将MySql数据存储到Neo4j中
1、将MySql数据导出到csv格式的文件中
待输出的数据库见:
https://blog.csdn.net/weixin_41104835/article/details/88615445
into outfile ‘导出的目录和文件名’
指定导出的目录和文件名
fields terminated by ‘字段间分隔符’
定义字段间的分隔符
optionally enclosed by ‘字段包围符’
定义包围字段的字符(数值型字段无效)
- 输出genre表对应的csv格式数据
在数据库中执行以下语句:
F:/AZtools/kgData/kg_genre.csv :期望将导出的数据存储在该位置
SELECT * FROM genre into outfile 'F:/AZtools/kgData/kg_genre.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
- 出现问题1:
The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
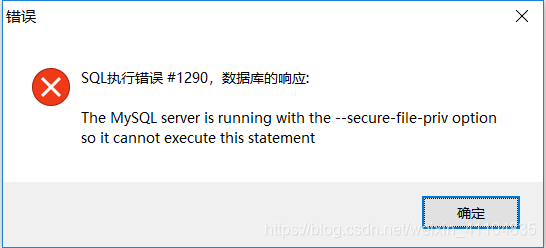
- 解决方案1:
原因:在安装MySQL的时候限制了导入与导出的目录权限,只能在规定的目录下才能导入,需要通过下面命令查看 secure-file-priv 当前的值是什么,即:
show variables like '%secure%';
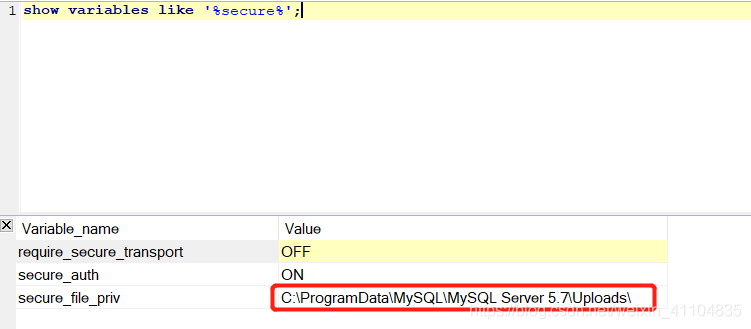
- 将以上进行输出的语句转换为:
SELECT * FROM genre into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/kg_genre.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
- 出现问题2:输出文件数据乱码
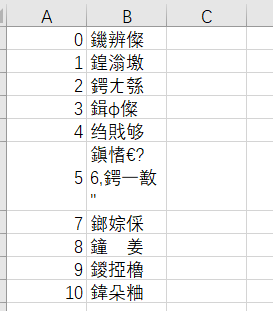
- 解决方案2:
1.kg_movie中表是utf8编码,excel默认编码格式是GBK,excel直接打开时候是一堆乱码。可以先保存成为txt格式,excel打开txt时候会提示选择用哪种编码方式打开,选择utf8解决
2.导出时候加上CHARACTER SET gbk 即可【推荐使用】,即:
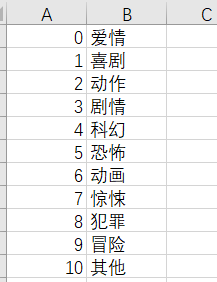
最终正确的输入:
SELECT * FROM genre into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/kg_genre.csv' character set gbk fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
结果如下:
- 输出actor表对应的csv格式文件
