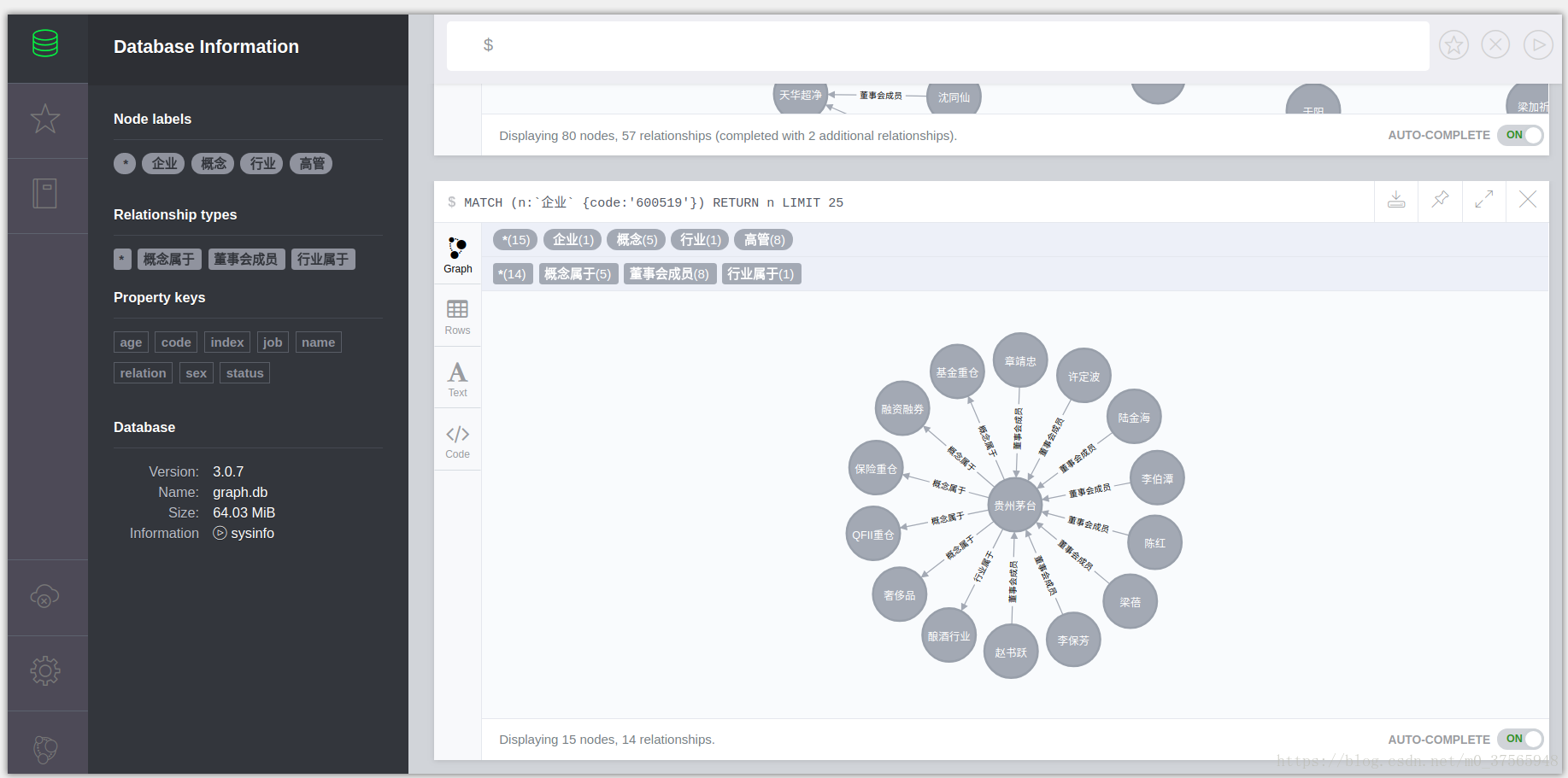
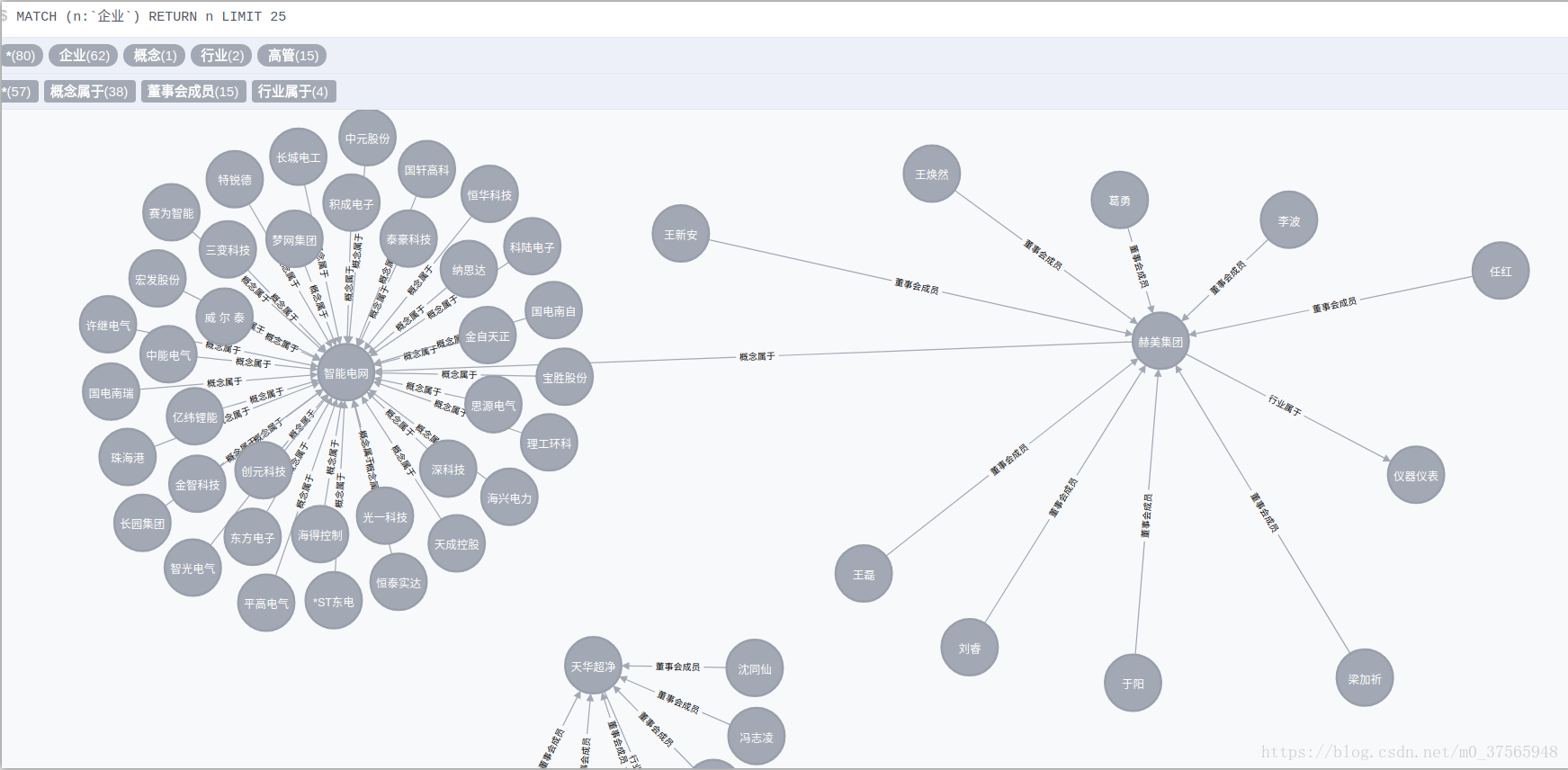
一、任务描述
本文章旨在用neo4j构建一个简单的金融领域的知识图谱,挖掘“高管—上市企业—行业/概念”之间的关系。关于具体的任务描述可下载我百度网盘的链接。链接:https://pan.baidu.com/s/1jLl9LnnHL4gaboUYXrYEDg 密码:2ge3
二、数据清洗,生成csv文件
项目介绍,通过百度网盘下载下来的文件夹—tanXinKg,里面包含target,这一部分数据是爬取同花顺官网得到的html文件,企