区域候选网络RPN(Region Proposal Network)的学习、理解
欢迎大家系统学习Faster RCNN原理的专题讲座:
Faster RCNN原理篇(一)——Bounding-Box Regression边界框回归的学习和理解
Faster RCNN原理篇(二)——RoIPooling和RoIAlign的学习和理解
RPN(Region Proposal Network)
1、(Why?)为何提出RPN
经典的目标检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;亦或RCNN和Fast RCNN等物体检测架构,采用SS(Selective Search)方法来提取候选框,它在CPU上检测一张图需要2s。
RPN 全称是Region Proposal Network。Region Proposal的中文意思是“区域选取”,也就是“提取候选框”的意思。RPN 首次在Faster RCNN结构中提出。RPN的目标是代替Selective Search实现候选框的提取。一方面RPN耗时少,另一方面RPN很容易结合到Fast RCNN中,成为一个整体。所以,RPN的核心功能: 专门用来提取候选框。
2、(Connection?)RPN与Faster RCNN网络的关联
RPN的引入真正意义上把物体检测整个流程融入到一个神经网络中,这个网络结构叫做 Faster RCNN。
F a s t e r R C N N = R P N + F a s t R C N N Faster \quad RCNN = RPN + Fast \quad RCNN FasterRCNN=RPN+FastRCNN
图1为 Faster RCNN网络的整体结构示意图 :
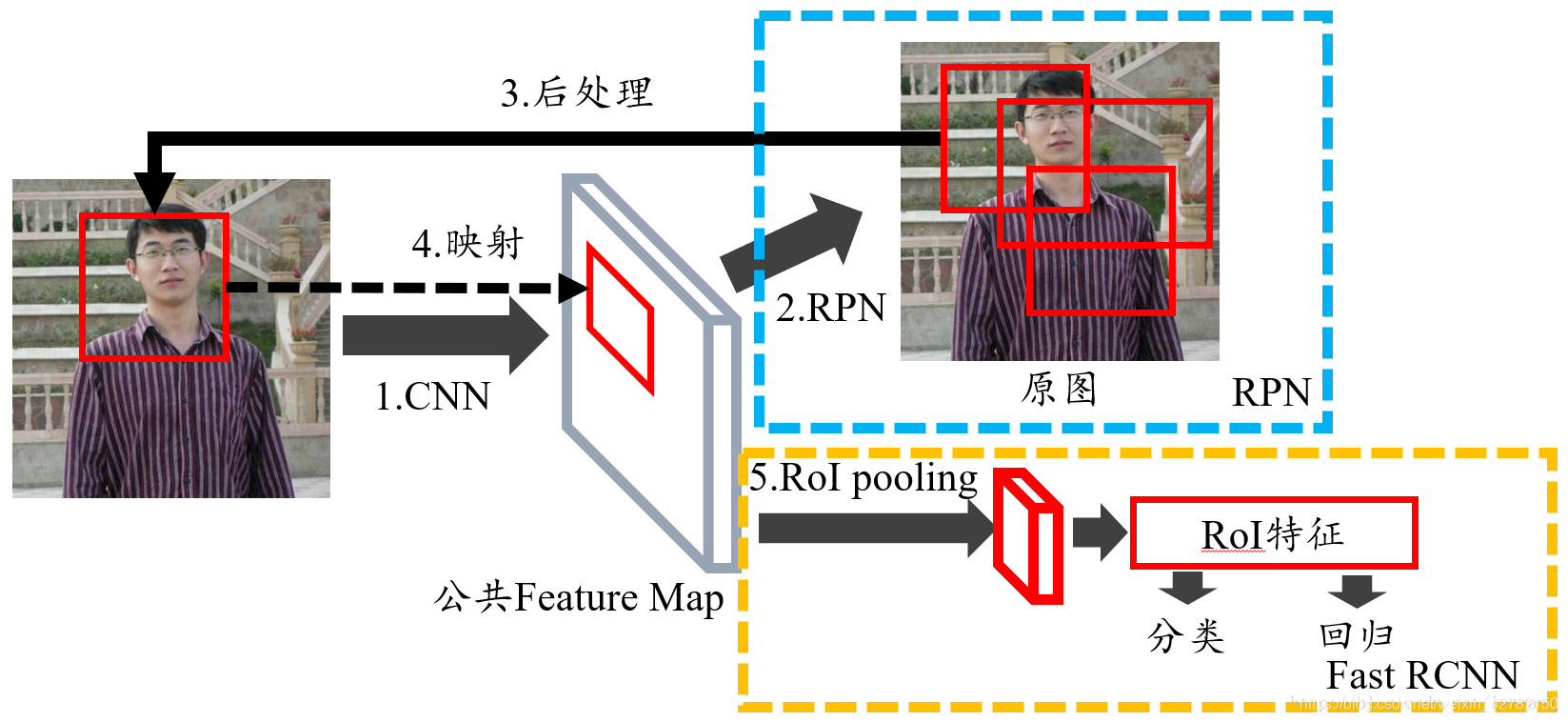
图2展示了python版本的 VGG16模型中的Faster RCNN的网络结构 ,可以清晰的看到该网络对于任意一张 P × Q P×Q P×Q大小的图像,将执行如下操作:
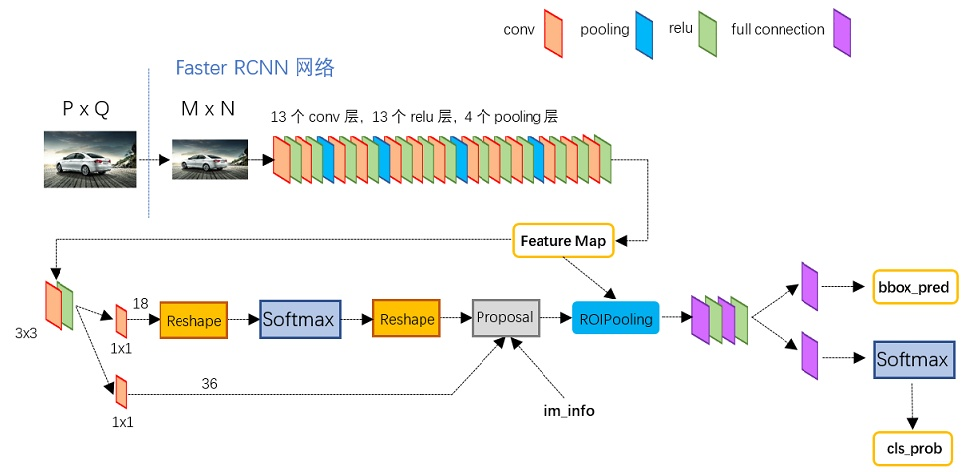
- 首先将 P × Q P×Q P×Q大小的原始image缩放至固定大小 M × N M×N M×N;
- 然后将 M × N M×N M×N的image送入网络(备注:Conv layers中包含了13个conv层+13个relu层+4个pooling层),生成
共享Feature Map; - 进入RPN网络,首先经过 3 × 3 3×3 3×3 卷积,再分别生成
positive anchors和对应bounding box regression偏移量,然后计算出proposals; - 进入Roi Pooling层,利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
参考链接:RPN(区域生成网络)
3、(What?)什么是RPN(Region Proposal Networks)