SELECT * FROM actor into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/kg_actor.csv' character set gbk fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
- 输出movie表对应的csv格式文件
SELECT * FROM movie into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/kg_movie.csv' character set gbk fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
- 输出actor_to_movie表对应的csv格式文件
SELECT * FROM actor_to_movie into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/kg_actor_to_movie.csv' character set gbk fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
- 输出movie_to_genre表对应的csv格式文件
SELECT * FROM movie_to_genre into outfile 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/kg_movie_to_genre.csv' character set gbk fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
- 最终输出的文件如下:
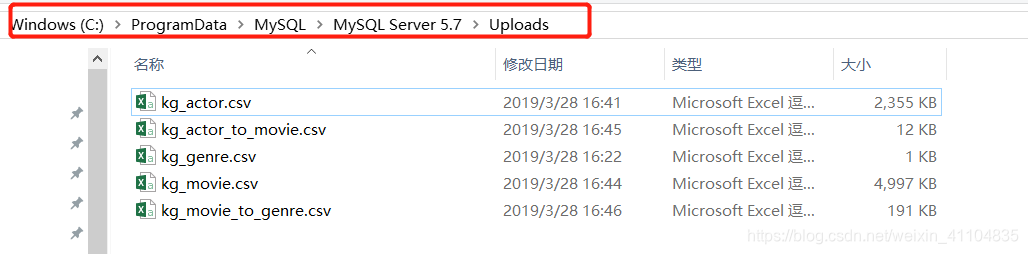
2、将CSV格式文件导入Neo4j数据库中
- 将上述csv格式的文件移到neo4j的import目录下,因为Neo4j默认是从打开import目录下的文件。对于本地文件,该路径默认为 import 文件夹,要想读取其他文件夹下的文件,需要修改配置文件才可以。数据文件如下:
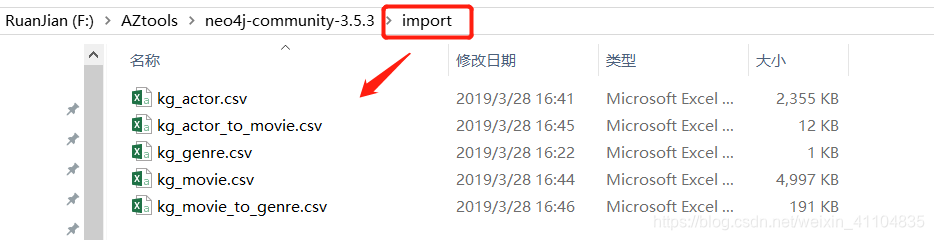
- 运行neo4j
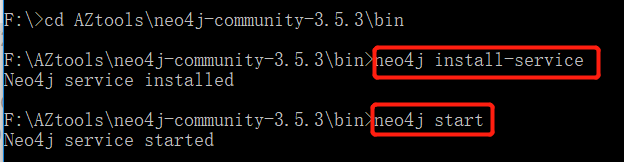
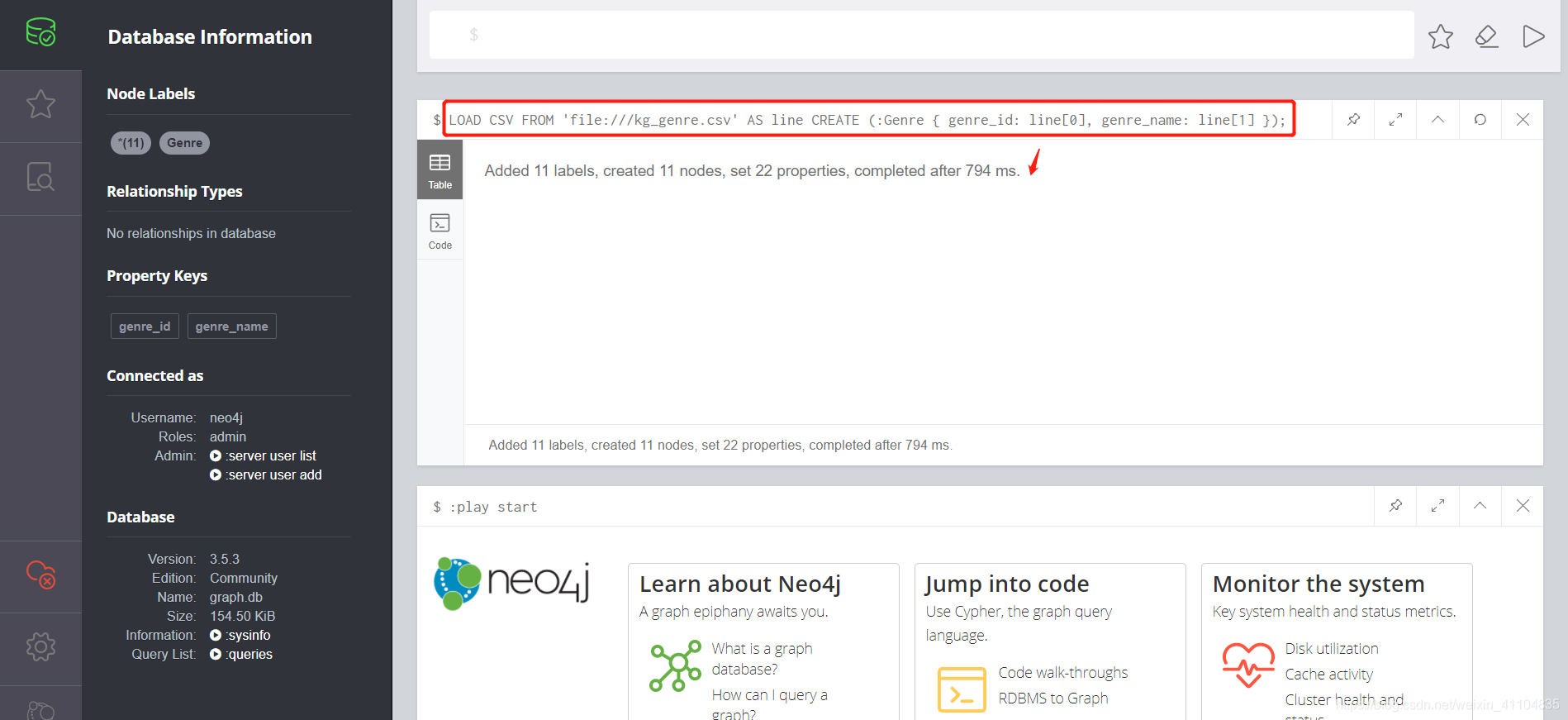
- 节点文件genre的载入
LOAD CSV FROM 'file:///kg_genre.csv' AS line CREATE (:Genre { genre_id: line[0], genre_name: line[1] });
结果如下:
- 出现问题,节点乱码(到这一步想起来上面的问题了,把自己坑了。。。。。。。。。。)
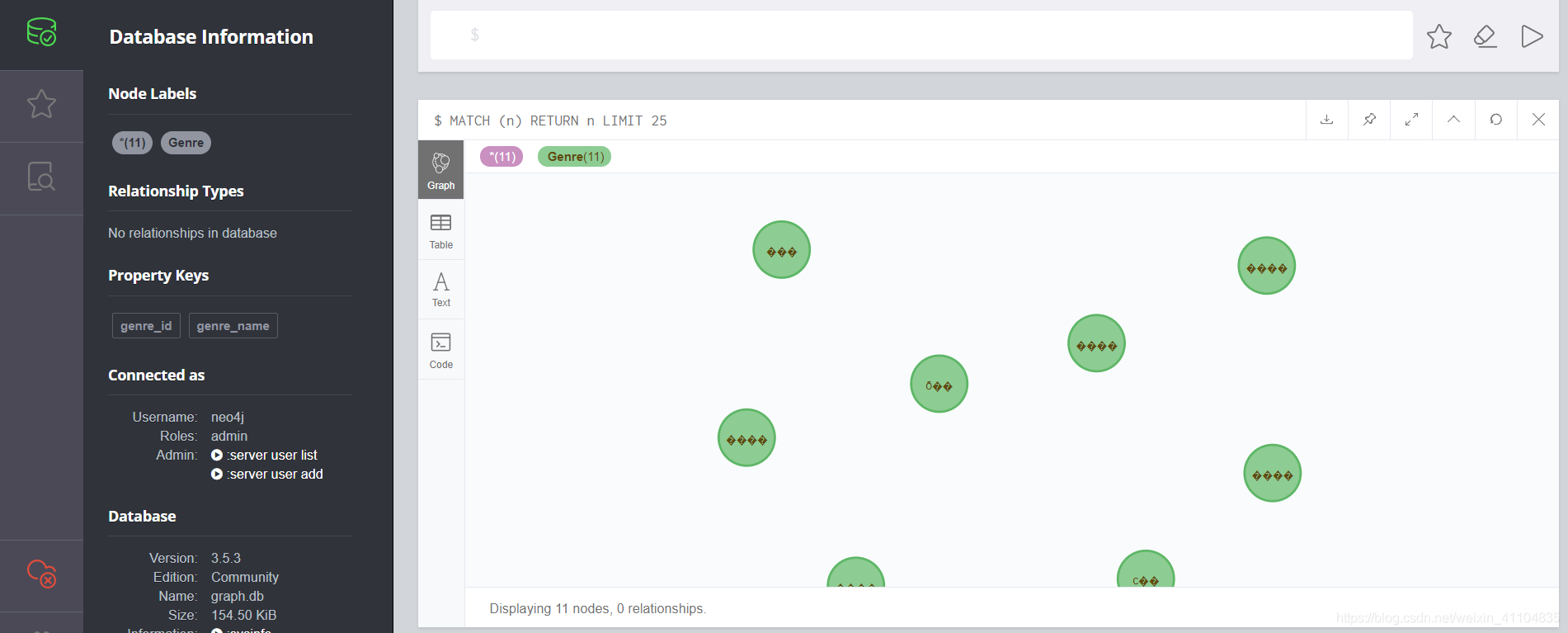
- 解决方案
mysql中utf-8编码,excel中gbk编码,而Neo4j中是utf-8编码,为了在excel中不显示乱码,把格式改成了gbk,可是存入neo4j中会乱码的啊!!!
所以,保存csv格式的时候,应保存utf-8编码,不要管它在excel中乱码了!!!!