业信息就存储在这写文件中,需要用BeautifulSoup去解析其内容,挖掘出相关的数据。
myJob1文件夹包含两部分,一部分是csv文件,一部分是kg文件夹,其中csv文件存储的是企业和高管,企业和行业,企业和概念的关系,kg文件夹是将外围的csv文件提取成能够导入到neo4j的csv文件。
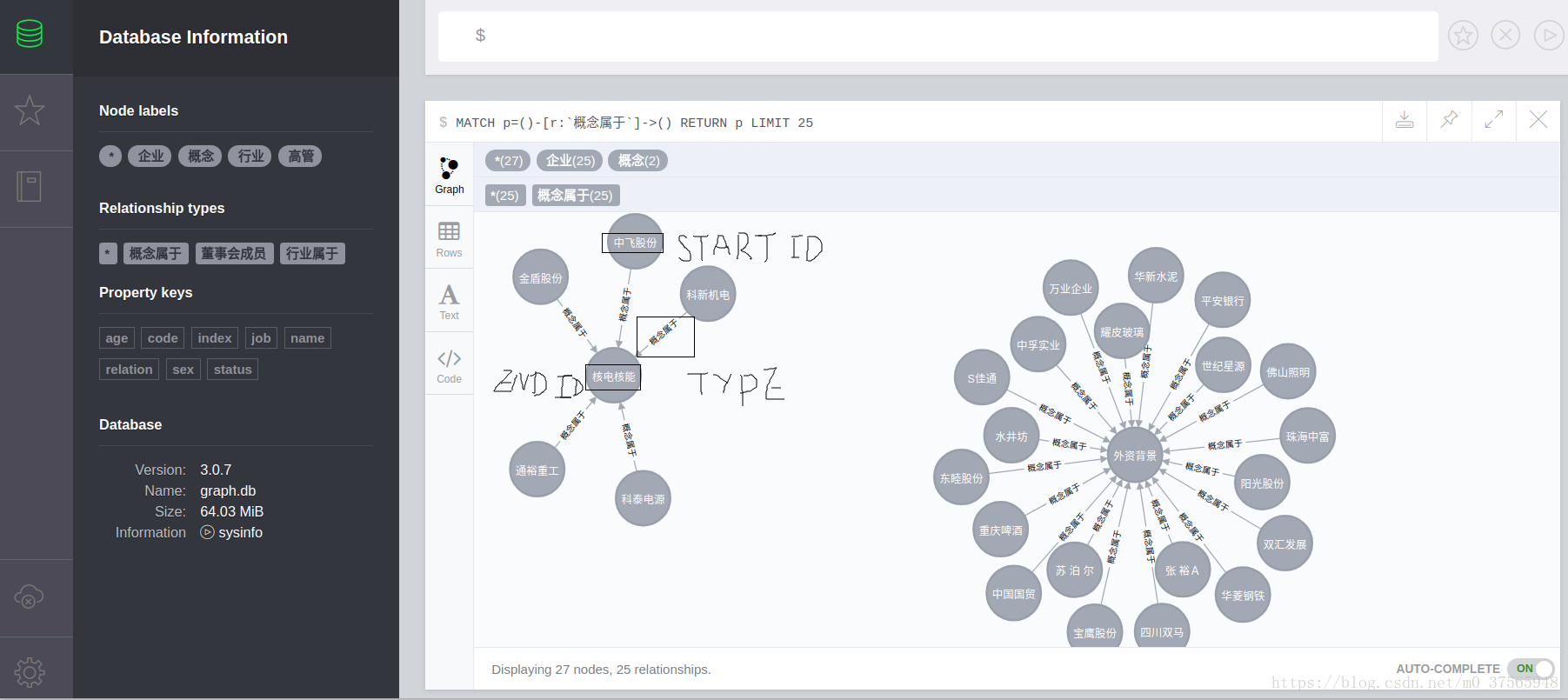
导入到neo4j的csv文件主要有nodes.csv文件(这部分文件在neo4j中是databases的作用)和relationship.csv文件(这部分文件在neo4j中是relation的作用)。
