机器学习:回归
1. 线性回归
有一组数据:(x,y)
找出一个线性方程,使得数据到线上的距离总和最小。
距离最小化:梯度下降法/最小二乘法……
对于普通最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这种特性导致最小二乘估计对于随机误差非常敏感,可能产生很大的方差,W过大,就会导致模型过拟合。(即,输入的数据的特征之间,越独立越好)
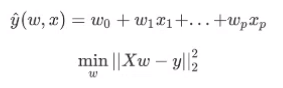
2. 岭回归
加了个L2正则项来约束w,使得w尽量小。(防止过拟合)
α是正则项的系数。
L2的本质就是高斯分布作为w的先验推断而来的。
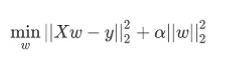
尽量把用处小的特征的权重变小。

3. LASSO回归
加了个L1正则项来约束w。
L2的本质就是拉普拉斯分布作为w的先验推断而来的。
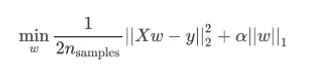
将用处小的特征直接去掉(权重降为0)。

4. 弹性网络
L1,L2正则化混用。
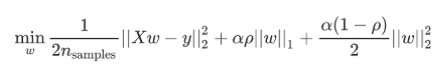
5. 逻辑斯蒂回归
对数据进行压缩,使得异常点对整体数据的影响变小。
本质是在对wx增加了一个非线性函数(激活函数),增加了非线性能力,可以拟合曲线。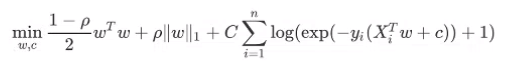
(压缩可以是不同形式的压缩)
逻辑斯蒂回归的本质就是用sigmoid对数据进行压缩,使得数据都集中在0-1的范围内。

from sklearn import linear_model
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score, explained_variance_score
x,y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10, random_state=0) # 造一组回归样本
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0) # 划分训练集和测试集
reg = linear_model.LinearRegression() # 创建线性回归
# reg = linear_model.Ridge() # L2正则化 岭回归
# reg = linear_model.Lasso() # L1正则化 LASSO回归
# reg = linear_model.ElasticNet() #L1,L2正则化混用 弹性网络
# reg = linear_model.LogisticRegressiong() # 逻辑斯蒂回归
# reg = linear_model.BayesianRidge() # 贝叶斯岭回归
reg.fit(x_train, y_train) #
print(reg.coef_, reg.intercept_) # w,b
y_pred = reg.predict(x_test) # 预测
# 回归评估指标
print(mean_squared_error(y_test, y_pred)) # 均方误差
print(mean_absolute_error(y_test, y_pred)) # 平均绝对误差
print(r2_score(y_test, y_pred)) # R2评分
print(explained_variance_score(y_test, y_pred)) # 可解释方差
_x = np.array([-2.5, 2.5])
#_y = reg.coef_ * _x + reg.intercept_ # y = wx+b
_y = reg.predict(_x[:,None])
plt.scatter(x_test, y_test)
plt.plot(_x, _y, linewidth=3, color="orange")
plt.show()

6. 核岭回归
核岭回归:核(激活)+岭(正则化)
使用不同的核函数对wx进行激活。核的功能是提供非线性能力,提升方程的维度。
常用的核函数有:普通线性(无激活),多项式核,高斯核(rbf/径向基核),sigmoid核。
import numpy as np
from sklearn.kernel_ridge import KernelRidge
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
rng = np.random.RandomState(0)
X = 5 * rng.rand(100, 1)
y = np.sin(X).ravel()
y[::5] += 3* (0.5 - rng.rand(X.shape[0] // 5))
# kr = KernelRidge(kernel='rbf',gamma=0.4)
# 表格搜索:找到最优的参数
kr = GridSearchCV(KernelRidge(),
param_grid={
"kernel":["rbf","laplacian","polynomial","sigmoid"],
"alpha":[1e0, 0.1, 1e-2, 1e-3],
"gamma":np.logspace(-2, 2, 5)
})
kr.fit(X, y)
print(kr.best_score_, kr.best_params_)
X_plot = np.linspace(0, 5, 100)
y_kr = kr.predict(X_plot[:,None])
plt.scatter(X, y)
plt.plot(X_plot, y_kr, linewidth=3, color="orange")
plt.show()

7. SVR(支持向量回归)
岭回归使用的优化算法是SGD(随机梯度下降法);SVR使用的优化算法是凸优化。
SVR原理:找到一个判别面(超平面),使得超平面到最远样本点的距离最小。(最远的点,即边界上的点叫做支持向量)
同样可以通过加核函数,得到非线性化能力。
拉格朗日乘子法:将目标函数核约束条件连接起来。

svr = SVR(kernel='rbf', C=10, gamma=0.1)