又要重新把gbk改回utf8了。。。。。。。
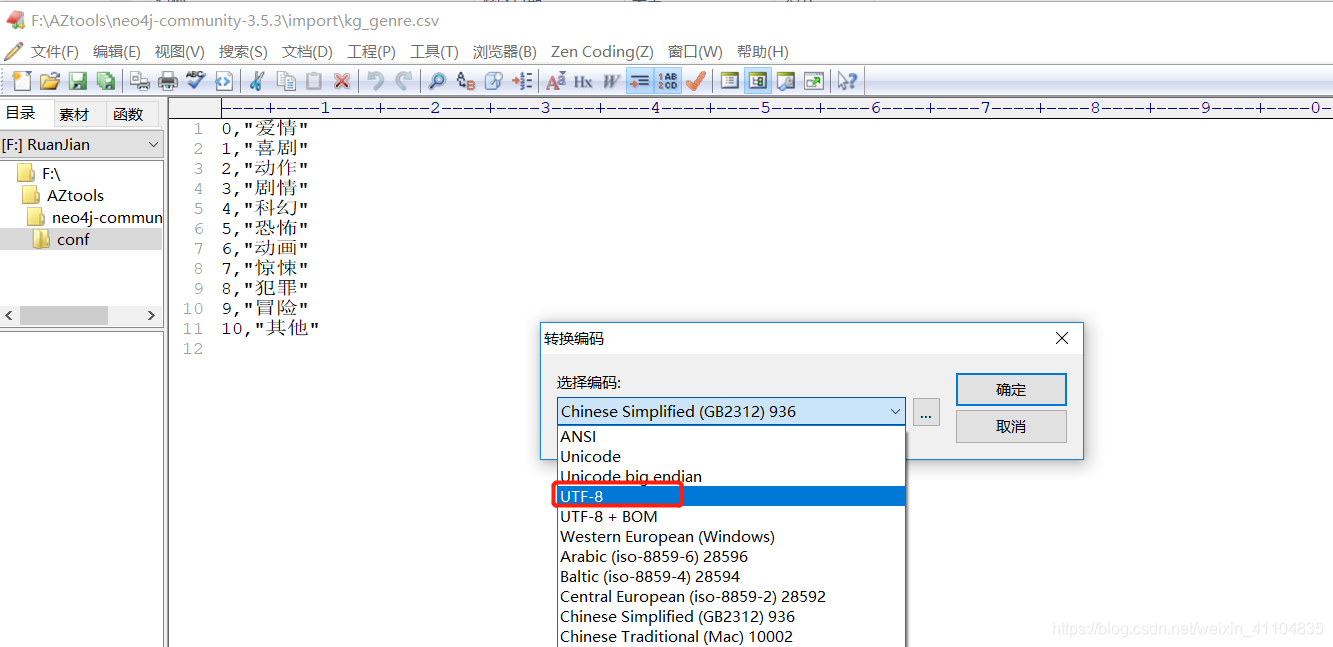
- 结果如下:
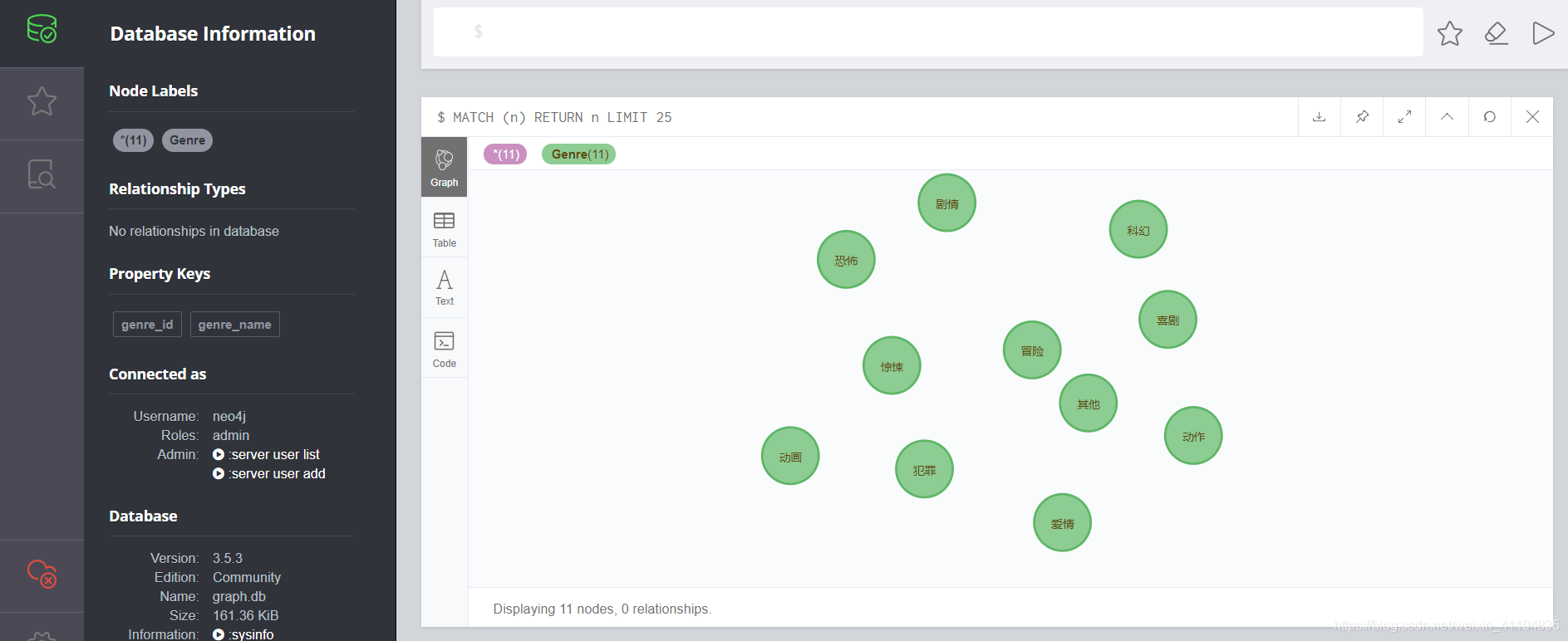
为了更好的管理数据,我重新创建了一个数据库kg_movie,当然也可以不创建,直接在默认的graph.db数据库中操作即可。
在databases下创建数据库文件夹:
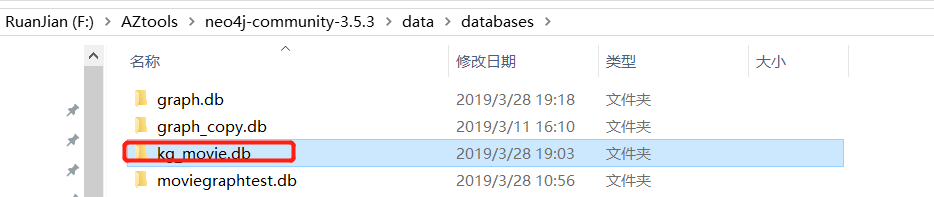
修改配置文件:
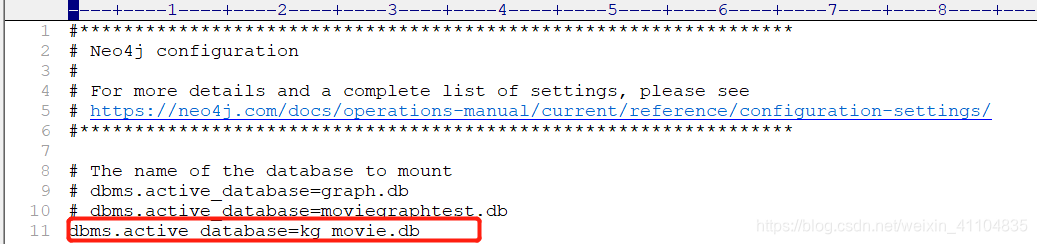
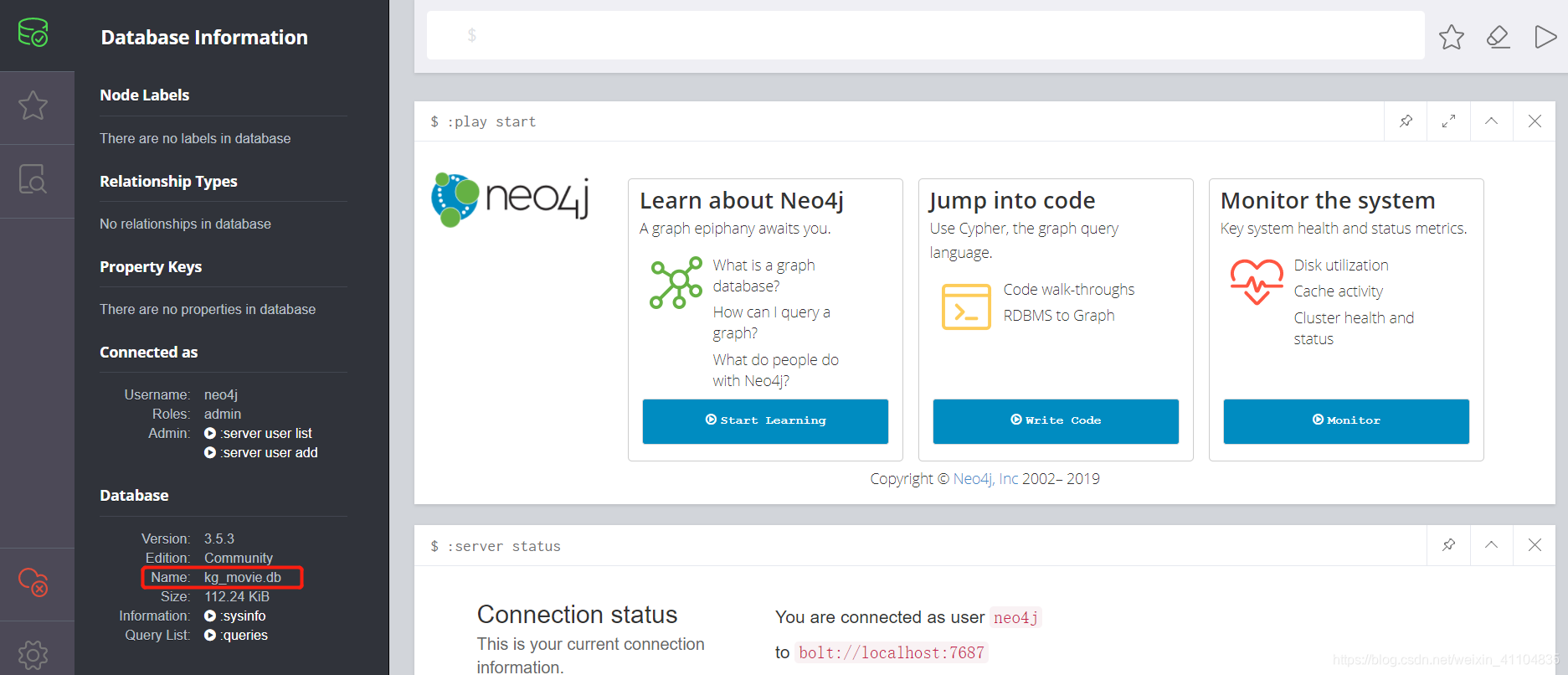
进入浏览器http://localhost:7474/browser/,即可见如下结果:
节点文件载入
在重新创建的数据库kg_movie.db中载入节点和关系文件