nodes文件,head字段如下所示
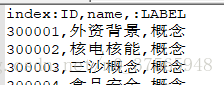
需要注意以下几点:
(1)csv文件都必须有唯一的id字段,而且文件间的id字段不能相同,常见的做法是用100000等较大的数加上其真实的id值。由于neo4j对大小比较敏感,所以head必须是index:ID。
(2)head的LABEL节点必须书写成:LABEL,注意添加冒号,而且不能小写。LABEL的内容不能多一个或少一个空格,这对neo4j的显示会有影响的。
(3)head的name节点,是可以定义的,可以称之为name,也可以称之为aaa,或bbb,但为了命名规范,建议写成name。
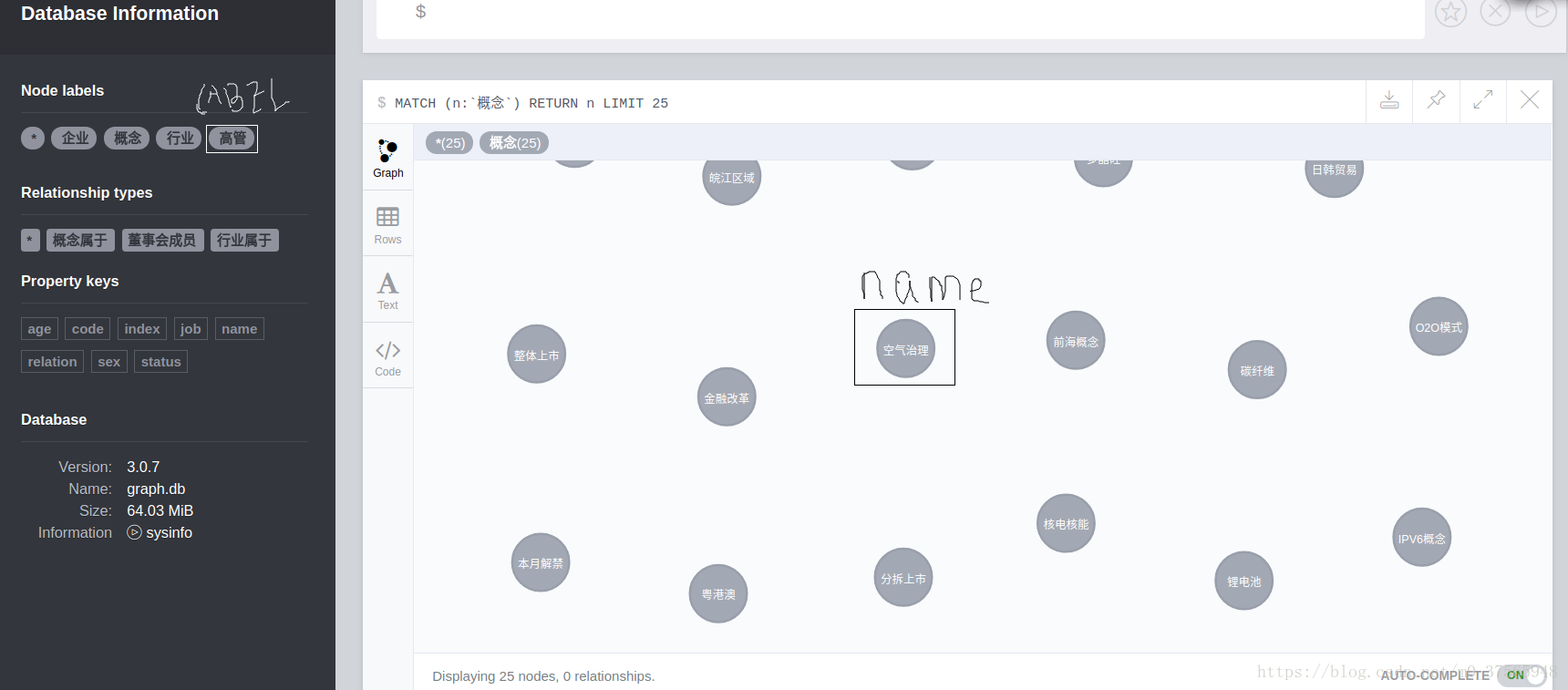
relationship.csv文件中,head字段如下:

需要注意以下几点:
(1)csv必须有:START_ID和:END_ID,而且这两个的id都要是nodes.csv文件中的ID。
(2)csv文件必须有relation字段。
(3)csv文件必须有:TYPE字段,不能省略冒号,不能小写。
三、neo4j-import 导入csv文件
这一部分可以参考他人博客,注意import 一定要有into文件路径,具体内容还需要根据自己的路径编写。
四、cypher的语句编写
这一部分可以参考几个大牛的博客