目录
Fetching objects from the database
Backend connected to a database
Database configuration into its own module
Using database in route handlers
Verifying frontend and backend integration
Moving error handling into middleware
The order of middleware loading
Debugging Node applications
【调试Node应用】
调试 Node 应用比调试在浏览器中运行的 JavaScript 稍微困难一些。 将数据打印到控制台是一种可靠的方法,而且总是值得一试。 有些人认为应该用更复杂的方法来代替,但我不同意。 即使是世界上最顶尖的开源开发者也会使用 use 这种方法method。
Visual Studio Code
可以像这样在调试模式下启动应用:

代码执行在保存新便笺的过程中被暂停:

执行在第63行的断点 处停止。 在控制台中可以看到note 变量的值,左上角的窗口中可以看到与应用状态相关的其他内容。
顶部的箭头可用于控制调试器的流程。
Chrome dev tools
【Chrome开发工具】
利用 Chrome 开发者控制台,通过如下命令启动应用,也可以进行调试:
node --inspect index.js可以通过点击 Chrome 开发者控制台中的绿色图标——node的logo,来进入调试器:

调试视图的工作方式与 React 应用相同。Sources 选项卡可用于设置中断点,中断点将暂停代码的执行。

应用的所有 console.log 消息都将出现在调试器的Console 选项卡中。 还可以检查变量的值并执行自己的 JavaScript 代码。
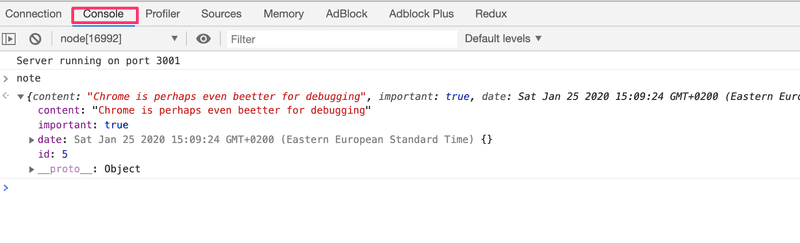
MongoDB
为了永久地存储便笺,我们将使用MongoDB ,这是一个所谓的文档数据库。
文档数据库在组织数据的方式以及它们所支持的查询语言方面不同于关系数据库。 文档数据库通常被归类为NoSQL的术语集。
参考 MongoDB 手册中关于集合和文档的章节,了解文档数据库如何存储数据和基本概念。
可以在自己的计算机上安装和运行 MongoDB,或者使用网上的 Mongo 数据库服务, 我们选用 MongoDB Atlas。
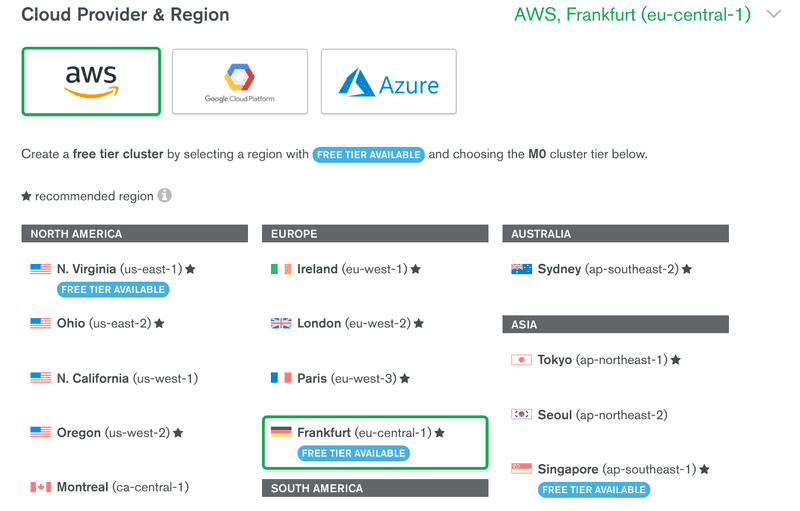
一创建并登录,Atlas 会建议你创建一个集群:

