一、知识图谱

互联网、大数据的背景下,谷歌、百度、搜狗等搜索引擎纷纷基于该背景,创建自己的知识图谱Knowledge Graph(谷歌)、知心(百度)和知立方(搜狗),主要用于改进搜索质量。
1、什么是知识图谱
一种基于图的数据结构,由节点(Point)和边(Edge)组成。其中节点即实体,由一个全局唯一的ID标示,关系(也称属性))用于连接两个节点。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。
2、知识卡片
知识卡片旨在为用户提供更多与搜索内容相关的信息,例如,当在搜索引擎中输入“姚明”作为关键词时,我们发现搜索结果页面的右侧原先用于置放广告的地方被知识卡片所取代。下侧即使与关键词匹配的文档列表。
3、知识图谱的作用
知识图谱最早由谷歌提出,主要用于优化现有的搜索引擎,例如搜索姚明,除了姚明本身的信息,还可关联出姚明的女儿、姚明的妻子等与搜索关键字相关的信息。也就是说搜索引擎的知识图谱越庞大,与某关键字相关的信息越多,再通过分析搜索者的特指,计算出最可能想要看到的信息,通过知识图谱可大大提高搜索的质量和广度。
所以这也可理解为何谷歌百度等搜索引擎大头都为之倾心,创建自己符合自己用户搜索习惯的知识图谱。据不完全统计,Google知识图谱到目前为止包含了5亿个实体和35亿条事实(形如实体-属性-值,和实体-关系-实体)
4、知识图谱上的挖掘
通过大数据抽取和集成已经可以创建知识图谱,为进一步增加知识图谱的知识覆盖率,还需要进一步对知识图谱进行挖掘。常见的挖掘技术:
推理:通过规则引擎,针对实体属性或关系进行挖掘,用于发现未知的隐含关系
实体重要性排序:当查询多个关键字时,搜索引擎将选择与查询更相关的实体来展示。常见的pageRank算法计算知识图谱中实体的重要性。
二、Neo4j图数据库
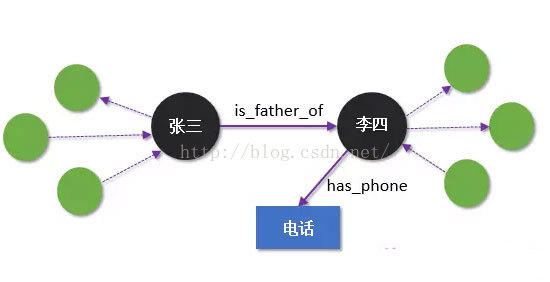
以上就是一个neo4j图数据库,由顶点-边组成,常用于微博好友关系分析、城市规划、社交、推荐等应用。
1、特性
支持ACID事务
企业版neo4j支持集群搭建,保证HA
轻易扩展上亿节点和关系
拥有自己的高级查询语言cypher高效检索
CSV数据导入,java语言编写均可
2、Cypher语言:
Match where return Create delete set foreach with 关键字同等与sql语句的select 等关键字操作,例如
Sql Statement
SELECT name FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "ITDepartment"MATCH(p:Person)<-[:EMPLOYEE]-(d:Department)WHEREd.name = "IT Department"RETURNp.nameJava Program Conn
Connectioncon = DriverManager.getConnection("jdbc:neo4j://localhost:7474/");
Stringquery ="MATCH (:Person {name:{1}})-[:EMPLOYEE]-(d:Department) RETURN d.name as dept";
try (PreparedStatementstmt = con.prepareStatement(QUERY)) {
stmt.setString(1,"John");
ResultSetrs = stmt.executeQuery();
while(rs.next()) {
Stringdepartment = rs.getString("dept");
....
}反欺诈:通过查找不同账户,如银行、信用卡等,找到该账户其他正常是否正常、相关用户的交易信息是否正常判断用户的信用度。
推荐:通过图数据库,查询某节点的消费情况、好友信息可为其推荐关联度高的好友或可能消费的商品。
因为neo4j的存储原理使得它的查询速度是在O(l)级别的复杂度,查询高效。