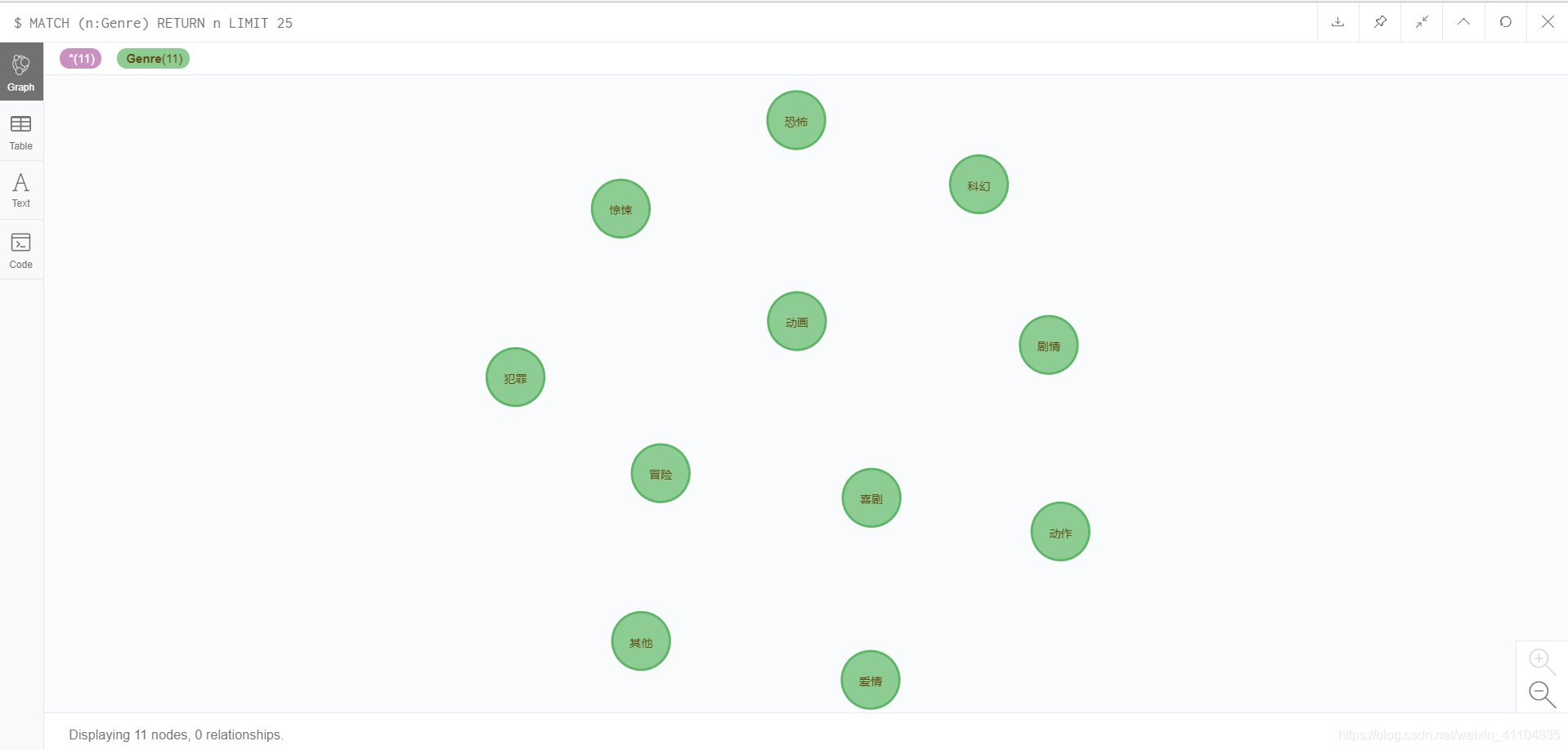
- 节点文件genre的载入
USING PERIODIC COMMIT 100
LOAD CSV FROM 'file:///kg_genre.csv' AS line CREATE (g:Genre { genre_id: line[0], genre_name: line[1] });
USING PERIODIC COMMIT 100:使用自动提交,每满100条提交一次,防止内存溢出
结果:
删除Genre节点:
Match(n:Genre) Detach
Delete n
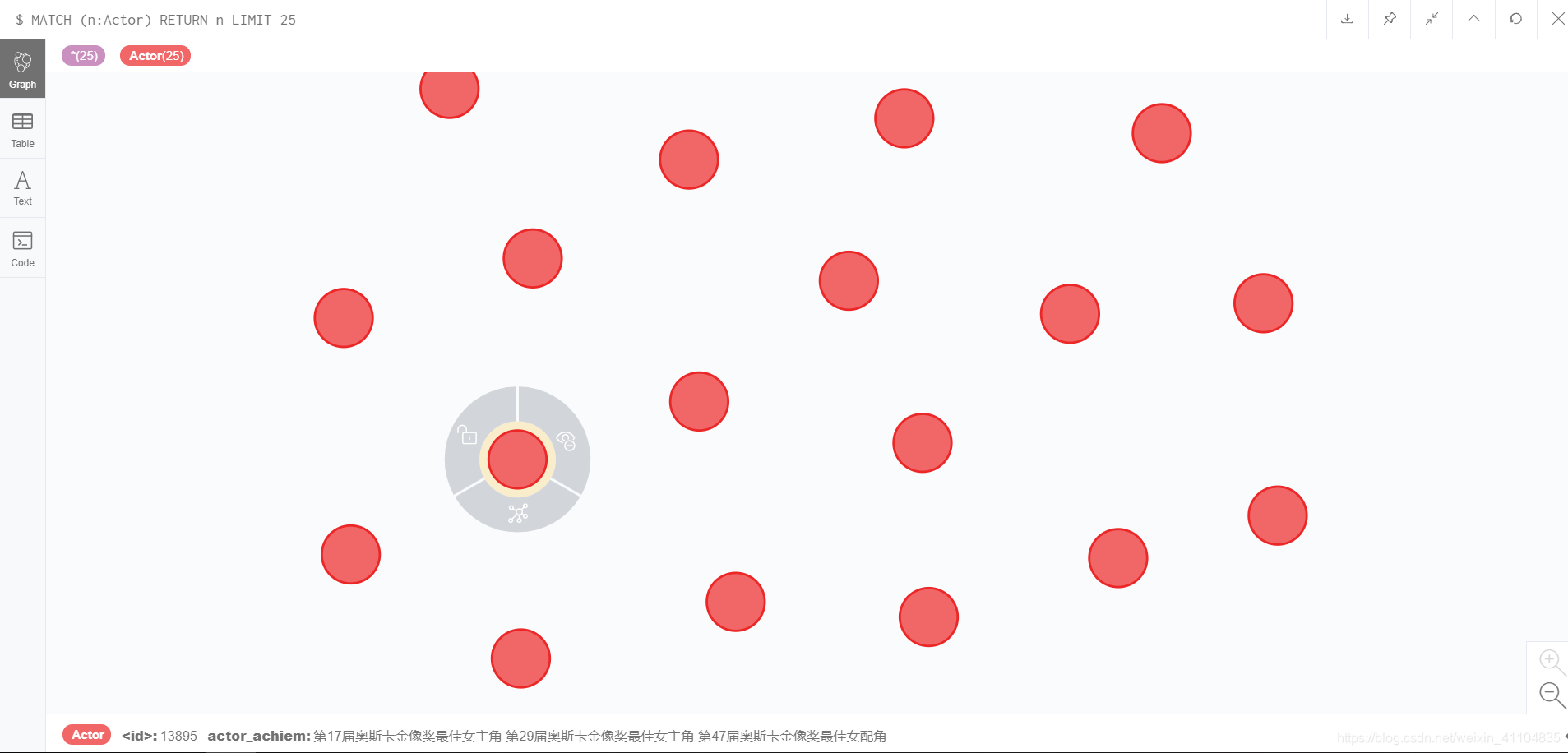
- 节点文件actor的载入
节点的标签为 :Actor,节点的属性为 花括号{} 包起来的部分
USING PERIODIC COMMIT 100
LOAD CSV FROM 'file:///kg_actor.csv' AS line CREATE (a:Actor { actor_id: line[0], actor_bio: line[1], actor_chName: line[2], actor_foreName: line[3],actor_nationality: line[4], actor_constellation: line[5], actor_birthPlace: line[6], actor_birthDay: line[7], actor_repWorks: line[8], actor_achiem: line[9], actor_brokerage: line[10] })
结果:
Added 5932 labels, created 5932 nodes, set 65252 properties, completed after 2541 ms.