选择AWS作为提供商,并用Frankfurt作为地区,创建一个集群。
等待集群准备好,大约需要10分钟。注意在集群准备好之前不要继续。
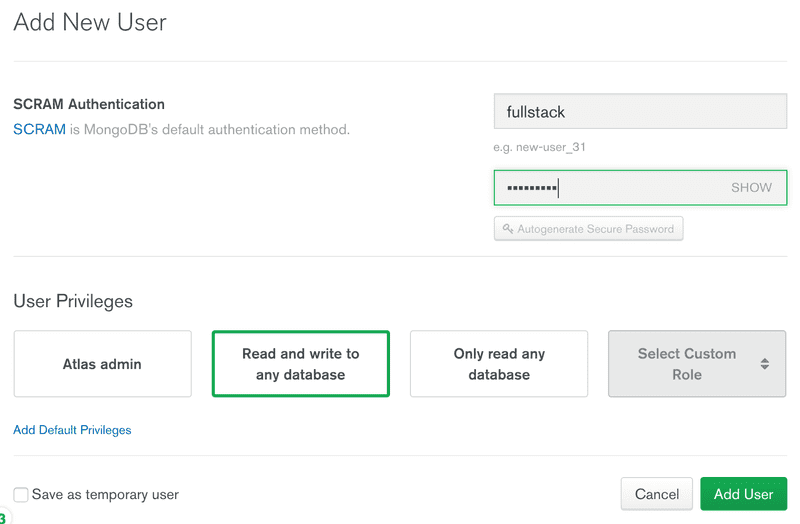
使用database access 选项卡为数据库创建用户凭据,用来让你的应用连接到数据库。
授予用户读写数据库的权限。
一般这些凭证需要几分钟的时间才生效。
接下来定义允许访问数据库的 IP 地址。
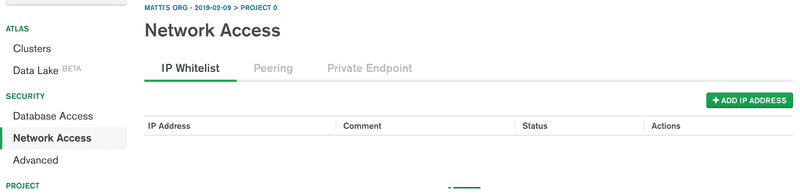
为了简单起见,允许所有访问的 IP 地址:

最后准备连接到我们的数据库:
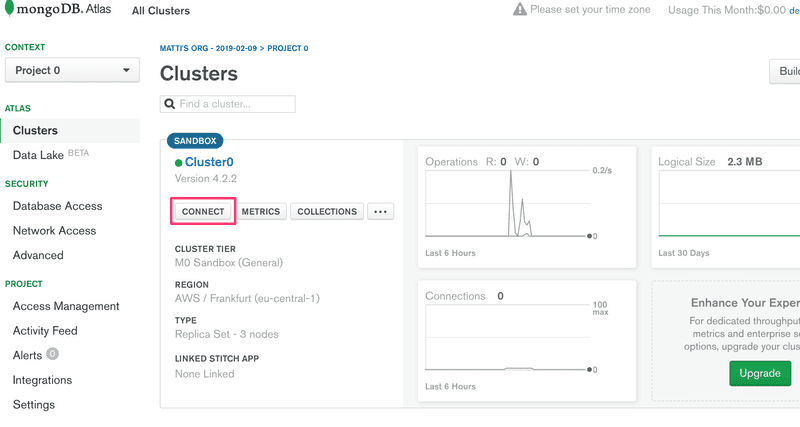
选择Connect your application:
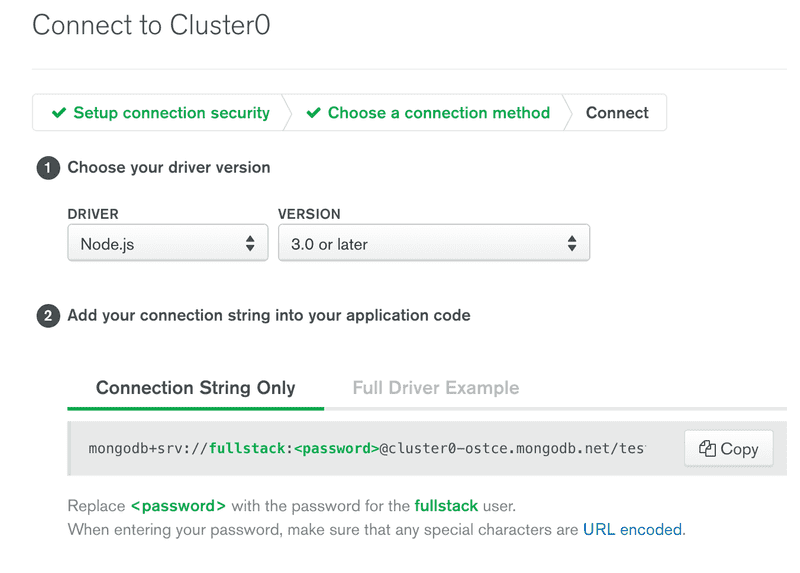
MongoDB URI 提供将添加到应用的 MongoDB 客户端库的数据库地址:
mongodb+srv://fullstack:<PASSWORD>@cluster0-ostce.mongodb.net/test?retryWrites=true现在可以使用数据库了。
可以通过官方的 MongoDb Node.js 驱动程序库直接从 JavaScript 代码中使用这个数据库,但使用起来相当麻烦, 这里我们将使用提供更高级别 API 的Mongoose库。
Mongoose 可以被描述为object document mapper (ODM) ,将 JavaScript 对象保存为 Mongo 文档。
安装 Mongoose:
npm install mongoose我们创建mongo.js 文件,来创建一个实践应用:
const mongoose = require('mongoose')
if ( process.argv.length<3 ) {
console.log('Please provide the password as an argument: node mongo.js <password>')
process.exit(1)
}
const password = process.argv[2]
const url =
`mongodb+srv://fullstack:${password}@cluster0-ostce.mongodb.net/test?retryWrites=true`
mongoose.connect(url, { useNewUrlParser: true, useUnifiedTopology: true, useFindAndModify: false, useCreateIndex: true })
