
- spider被打开时,会记录日志。
- spider被关闭时,会记录日志。
- 日志中还会记录已经爬取的item的数量。
该扩展名将通过MYEXT_ENABLED设置启用,而item的数量将通过MYEXT_ITEMCOUNT设置指定。
import logging
from scrapy import signals
from scrapy.exceptions import NotConfigured
logger = logging.getLogger(__name__)
class SpiderOpenCloseLogging:
def __init__(self, item_count):
self.item_count = item_count
self.items_scraped = 0
@classmethod
def from_crawler(cls, crawler):
# first check if the extension should be enabled and raise
# NotConfigured otherwise
if not crawler.settings.getbool('MYEXT_ENABLED'):
raise NotConfigured
# get the number of items from settings
item_count = crawler.settings.getint('MYEXT_ITEMCOUNT', 1000)
# instantiate the extension object
ext = cls(item_count)
# connect the extension object to signals
crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed)
crawler.signals.connect(ext.item_scraped, signal=signals.item_scraped)
# return the extension object
return ext
def spider_opened(self, spider):
logger.info("opened spider %s", spider.name)
def spider_closed(self, spider):
logger.info("closed spider %s", spider.name)
def item_scraped(self, item, spider):
self.items_scraped += 1
if self.items_scraped % self.item_count == 0:
logger.info("scraped %d items", self.items_scraped)
Scrapy 有很多内建的扩展,详情见 Scrapy 官方文档 Extensions
5. 核心 API
Scrapy的核心API主要是以下几个:
- Crawler API。
- Settings API
- SpiderLoader API
- Signals API
- Stats Collector API
6. 信号(Signals)
当某事件发生时,Scrapy使用signals来通知相关的你的spider项目做一些额外的任务。
尽管signals提供了几个参数,但是捕获signals的handlers并不需要接收所有的参数。信号分发机制只会将handler所要接收的参数传递给handlers。
下面的例子,展示了如何捕获signals,并执行对应的操作。
from scrapy import signals
from scrapy import Spider
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/",
]
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(DmozSpider, cls).from_crawler(crawler, *args, **kwargs)
# 将spider_closed信号和spider.spider_closed方法关联起来了,当触发对应的时间,该信号就会通知scrapy来执行该方法。
crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed)
return spider
def spider_closed(self, spider):
spider.logger.info('Spider closed: %s', spider.name)
def parse(self, response):
pass
6.1 延迟信号处理器(Defferred signal handlers)
有一些signals支持handlers返回Deferred对象。这允许你运行异步的代码,并不会阻塞Scrapy。如果signal handler 返回Deferred对象,则Scrapy等待该Deferred触发。示例代码如下:
class SignalSpider(scrapy.Spider):
name = 'signals'
start_urls = ['http://quotes.toscrape.com/page/1/']
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(SignalSpider, cls).from_crawler(crawler, *args, **kwargs)
# 将item_scraped信号和spider.item_scraped方法关联起来,收到该信号时,执行该方法。
crawler.signals.connect(spider.item_scraped, signal=signals.item_scraped)
return spider
def item_scraped(self, item):
# Send the scraped item to the server
d = treq.post(
'http://example.com/post',
json.dumps(item).encode('ascii'),
headers={
b'Content-Type': [b'application/json']}
)
# The next item will be scraped only after
# deferred (d) is fired
return d
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
7. Item exporters
一旦你抓取到了你的items,常常想要持久化或者导出数据,供其他应用使用这些数据。毕竟,这就是爬虫的目的。
在这里是讲Item Exporter如何工作的和增加一些自定义的功能,如果只是想要快速导出爬取的数据,去看看 Feed 导出就行了。
那么如何使用一个Item Exporter?
- 使用所需的参数实例化Item Exporter。
- 调用方法 start_exporting() 以表示 exporting 过程的开始。
- 对要导出的每个项目调用 export_item() 方法。
- 最后调用 finish_exporting() 表示 exporting 过程的结束
下面这个例子中,一个Item Pipeline使用了多个Item Exporters,并根据item的某字段的值对其进行分组,不同分组使用不同的Item Exporters。
from itemadapter import ItemAdapter
from scrapy.exporters import XmlItemExporter
class PerYearXmlExportPipeline:
"""Distribute items across multiple XML files according to their 'year' field"""
def open_spider(self, spider):
self.year_to_exporter = {
}
def close_spider(self, spider):
for exporter in self.year_to_exporter.values():
exporter.finish_exporting()
def _exporter_for_item(self, item):
adapter = ItemAdapter(item)
year = adapter['year']
if year not in self.year_to_exporter:
f = open('{}.xml'.format(year), 'wb')
exporter = XmlItemExporter(f)
exporter.start_exporting()
self.year_to_exporter[year] = exporter
return self.year_to_exporter[year]
def process_item(self, item, spider):
exporter = self._exporter_for_item(item)
exporter.export_item(item)
return item
7.1 序列化item的字段
默认情况下,该字段的值将不变的传递到序列化库,如何对其进行序列化的决定被委托给每一个特定的序列化库。然而,你可以自定义每个字段的值在传递给序列化库之前做如何的序列化。
有两种自定义字段的值序列化的方法:
- 在字段中声明一个serializer。在声明你的Item类时,为该字段声明一个serializer。这个serializer必须是一个可调用对象。
import scrapy
def serialize_price(value):
return '$ %s' % str(value)
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field(serializer=serialize_price)
- 重写serialize_field()方法。自定义一个Exporter类,然后重写serialize_field()方法。最后,需要调用基类的serialize_field()方法。
from scrapy.exporter import XmlItemExporter
class ProductXmlExporter(XmlItemExporter):
def serialize_field(self, field, name, value):
if field == 'price':
return '$ %s' % str(value)
return super(Product, self).serialize_field(field, name, value)
详情见 Scrapy 官方文档 Item Exporters
8. 参考文献
[1] Scrapy 官方文档