删除Actor节点语句:
Match(n:Actor) Detach
Delete n
- 节点文件movie的载入
USING PERIODIC COMMIT 100
LOAD CSV FROM 'file:///kg_movie.csv' AS line CREATE (m:Movie { movie_id: line[0], movie_bio: line[1], movie_chName: line[2], movie_foreName: line[3],movie_prodTime: line[4], movie_prodCompany: line[5], movie_director: line[6], movie_screenwriter: line[7], movie_genre: line[8], movie_star: line[9], movie_length: line[10], movie_rekeaseTime: line[11], movie_language: line[12], movie_achiem: line[13] });
结果:
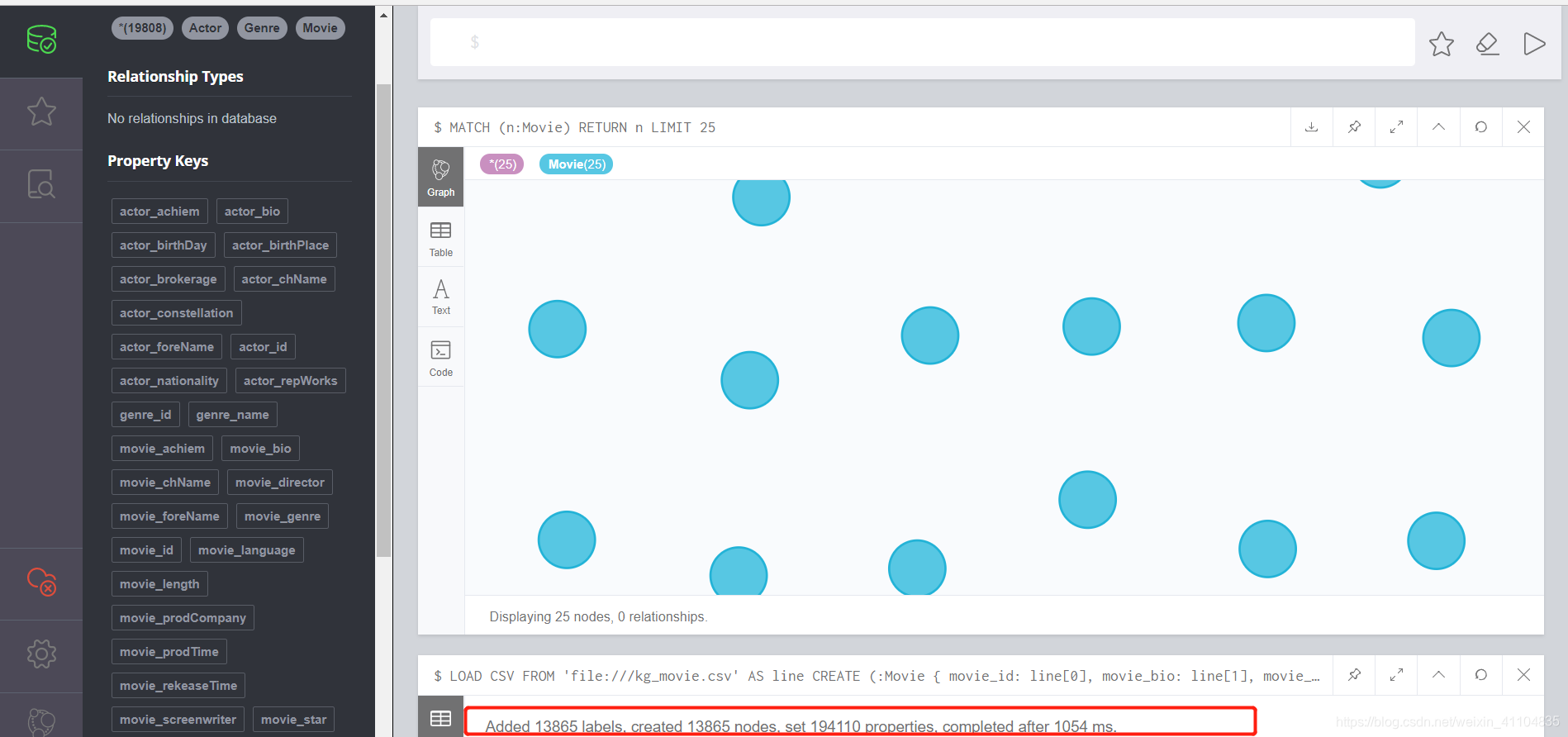
关系文件载入
前面我们只是建立的演员和电影的节点,并没有关系链接它们。关系在 MYSQL中 对应于 actor_to_movie 表 和 movie_to_genre 表,分别对应 演员 :ACTED_IN 电影 的关系 和 电影 :Belong_to 类别 关系。
- 关系文件actor_to_movie的载入
USING PERIODIC COMMIT 300
LOAD CSV FROM 'file:///kg_actor_to_movie.csv' AS line MATCH (a:Actor), (m:Movie) WHERE a.actor_id = line[1] AND m.movie_id = line[2] CREATE (a) - [r:ACTED_IN] -> (m) RETURN r;
结果:
Created 800 relationships, started streaming 800 records after 27977 ms and completed after 28091 ms.
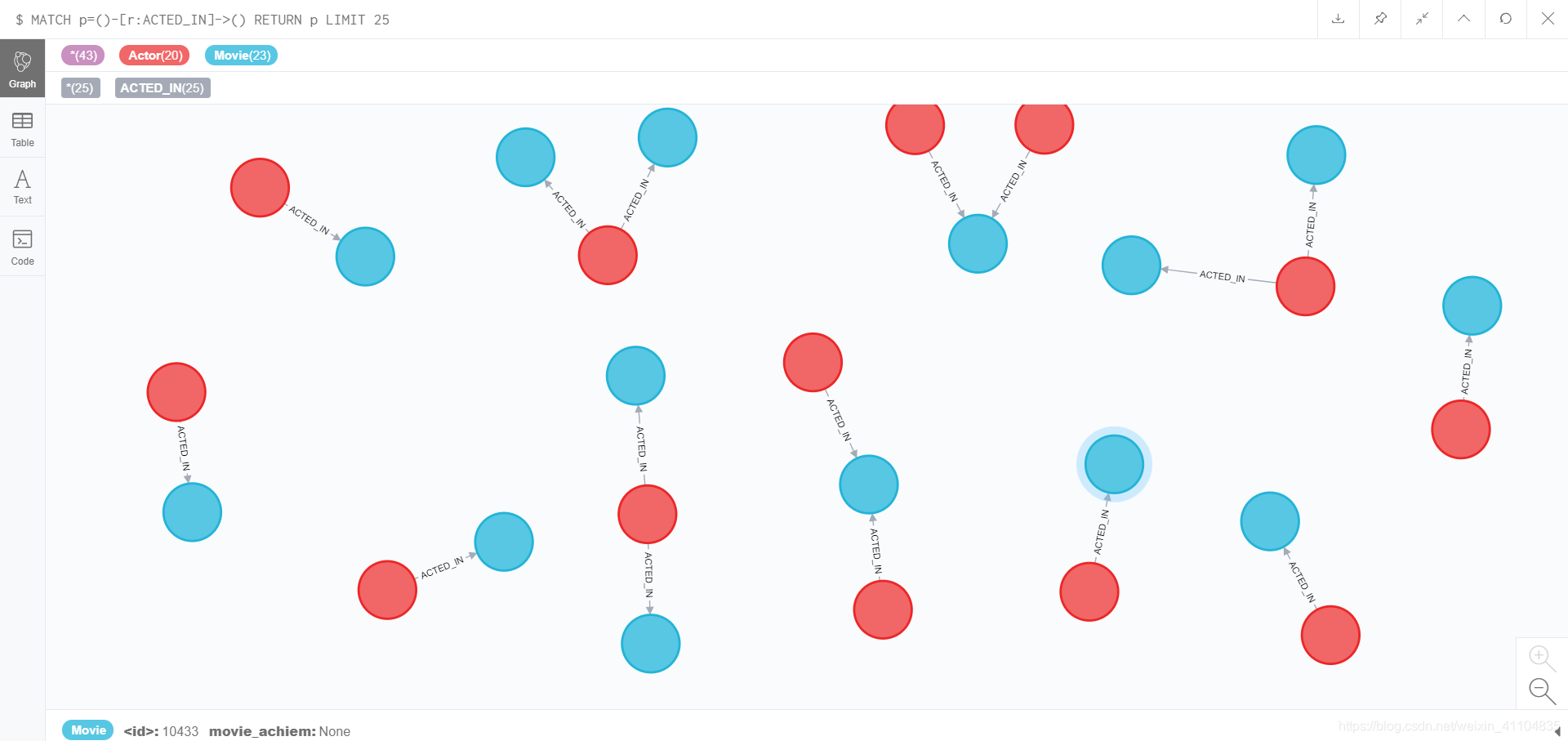
删除ACTED_IN关系
match (p)-[r:ACTED_IN]-()
detach delete r
- 关系文件movie_to_genre的载入
USING PERIODIC COMMIT 300
LOAD CSV FROM 'file:///kg_movie_to_genre.csv' AS line MATCH (m:Movie), (g:Genre) WHERE m.movie_id = line[1] AND g.genre_id = line[2] CREATE (m) - [r:Belong_to] -> (g) RETURN r;
结果:
Created 14558 relationships, started streaming 14558 records after 411664 ms and completed after 411812 ms, displaying first 1000 rows.