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)
const note = new Note({
content: 'HTML is Easy',
date: new Date(),
important: true,
})
note.save().then(result => {
console.log('note saved!')
mongoose.connection.close()
})注意:取决于选择什么区域构建集群, MongoDB URI 可能和上例中提供的有些不同。证并使用 MongoDB Atlas 生成的正确的URI
该代码假定命令行参数从我们在 MongoDB Atlas 中创建的凭据中传递密码, 访问命令行参数:
const password = process.argv[2]当使用命令node mongo.js password运行代码时,Mongo 将向数据库添加一个新文档。
注意这里的password 是为数据库用户创建的password,也就是说,如果你的密码是特殊字符,需要URL encode that password
可以从Collections 中查看 MongoDB Atlas 中数据库的当前状态
在概览标签页。
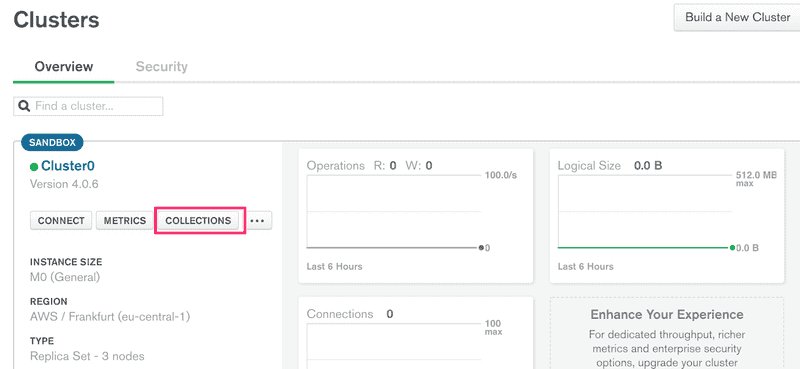
匹配便笺的document 已经添加到test 数据库中的notes 集合中。
可以从 URI 改变数据库的名称:
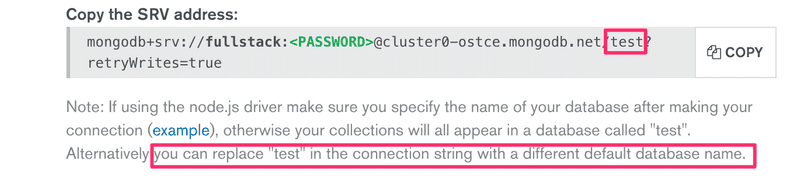
通过修改 URI,将数据库的名称更改为note-app:
mongodb+srv://fullstack:<PASSWORD>@cluster0-ostce.mongodb.net/note-app?retryWrites=true再次运行代码。
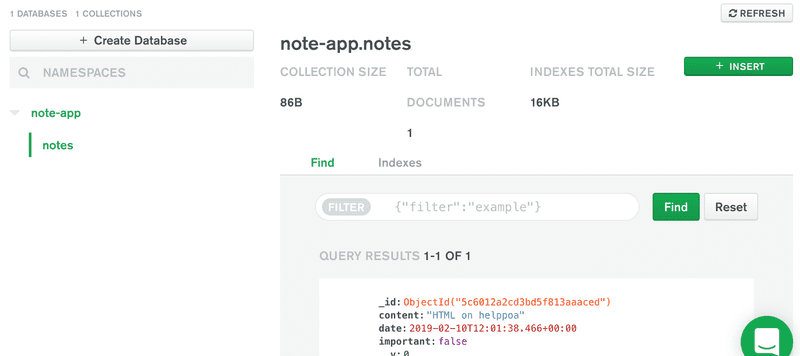
数据现在存储在正确的数据库中。当应用试图连接到一个尚不存在的数据库时,MongoDB Atlas 会自动创建一个新的数据库。
Schema
建立到数据库的连接之后,为一个便笺定义模式schema和匹配的模型 :
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)首先定义了存储在 noteSchema 变量中的便笺的模式。 模式告诉 Mongoose 如何将 note 对象存储在数据库中。
