一、前言
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的).论文下载 Very Deep Convolutional Networks for Large-Scale Image Recognition。论文主要针对卷积神经网络的深度对大规模图像集识别精度的影响,主要贡献是使用很小的卷积核(3×3)构建各种深度的卷积神经网络结构,并对这些网络结构进行了评估,最终证明16-19层的网络深度,能够取得较好的识别精度。 这也就是常用来提取图像特征的VGG-16和VGG-19。
VGG可以看成是加深版的AlexNet,整个网络由卷积层和全连接层叠加而成,和AlexNet不同的是,VGG中使用的都是小尺寸的卷积核(3×3)。
二、VGG的特点
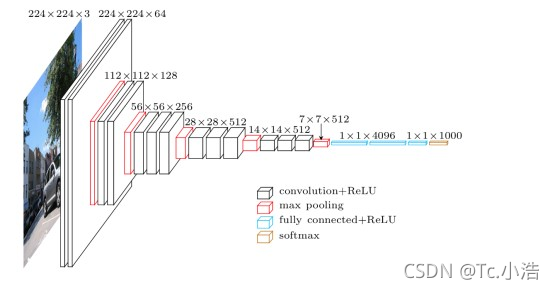
- 结构简洁,如下图VGG-16的网络结构
对比,前文介绍的AlexNet的网络结构图,是不是有种赏心悦目的感觉。整个结构只有3×3的卷积层,连续的卷积层后使用池化层隔开。虽然层数很多,但是很简洁。
- 小卷积核和连续的卷积层
VGG中使用的都是3×3卷积核,并且使用了连续多个卷积层。这样做的好处:
- 使用连续的的多个小卷积核(3×3),来代替一个大的卷积核(例如(5×5)。
使用小的卷积核的问题是,其感受野必然变小。所以,VGG中就使用连续的3×3卷积核,来增大感受野。VGG认为2个连续的3×3卷积核能够替代一个5×5卷积核,三个连续的3×3能够代替一个7×7。
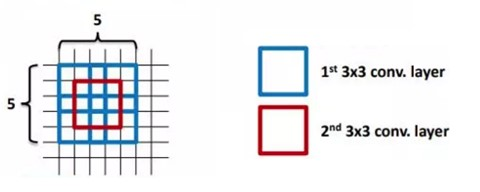
CNN感受野:
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptive field)。通俗解释为:输出feature map 上的一个单元对应输入层上的区域大小。