RPN 的总体结构: 1、生成Anchors ⇒ \Rightarrow ⇒ Softmax分类器提取Positvie Anchors ⇒ \Rightarrow ⇒ Bounding Box Reg回归微调Positive Anchors ⇒ \Rightarrow ⇒ Proposal Layer生成proposals。
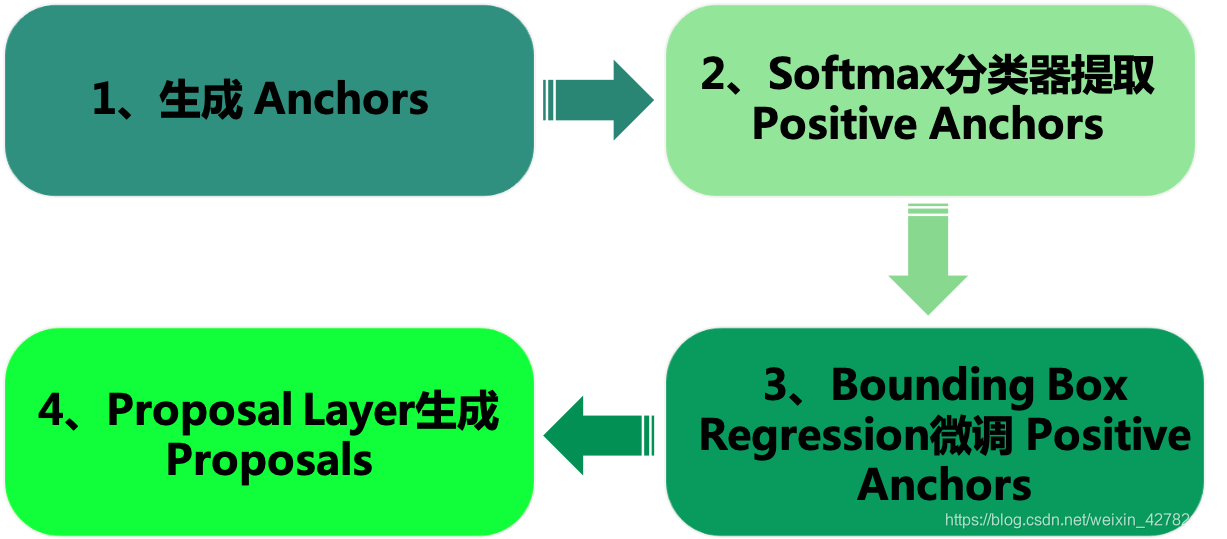
最后的Proposal Layer层负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除重叠和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
RPN 涉及的几个重要问题:
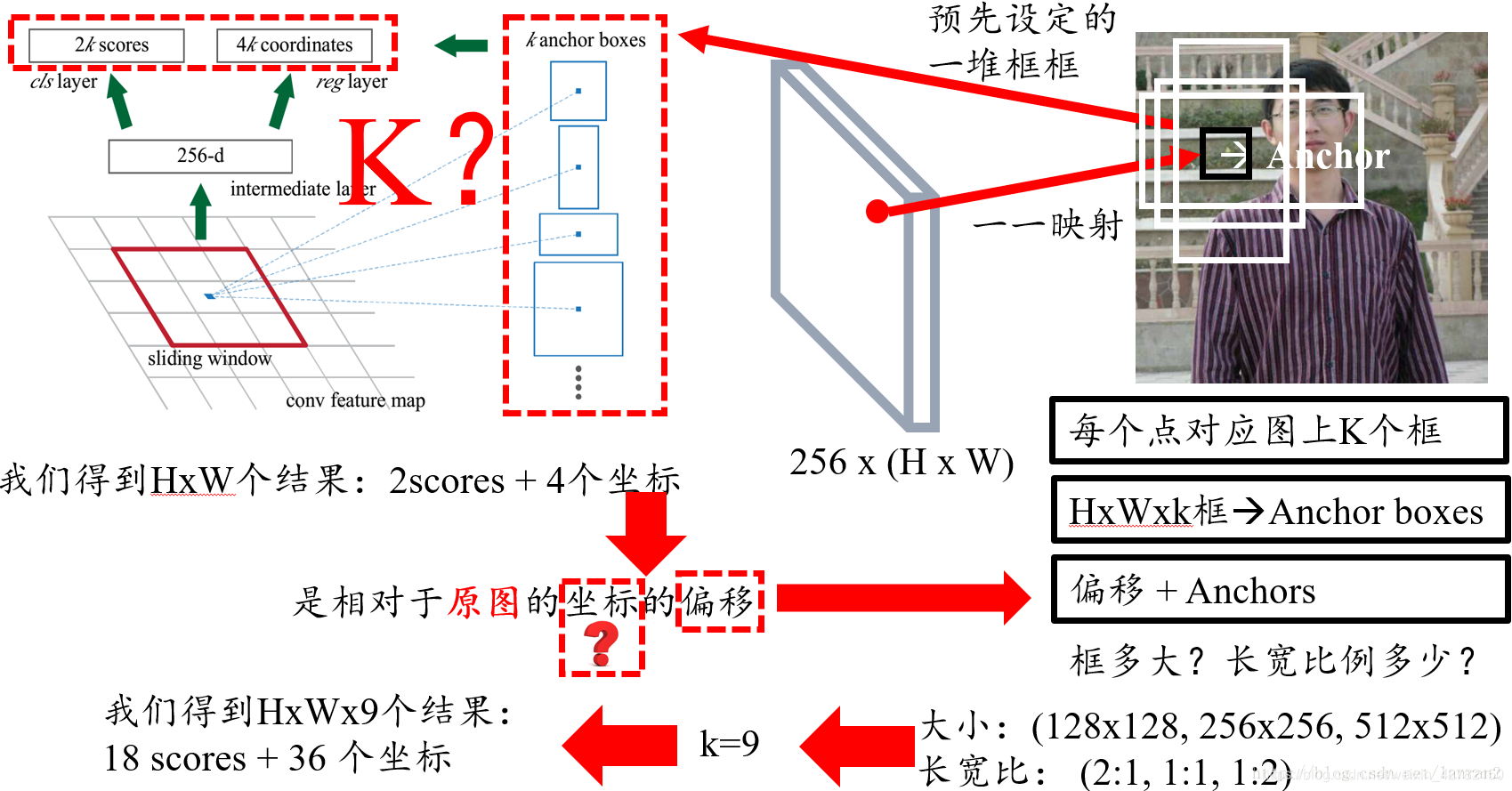
- RPN的 input 特征图指的是哪个特征图?
Answert: RPN的输入特征图是指Faster RCNN的公共Feature Map,也称“共享Feature Map”,主要用以RPN和RoI Pooling共享。- 为什么是用sliding window?文中不是说用CNN么?
Answert: 我们可以把 3 × 3 3×3 3×3 的sliding window看作是对特征图做了一次 3 × 3 3×3 3×3 的卷积操作,最后得到了一个channel数目是256的特征图,尺寸和公共特征图相同,我们假设是 256 × ( H × W ) 256 ×(H×W) 256×(H×W);- 256维特征向量如何获得的?