在 Note 模型定义中,第一个 "Note"参数是模型的单数名。 集合的名称将是小写的复数 notes,因为Mongoose 约定是当模式以单数(例如Note)引用集合时自动将其命名为复数(例如notes)。
像 Mongo 这样的文档数据库是schemaaless,这意味着数据库本身并不关心存储在数据库中的数据的结构。 可以在同一集合中存储具有完全不同字段的文档。
Mongoose 背后的思想是,存储在数据库中的数据在application 级别上被赋予一个schema ,该模式定义了存储在任何给定集合中的文档的形状。
Creating and saving objects
【创建和保存对象】接下来在Note model的帮助下创建一个新的 Note 对象:
const note = new Note({
content: 'HTML is Easy',
date: new Date(),
important: false,
})模型是所谓的构造函数constructor function,它根据提供的参数创建新的 JavaScript 对象。 由于对象是使用模型的构造函数创建的,因此它们具有模型的所有属性,其中包括将对象保存到数据库的方法。
将对象保存到数据库是通过恰当命名的 save 方法实现的,可以通过 then 方法提供一个事件处理程序:
note.save().then(result => {
console.log('note saved!')
mongoose.connection.close()
})当对象保存到数据库时,将调用提供给该对象的事件处理。 事件处理程序使用命令代码 mongoose.connection.close()关闭数据库连接。 如果连接没有关闭,程序将永远不能完成它的执行。
Fetching objects from the database
【从数据库中获取对象】
注释掉生成新便笺的代码,并用如下代码替换:
Note.find({}).then(result => {
result.forEach(note => {
console.log(note)
})
mongoose.connection.close()
})当代码执行时,程序会输出存储在数据库中的所有便笺:

这些对象是通过 Note 模型的find方法从数据库中检索的。 该方法的参数是表示搜索条件的对象。 因为参数是一个空的对象{},所以我们得到了存储在 notes 集合中的所有便笺。
搜索条件遵循 Mongo 搜索查询语法。
我们可以限制我们的搜索,只包括重要的便笺,如下所示:
Note.find({ important: true }).then(result => {
// ...