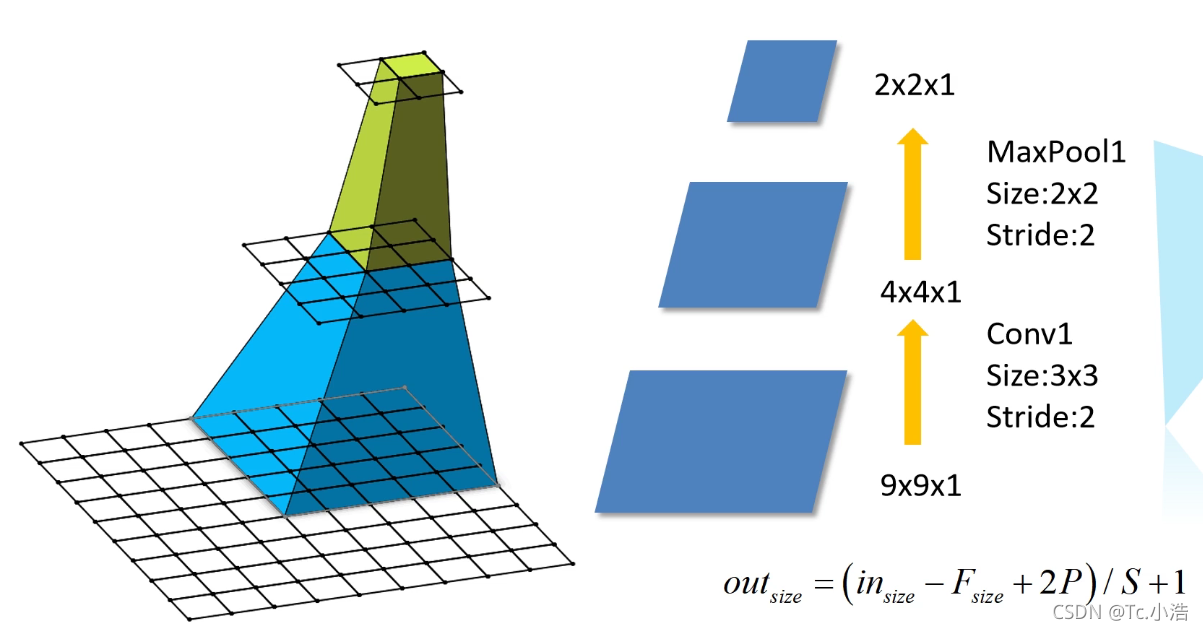
最上面一层为1x1,对应最后一层感受野为5x5
感受野计算
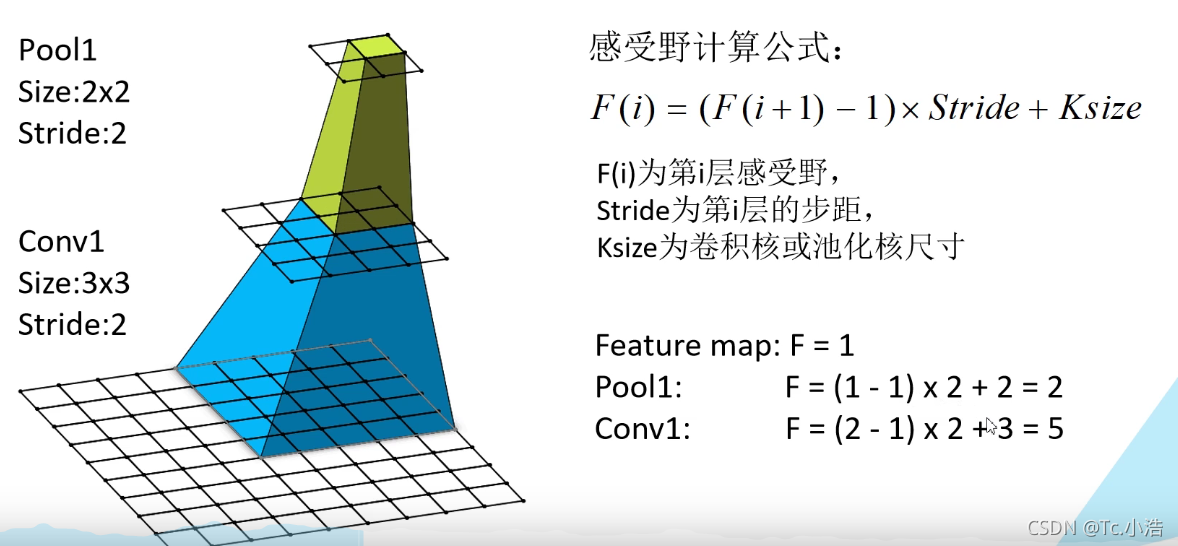
特征层为第三层,f(3)=1,表示只有一个单元特征。则第二层感受野为f(2)=(f(3)-1)x2+2=2,第一层感受野为:f(1)=(f(2)-1)x2+3=5。
下图证明了3个3x3的卷积核可以代替一个7x7的卷积核
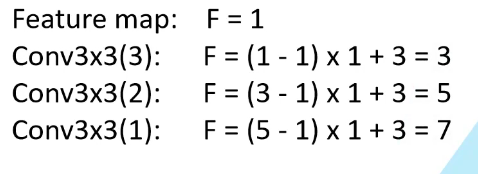
参数减少
使用7x7卷积核所需参数,与堆叠三个3x3卷积核所需参数(假设输入输出channel为C)
7x7xCxC=49 C 2 C^2 C2
3x3xCxC+3x3xCxC+3x3xCxC=27 C 2 C^2 C2
- 小卷积核的参数较少。3个3×3的卷积核参数为3×3×3=27,而一个7×7的卷积核参数为 7×7=49
- 由于每个卷积层都有一个非线性的激活函数,多个卷积层增加了非线性映射。
- 小池化核,使用的是2×2
- 通道数更多,特征度更宽。
每个通道代表着一个FeatureMap,更多的通道数表示更丰富的图像特征。VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。 - 层数更深
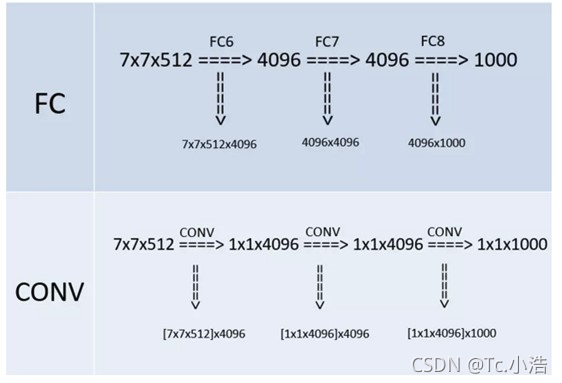
使用连续的小卷积核代替大的卷积核,网络的深度更深,并且对边缘进行填充,卷积的过程并不会降低图像尺寸。仅使用小的池化单元,仅使用小的池化单元,降低图像的尺寸。 - 全连接转卷积(测试阶段)
这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
