在Faster R-CNN的区域生成网络RPN中为了能够以目标真实框(Ground Truth box)为监督信号去训练RPN网络依据anchor预测proposal的位置,作者并不是直接回归proposal的(x,y,w,h),而是采用了以下形式的参数化坐标偏移向量
,其具体计算公式如下:
其中(x,y,w,h)代表预测的proposal的坐标参数,
代表anchor的坐标参数,
代表真实框的坐标参数。
之所以这么做个人觉得有两点原因:
-
这里是要依据anchor去预测proposal的位置,而anchor并非真实框,所以没办法直接对坐标参数进行回归,而是转而利用proposal与anchor的偏差(offset,t向量)去回归anchor与真实框的偏差(t*向量)。这就是上面公式中为什么出现 和 的原因。
-
关于上面公式的原理可以详细看下一文读懂Faster RCNN-知乎中bounding box regression原理部分以及边框回归详解这篇博客。假定可以对anchor进行修正使其尽可能接近真实框,则只要对anchor进行平移和缩放即可。
设 为anchor的中心点坐标和宽、高, 为对anchor修正后接近真实框的相应位置参数,则- 平移变换可以用下式表示
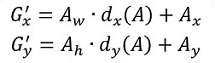
上面乘以anchor的宽、高是为了保证学习到的变换参数具有尺度不变性,因为这些变换参数学习完成后是固定的,而要预测的目标框却有大有小,乘以anchor的宽、高后就能实现对目标尺寸的自适应 - 缩放变换可以用下式表示
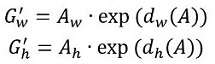
上面取了指数是为了保证缩放倍数是大于0的
实际上就是相应的平移和缩放参数 ,也是RPN网络回归部分要学习的目标。
- 平移变换可以用下式表示
关于Faster R-CNN的学习资料,除了上面链接中的从原理上详细解释Faster R-CNN的那一篇外,还有就是从代码实现的角度讲解Faster R-CNN的从编程实现角度学习Faster R-CNN(附极简实现),希望对想弄清楚Faster R-CNN原理的朋友有所帮助。