知识图谱——从零开始用neo4j框架对csv文件构建知识图谱(一)——安装neo4j
知识图谱——从零开始用neo4j框架对csv文件构建知识图谱(二)——构建三元组
1.构建实体文件和关系文件
在上文我们最后得出了entity-relation.csv,接下来我们对其拆分为实体和关系两个文件
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import pandas as pd
import csv
# 读取三元组文件
h_r_t_name = [":START_ID", "role", ":END_ID"]
h_r_t = pd.read_table("entity_relation.csv", decimal="\t", names=h_r_t_name,delimiter=",")
# print(h_r_t.info())
# print(h_r_t.head())
# 去除重复实体
entity = set()
entity_h = h_r_t[':START_ID'].tolist()
entity_t = h_r_t[':END_ID'].tolist()
for i in entity_h:
entity.add(i)
for i in entity_t:
entity.add(i)
print(entity)
# 保存节点文件
csvf_entity = open("entity.csv", "w", newline='', encoding='utf-8')
w_entity = csv.writer(csvf_entity)
# 实体ID,要求唯一,名称,LABEL标签,可自己不同设定对应的标签
w_entity.writerow(("entity:ID", "name", ":LABEL"))
entity = list(entity)
entity_dict = {
}
for i in range(len(entity)):
w_entity.writerow(("e" + str(i), entity[i], "my_entity"))
entity_dict[entity[i]] = "e" + str(i)
csvf_entity.close()
# 生成关系文件,起始实体ID,终点实体ID,要求与实体文件中ID对应,:TYPE即为关系
h_r_t[':START_ID'] = h_r_t[':START_ID'].map(entity_dict)
h_r_t[':END_ID'] = h_r_t[':END_ID'].map(entity_dict)
h_r_t[":TYPE"] = h_r_t['role']
h_r_t.pop('role')
h_r_t.to_csv("roles.csv", index=False)
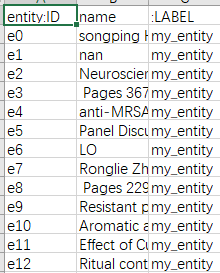
entity.csv文件如下图
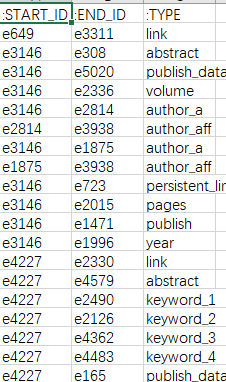
roles.csv文件如下图所示
2.调用neo4j构建知识图谱
在命令行输入neo4j-admin.bat import --nodes D:\python_workplaces\get_kg\entity.csv --relationships D:\python_workplaces\get_kg\roles.csv(对于换成自己的链接)
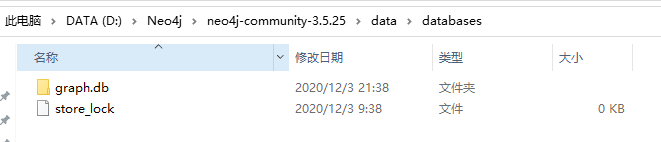
成功的话会在data文件夹下的databases文件夹下出现graph.db
这时候重新打开一个新的命令行,输入neo4j.bat console,打开http://localhost:7474/browser/,登陆,左侧点击,
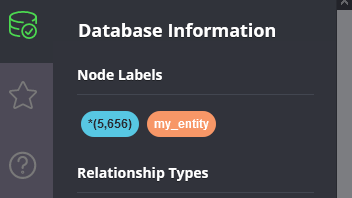
即会看到

说明成功了
3.失败的问题有
(1)实体错误,常见为实体不是一行输入的,是多行,出错信息中出现e222 error字样,修改为一行即可
(2)关系对应上,常见为没有该实体,,出错信息为e222 missing,把出错的实体补上就行,我才用的是把其设置为一个error实体
(3)出现NAN实体,把这个实体及其关系去掉即可,或者一开始就不把nan作为一个实体