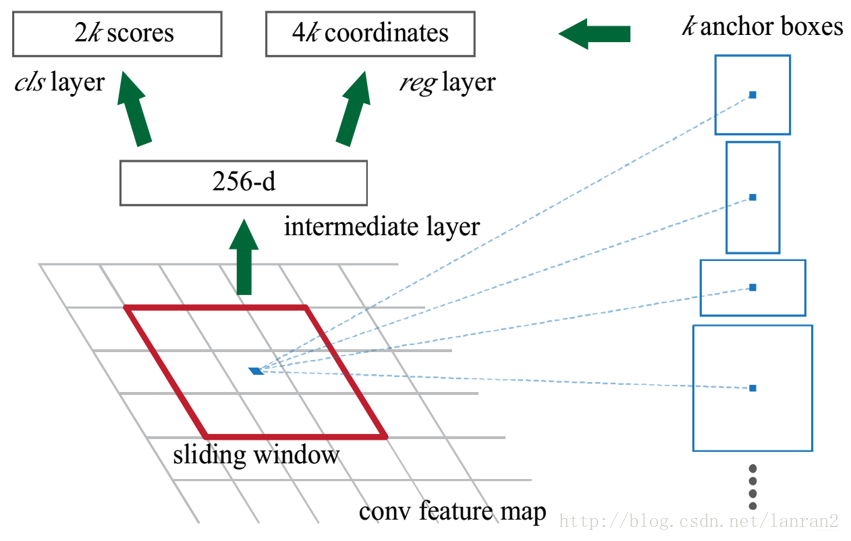
Answert: 我们可以近似的把这个特征图看作有 H × W H×W H×W个向量,每个向量是256维,那么图中的256维指的就是其中一个向量,然后我们要对每个特征向量做两次全连接操作,一个得到2个分数,一个得到4个坐标,由于我们要对每个向量做同样的全连接操作,等同于对整个特征图做两次 1 × 1 1×1 1×1的卷积,得到一个 2 × H × W 2×H×W 2×H×W和一个 4 × H × W 4×H×W 4×H×W大小的特征图,换句话说,有 H × W H×W H×W个结果,每个结果包含2个分数和4个坐标;- 2k和4k中的k指的是什么?
Answert: 是指由锚点产生的K个框;- 图右侧不同形状的矩形和Anchors又是如何得到的?
Answert: 首先我们知道有H x W个结果,我们随机取一点,它跟原图肯定是有个一一映射关系的,由于原图和特征图大小不同,所以特征图上的一个点对应原图肯定是一个框,然而这个框很小,比如说8 x 8,这里8是指原图和特征图的比例,所以这个并不是我们想要的框,那我们不妨把框的左上角或者框的中心作为锚点(Anchor),然后想象出一堆框,具体多少,聪明的读者肯定已经猜到,K个,这也就是图中所说的K anchor boxes(由锚点产生的K个框);换句话说,H x W个点,每个点对应原图有K个框,那么就有H x W x k个框默默的在原图上,那RPN的结果其实就是判断这些框是不是物体以及他们的偏移;那么K个框到底有多大,长宽比是多少?这里是预先设定好的,共有9种组合,所以k等于9,最后我们的结果是针对这9种组合的,所以有H x W x 9个结果,也就是18个分数和36个坐标;
- 关于256维特征中256由来的理解?
如上图,一个特征图经过sliding window处理,得到256维特征,然后通过两次全连接得到结果2k个分数和4k个坐标;
Answert: 在原文中使用的是ZFNet网络中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions。
\quad
在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息(猜测这样做也许更鲁棒?),同时256-d不变(如图4和图7中的红框)
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4k coordinates。
注意: 如果使用的是VGG网络,最后的conv5 num_output=512,所以是512d,其他类似。所以,256-d并不是固定不变的,而是随着选取网络结构不同,随之发生改变。
\quad其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,仅仅是个二分类而已!
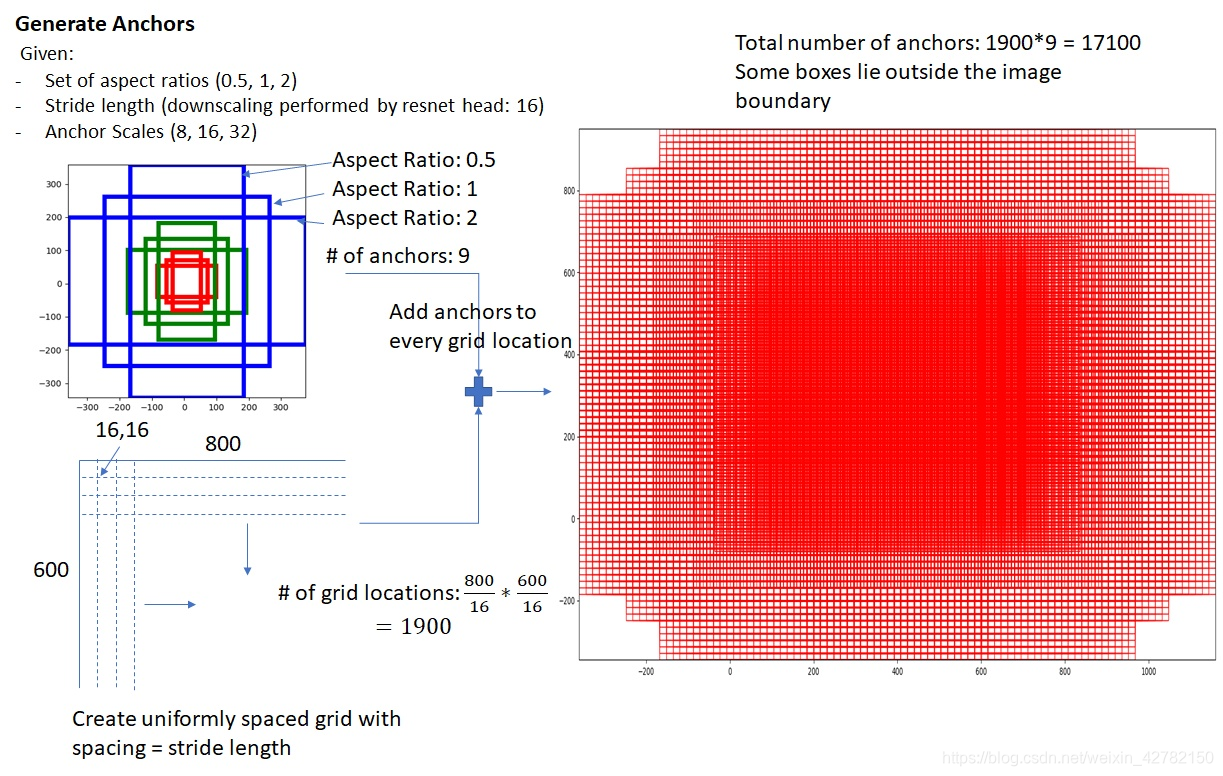
那么Anchor一共有多少个?原图800x600,VGG下采样16倍,feature map每个点设置9个Anchor,所以:
其中ceil()表示向上取整,是因为VGG输出的feature map size= 50*38。
![[公式]](https://img-blog.csdnimg.cn/20201215183814475.png)
4、(How?)RPN的具体实现
1. 生成Anchors