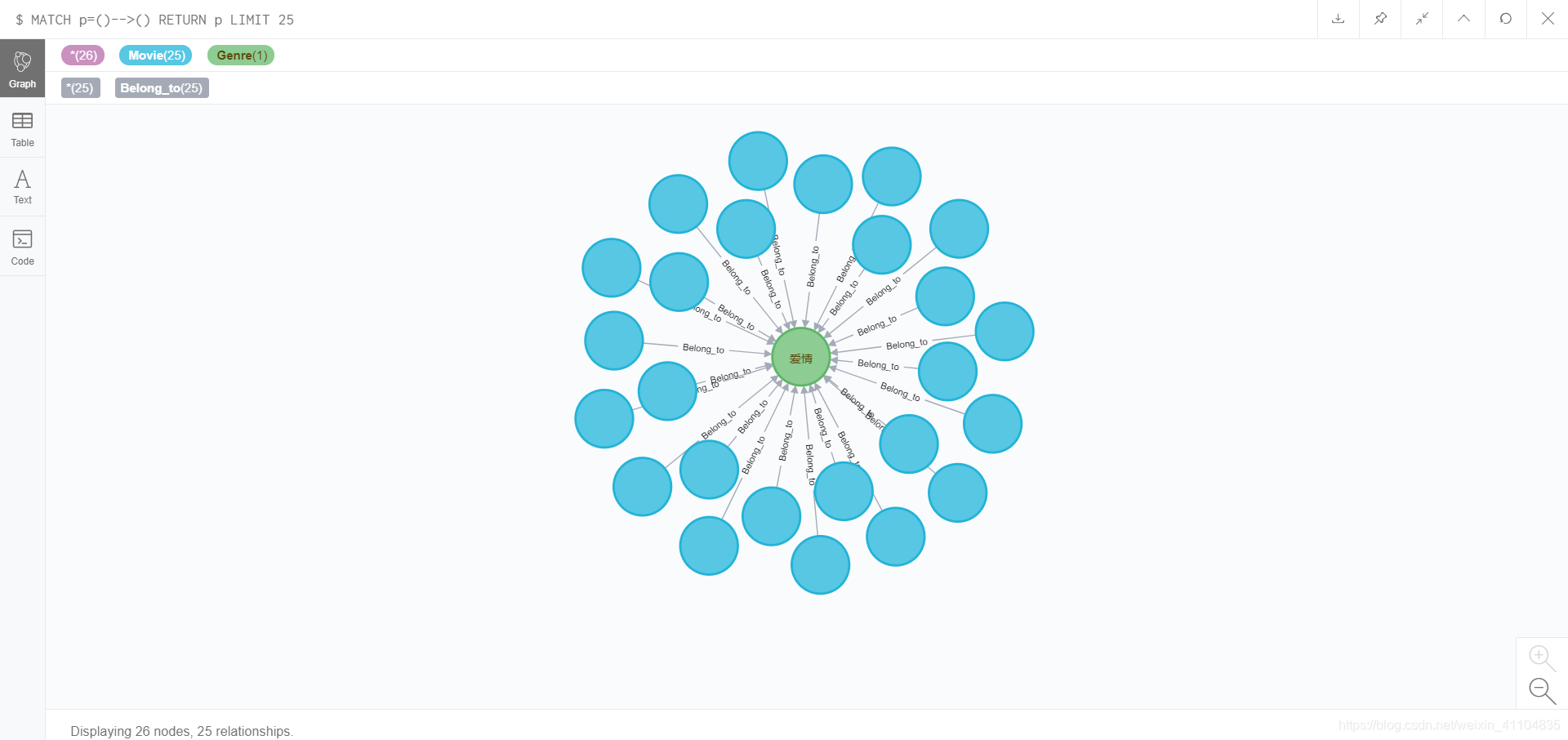
删除Belong_to关系
match (p)-[r:Belong_to]-()
detach delete r
- 显示最终图
MATCH p=() -[] -> () - [r:Belong_to]->() RETURN p LIMIT 50
结果:
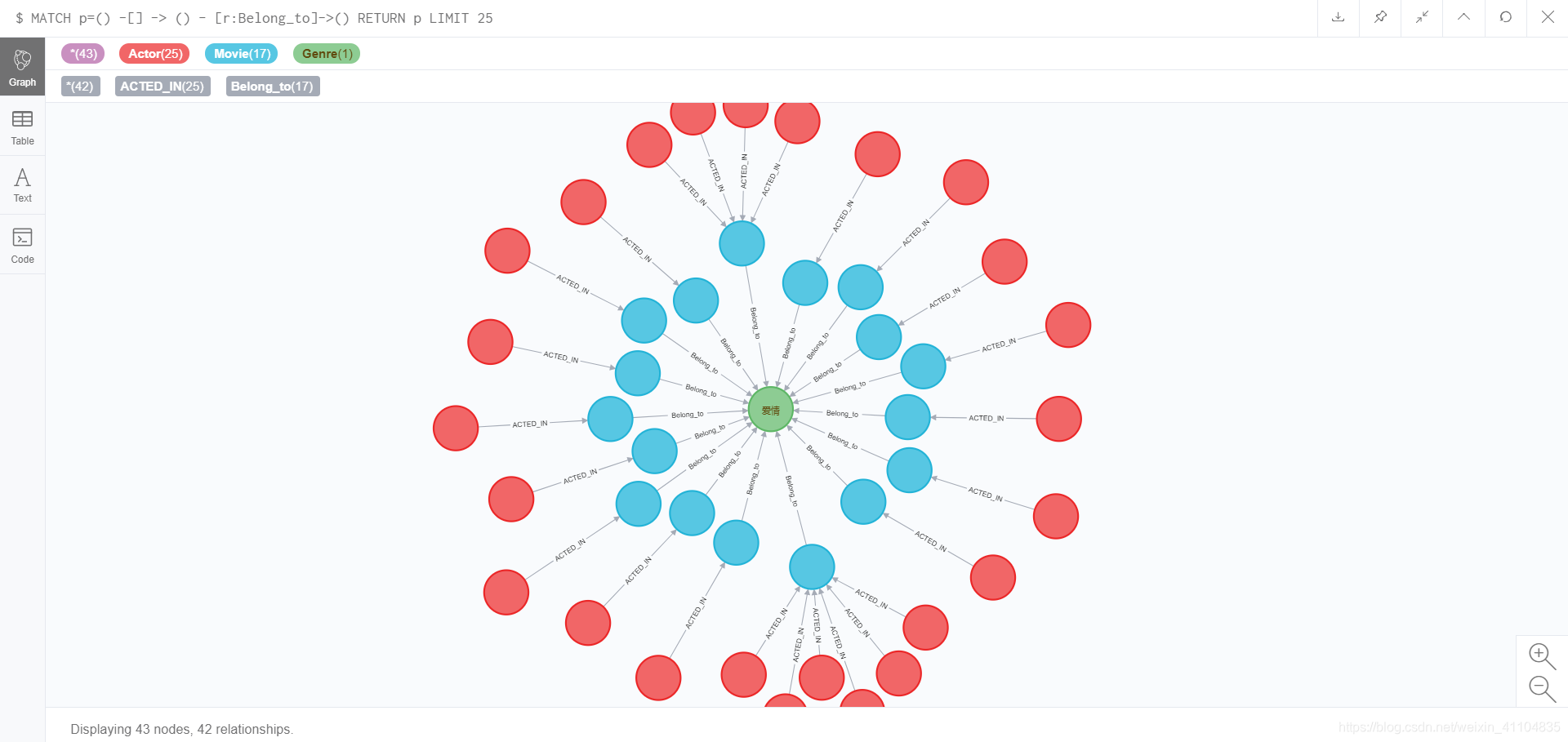
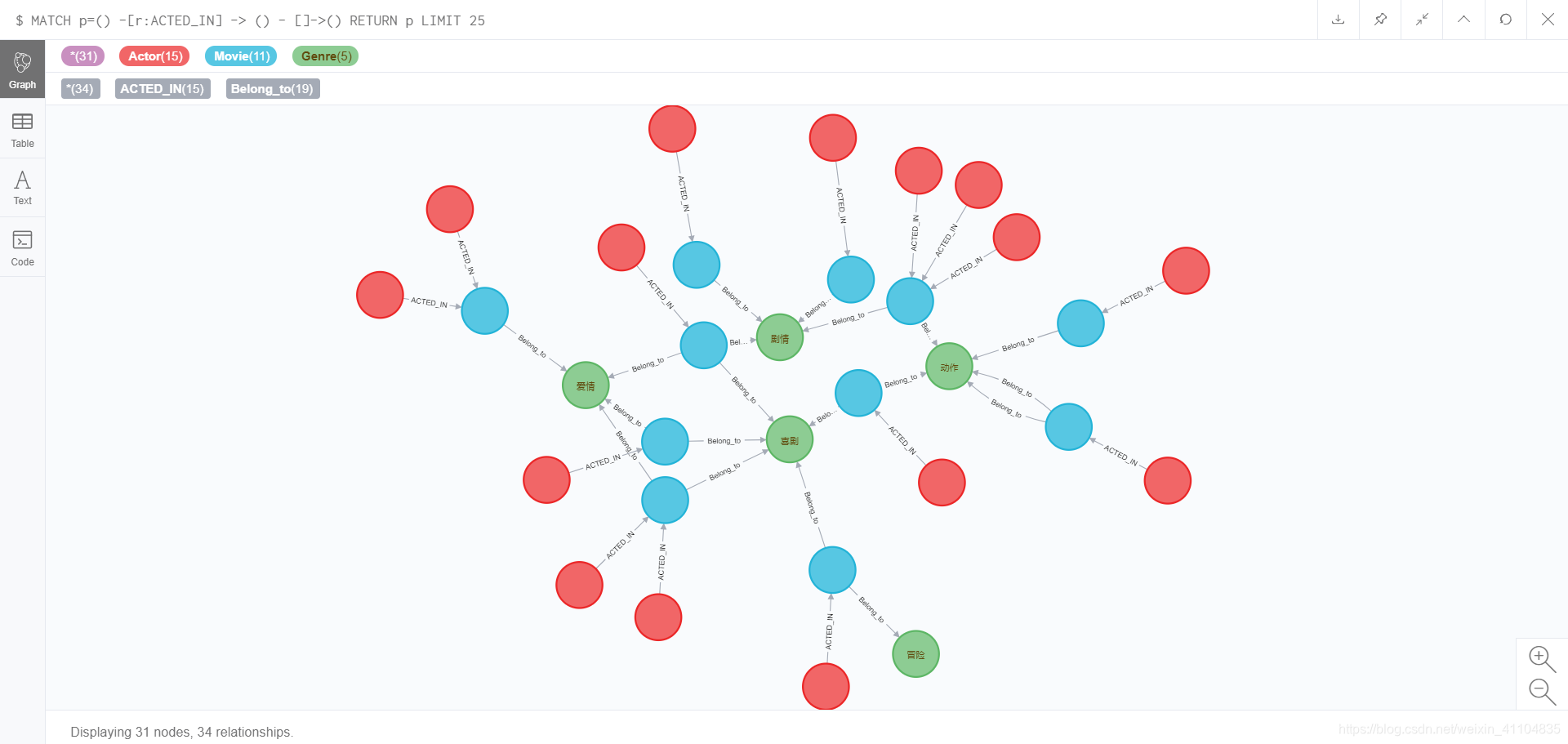
MATCH p=() -[r:ACTED_IN] -> () - []->() RETURN p LIMIT 25
结果:
参考:
[1] https://www.cnblogs.com/xs-yqz/p/7238242.html
[2] https://zhuanlan.zhihu.com/p/48708750
[3]https://blog.csdn.net/haveanybody/article/details/88251084