如本节第一个图所示,输入图像是224x224x3,如果后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。
VGG网络结构
VGG网络相比AlexNet层数多了不少,但是其结构却简单不少。
- VGG的输入为224×224×3的图像
- 对图像做均值预处理,每个像素中减去在训练集上计算的RGB均值。
- 网络使用连续的小卷积核(3×3)做连续卷积,卷积的固定步长为1,并在图像的边缘填充1个像素,这样卷积后保持图像的分辨率不变。
- 连续的卷积层会接着一个池化层,降低图像的分辨率。空间池化由五个最大池化层进行,这些层在一些卷积层之后(不是所有的卷积层之后都是最大池化)。在2×2像素窗口上进行最大池化,步长为2。
- 卷积层后,接着的是3个全连接层,前两个每个都有4096个通道,第三是输出层输出1000个分类。
- 所有的隐藏层的激活函数都使用的是ReLU
- 使用1×1的卷积核,为了添加非线性激活函数的个数,而且不影响卷积层的感受野。
- 没有使用局部归一化,作者发现局部归一化并不能提高网络的性能。
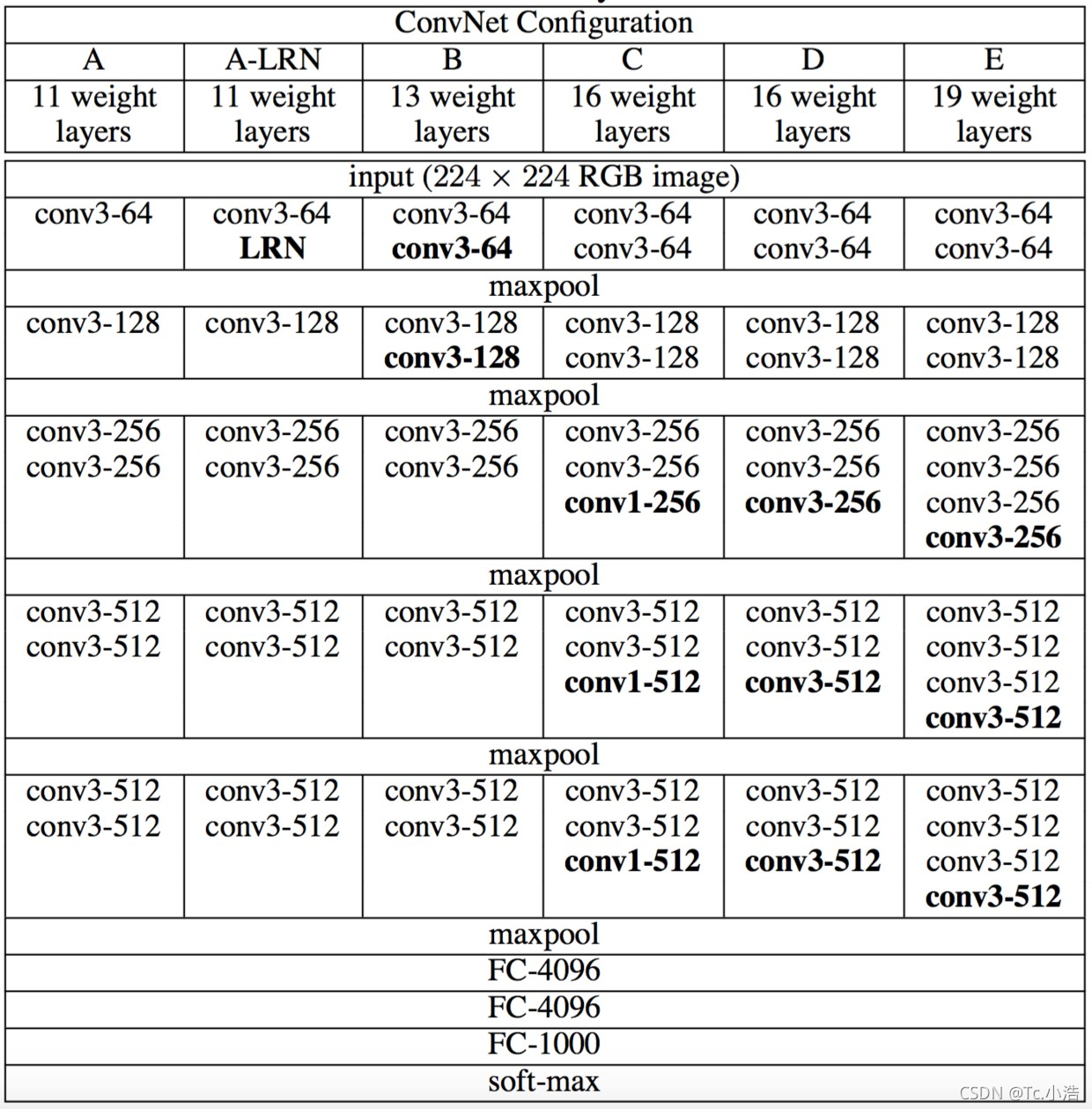
所有网络结构都遵从上面提到的设计规则,并且仅是深度不同,也就是卷积层的个数不同:从网络A中的11个加权层(8个卷积层和3个FC层)到网络E中的19个加权层(16个卷积层和3个FC层)。卷积层的宽度(通道数)相当小,从第一层中的64开始,然后在每个最大池化层之后增加2倍,直到达到512。
上图给出了各个深度的卷积层使用的卷积核大小以及通道的个数。最后的D,E网络就是大名鼎鼎的VGG-16和VGG-19了。
AlexNet仅仅只有8层,其可训练的参数就达到了60M,VGG系列的参数就更恐怖了,如下图(单位是百万)

由于参数大多数集中在后面三个全连接层,所以虽然网络的深度不同,全连接层是相同的,其参数区别倒不是特别的大。