Anchor是固定尺寸的bbox。具体作法是:把feature map每个点映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取 k k k 个不同的尺寸和比例的anchor。 对于 W × H W×H W×H大小的卷积feature map(通常为2400),总共有 W × H × k W×H×k W×H×k 个锚点。
对于该图像的每一个基准点,一般取 k = 9 k=9 k=9 个可能的候选窗口:默认使用3个尺度(128, 256, 512)和3个纵横比(1:1, 1:2, 2:1),这些候选窗口称为anchors。计算每个像素256-d的9个尺度下的值,得到9个anchor。接下来,我们给每个anchor分配一个二进制的标签(前景/背景)。
2. SOFTMAX的两支
假设在conv5 后 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分 foreground 和 background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates。图4展示了 SOFTMAX的两支 。
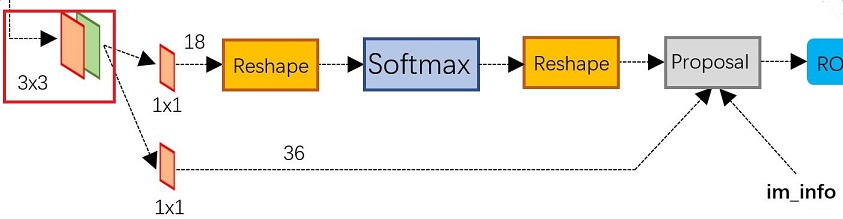
- 上面一支通过softmax分类anchors(9个框),获得positive(foreground)和negative(background)分类;
Anchor的标签分布配规则:
\quad
label: 1 is positive, 0 is negative, -1 is dont care
\quad
下面一支得到的只是anchor的4个坐标信息,在为每个anchor分配标签时,初始化标签都用-1来填充。(备注:-1表示无效,这类标签的数据不会对梯度更新起到帮助。)
\quad
- 我们分配正标签(前景)给两类anchor:
(1)与某个ground truth(GT)包围框有最高的IoU重叠的anchor(也许不到0.7);
(2)与任意GT包围框有大于0.7的IoU交叠的anchor。(注意:一个GT包围框可能分配正标签给多个anchor。)- 我们分配负标签(背景)给与所有GT包围框的IoU比率都低于0.3的anchor。
- 非正非负的anchor对训练目标没有任何作用。
经过标签分配环节后,最终输出维度为 2 × 9 = 18 2×9=18 2×9=18,一共18维。
\quad
补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
- 下面一支用于计算对于anchors的bounding box regression偏移量,以获得精确的候选框proposals。 对应于下面 3. Bounding Box Regression微调Region Proposal 部分的讲解。
在Faster RCNN算法中你肯定还会经常听到另一个名词:region proposal(或者简称proposal,或者简称ROI),可以说RPN网络的目的就是为了得到proposal,这些proposal是对ground truth更好的刻画(和Anchor相比,坐标更贴近ground truth,毕竟Anchor的坐标都是批量地按照scale和aspect ratio复制的)。
\quad
RPN网络的Bounding Box Regression回归支路的输出值(offset) 作为smooth损失函数的输入之一时,其含义就是使得proposal和anchor之间的offset(RPN网络的回归支路输出)尽可能与ground truth和anchor之间的offset接近。
3. Bounding Box Regression微调Region Proposal
前两步已经计算出 foreground anchors ,使用bounding box regression回归得到预设anchor-box到ground-truth-box之间的变换参数,即平移( d x 和 d y d_x 和 d_y dx和dy)和伸缩参数( d w 和 d h d_w 和 d_h dw和dh),由此得到初步确定的proposal。
Bounding Box Regression
\quad
如图5所示绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,那么即便红色框被分类器识别为飞机,但是由于红色框的定位不准,这张图相当于没有正确检测出飞机。所以,我们希望采用一种方法对红色框进行微调,使得foreground anchors和GT更加接近。值得推荐的方法就是 利用bounding box regression对 Region Proposal进行微调。 具体讲解参考:Faster RCNN原理篇(一)——Bounding-Box Regression边界框回归的学习和理解
图5 bounding box regression对Region Proposal进行微调

4. 剔除多余的proposal,得到最终的候选框
多余的候选框proposal的两种常见形式及处理方法:
(1)超出原始image边界的Proposal:
将初步确定的proposal利用feat_stride和im_info将anchors映射回原图,判断初步确定的proposal是否大范围超过边界,剔除严重超出边界的anchors。
(2)存在重合区域的Proposal:
按照softmax score进行从大到小排序,提取前2000个初步确定的proposal,对这2000个进行NMS(非极大值抑制),将得到的再次进行排序,输出前300个proposal。
NMS(非极大值抑制)的定义:
\quad
由于锚点经常重叠,因此初步确定的Proposal也会在同一个目标上重叠。为了解决候选框Proposal重叠的问题(如下图所示),我们提出一种简单的算法,称为非极大抑制(NMS)。
NMS(非极大值抑制)的具体方法:
- 将所有候选框proposal的得分进行排序,选中最高分及其所对应的Bounding Box;
- 遍历其余的候选框,如果它和当前最高得分框的重叠面积大于一定的阈值,我们就将其删除。
- 从没有处理的候选框中继续选择一个得分最高的,重复上述过程。总之,抑制的过程是一个
迭代-遍历-消除的过程。
最终剔除多余proposal的结果如下图所示:
参考链接:
(RegionProposal Network)RPN网络结构及详解


5、(Sample?)RPN典型算例
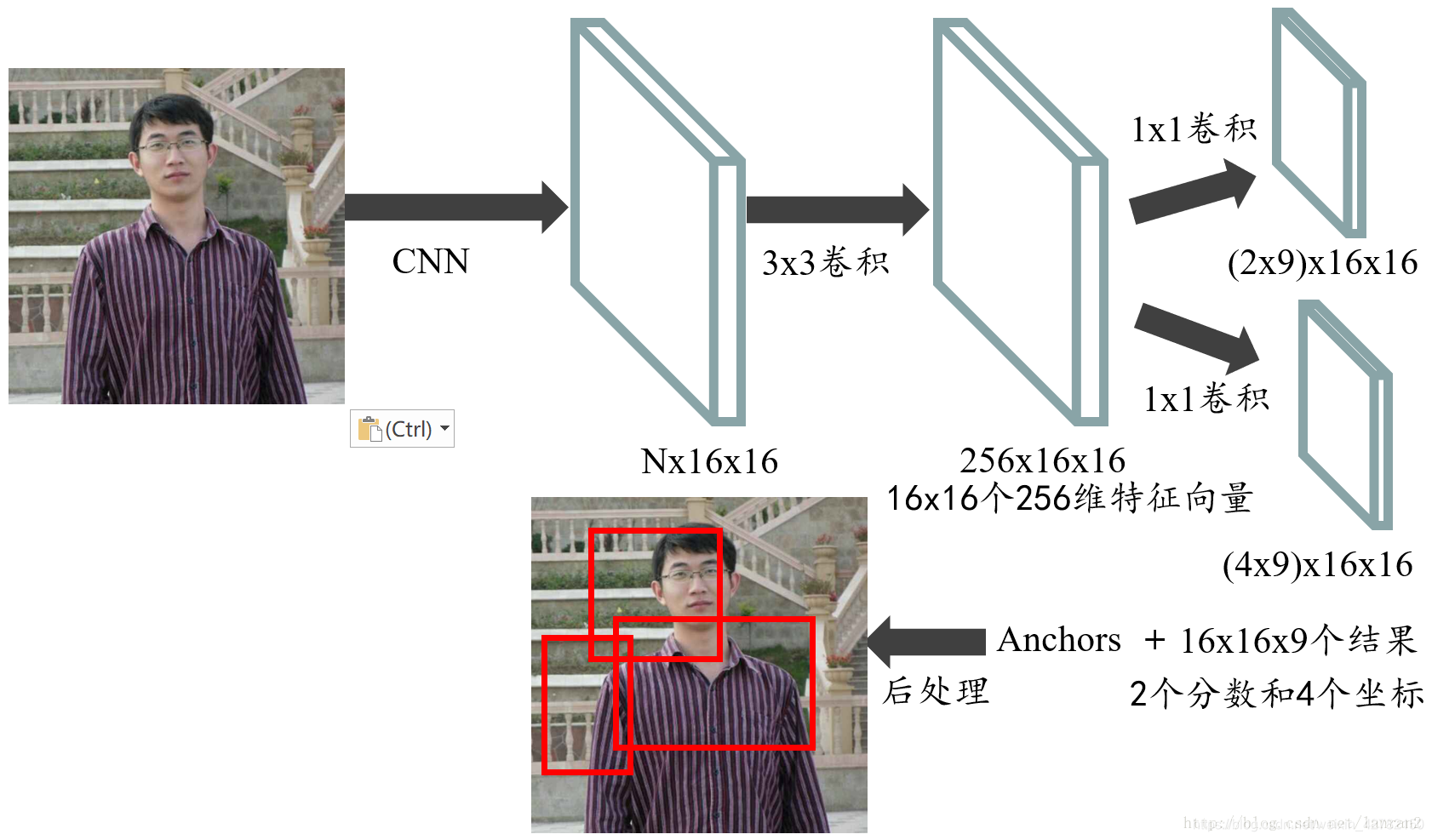
我们通过下述算例将RPN的整个流程走一遍。
- 首先通过一系列卷积得到共享特征图,假设它的大小是N x 16 x 16;
- 然后进入RPN阶段,首先经过一个3 x 3的卷积,得到一个256 x 16 x 16的特征图,也可以看作16 x 16个256维特征向量;
- 然后经过两次1 x 1的卷积,分别得到一个18 x 16 x 16的特征图,和一个36 x 16 x 16的特征图,也就是16 x 16 x 9个结果,每个结果包含2个分数和4个坐标,再结合预先定义的Anchors,经过后处理,就得到候选框;
整个流程如图6:
参考链接: 一文读懂Faster RCNN( 重点推荐!!!)
Anchors详解
1、(Why?)为何引入Anchor?
目标检测的实质是对候选框的回归,而网络不可能自动生成任意大小的候选框。因此,Anchor的主要意义: 根据feature map在原图片上划分出很多大小、宽高比不相同的矩形框,RPN会对这些框进行一个粗略的分类和回归,选取一些微调过的包含前景的正类别框以及包含背景的负类别框,送入之后的网络结构参与训练。
2、(What?)什么是Anchor?
提到RPN网络,就不能不说Anchors。所谓Anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形框。直接运行Faster RCNN源码中的generate_anchors.py可以得到以下输出:
## base_anchors的输出结果——每行的4个值代表矩形框左上和右下角点的坐标。
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
base_anchors是滑窗每滑到一个区域时生成的9个Anchor,base_anchors默认是 9 × 4 9×4 9×4的numpy array,表示9个Anchor的4个坐标值,4个坐标值是矩形框的左上角和右下角坐标。这9个Anchor有一个共同点是中心坐标点一样,这正好和RPN网络的滑窗操作对应(第一个 3 × 3 3×3 3×3的卷积层),滑窗每滑到一个 3 × 3 3×3 3×3区域,则以该区域中心点为坐标就会生成9个Anchor。
默认使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个anchor。虽然anchors是基于卷积特征图定义的,但最终的 anchors是相对于原始图片的。 实际上通过Anchors就引入了检测中常用到的多尺度方法。
在feature map上的每个特征点预测多个region proposals。假设滑窗所作用的对象是 W × H W×H W×H 的feature map,当 s t r i d e = 1 stride=1 stride=1 时,一共要滑动 W × H W×H W×H次,也就是一共会得到 W × H × 9 W×H×9 W×H×9 个Anchor。例如:对于像素点个数为 51×39 的一幅feature map上就会产生 51×39×9 个候选框。

3、 (How?) 如何生成Anchor?
1、源码解读
generate_anchors.py文件中generate_anchors函数源码解读:
通过对generate_anchors的解读,帮助 理解anchor的生成过程。
首先看generate_anchors.py文件的main函数
if __name__ == '__main__':
import time
t = time.time()
a = generate_anchors() #最主要的就是这个函数
print time.time() - t
print a
from IPython import embed; embed()
进入到generate_anchors函数中:
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2**np.arange(3, 6)):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window.
"""
base_anchor = np.array([1, 1, base_size, base_size]) - 1
print ("base anchors",base_anchor)
ratio_anchors = _ratio_enum(base_anchor, ratios)
print ("anchors after ratio",ratio_anchors)
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])
print ("achors after ration and scale",anchors)
return anchors
关于 generate_anchors函数的调用
generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2**np.arange(3, 6))
参数详解:
-
base_size=16这个参数 代表的是网络特征提取过程中图片缩小的倍数,和网络结构有关(即:base_size指定了最初类似感受野的区域大小,因为经过多层卷积、池化之后,feature map上一点的感受野对应到原始图像将会是一个区域)。这里设置base_size=16,表明feature map上一个像素点可以映射到原图上的区域大小为 16 × 16 16 ×16 16×16。当然,base_size的值也可以根据需要自己设置。 -
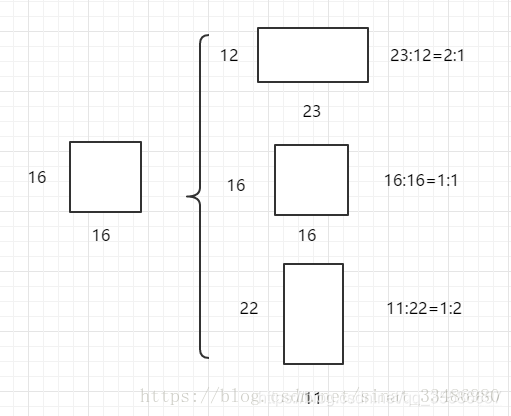
ratios=[0.5,1,2]表示:ratios of generated anchors, 这个参数 指的是要将16x16的区域,按照1:2,1:1,2:1三种比例进行变换,如下图所示:
-
scales=2**np.arange(3, 6)功能:used to generate anchors, affects num_anchors (per location), 这个参数 指的是要将输入区域的宽和高进行8,16,32三种倍数的放大(备注: 放大倍数满足函数 2 n 2^n 2n,当 n n n依次取值 3 , 4 , 5 3, 4, 5 3,4,5时,即得到预期的放大倍数)。例如:将 16 × 16 16×16 16×16的区域变成 ( 16 × 8 ) × ( 16 × 8 ) = 128 × 128 (16×8)×(16×8)=128×128 (16×8)×(16×8)=128×128的区域, ( 16 × 16 ) × ( 16 × 16 ) = 256 × 256 (16×16)×(16×16)=256×256 (16×16)×(16×16)=256×256的区域,以及 ( 16 × 32 ) × ( 16 × 32 ) = 512 × 512 (16×32)×(16×32)=512×512 (16×32)×(16×32)=512×512的区域,如下图所示: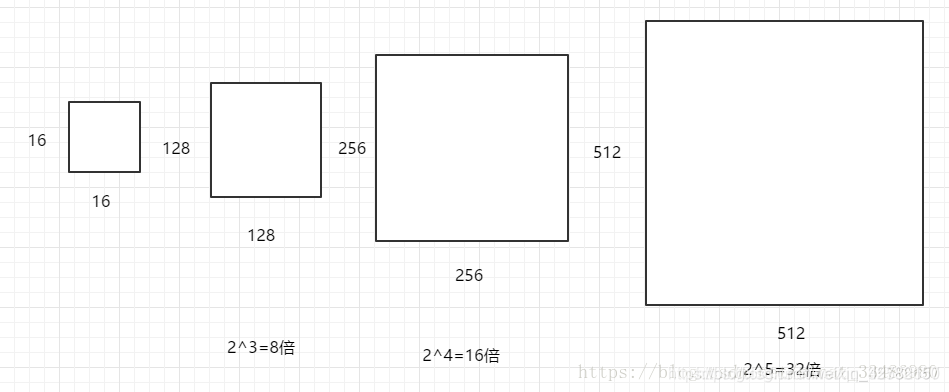
2、Anchor的生成过程
anchor的生成过程:
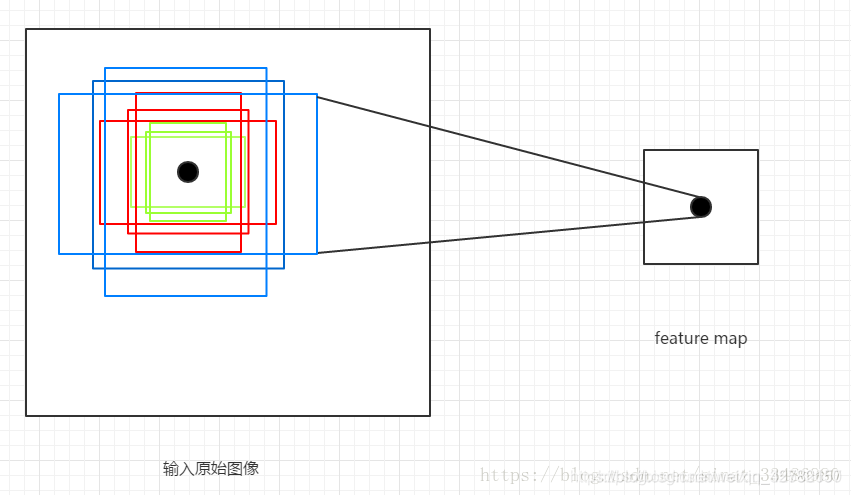
通过以上三个参数,针对于feature map上的任意一个像素点,将执行如下操作:
- 首先,将feature map上的某一个像素点映射到原图片上一个 16 × 16 16× 16 16×16 的区域;
- 然后,以这个区域的中心点作为变换中心,将其变为三种宽高比的区域,再分别对这三种区域的面积扩大8,16,32倍,最终一个像素点对应到了原图的9个不同的矩形框,这些框就叫做
Anchor,如下图:
注意: 将不完全在图像内部(初始化的anchor的4个坐标点超出图像边界)的Anchor都过滤掉,一般过滤后只会有原来1/3左右的Anchor。如果不将这部分Anchor过滤,则会使训练过程难以收敛。
参考链接:
faster R-CNN中anchors 的生成过程(generate_anchors源码解析)
Faster RCNN代码详解(四):关于anchor的前世今生
附录:Netscope可视化网络结构
推荐一个可视化网络神器:Netscope:在线可视化网络结构

赠人玫瑰,手留余香!!!您的点赞和关注是对良心原创者最大的鼓励和支持~