})Backend connected to a database
【后端连接到数据库】
现在可以在应用中使用 Mongo了。
复制粘贴 Mongoose 定义到index.js 文件:
const mongoose = require('mongoose')
// DO NOT SAVE YOUR PASSWORD TO GITHUB!!
const url =
'mongodb+srv://fullstack:[email protected]/note-app?retryWrites=true'
mongoose.connect(url, { useNewUrlParser: true, useUnifiedTopology: true, useFindAndModify: false, useCreateIndex: true })
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)让我们将获取所有便笺的处理程序更改为如下形式:
app.get('/api/notes', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})可以在浏览器中验证后端是否可以显示所有文档:
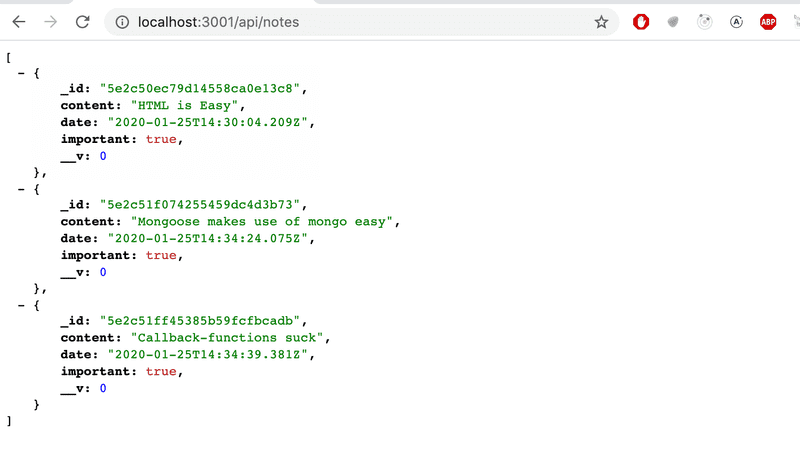
完美。 前端假设每个对象在id 字段中都有唯一的 id。 我们也希望将 mongo 版本控制字段 __v 返回到前端。
格式化 Mongoose 返回的对象可以通过修改Schema 的 toJSON 方法,这个schema是作用在所有models实例上的:
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})尽管 Mongoose 对象的 id 属性看起来像一个字符串,但实际上它是一个对象, toJSON 方法将其转换为字符串。
让我们用一个用 toJSON 方法格式化的对象列表来响应 HTTP 请求:
app.get('/api/notes', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})现在,notes 变量被分配给 Mongo 返回的对象数组。 当response 以JSON 格式返回,数组中每个对象 toJSON 方法会通过JSON.stringify自动调用
Database configuration into its own module
【数据库逻辑配置到单独的模块】
将 Mongoose 特定的代码提取到它自己的模块中。
为模块models 创建一个新目录,并添加一个名为note.js 的文件:
const mongoose = require('mongoose')
const url = process.env.MONGODB_URI
console.log('connecting to', url)
mongoose.connect(url, { useNewUrlParser: true, useUnifiedTopology: true, useFindAndModify: false, useCreateIndex: true })
.then(result => { console.log('connected to MongoDB') }) .catch((error) => { console.log('error connecting to MongoDB:', error.message) })
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})
module.exports = mongoose.model('Note', noteSchema)模块的公共接口是通过将值设置为 module.exports 变量来定义的。 我们将该值设置为Note 模型。 模块内部定义的其他东西,比如变量 mongoose 和 url 对于模块的用户来说是不可访问的或者不可见的。
导入模块的方法是在index.js 中添加如下代码:
const Note = require('./models/note')这样,Note 变量将被分配给模块定义的同一个对象。
建立链接的方式略有改变:
const url = process.env.MONGODB_URI
console.log('connecting to', url)
mongoose.connect(url, { useNewUrlParser: true, useUnifiedTopology: true, useFindAndModify: false, useCreateIndex: true })
.then(result => {
console.log('connected to MongoDB')
})
.catch((error) => {
console.log('error connecting to MongoDB:', error.message)
})将数据库的地址硬编码到代码中并不是一个好主意,数据库的地址一般通过MONGODB_URI 环境变量传递给应用。
建立连接的方法现在被赋予处理成功和失败的连接尝试的函数。 这两个函数都只是向控制台发送一条关于成功状态的消息:

使用dotenv定义环境变量的值。安装库:
npm install dotenv为了使用这个库,创建一个 .env 文件在项目的根部。 环境变量是在文件内部定义的:
MONGODB_URI='mongodb+srv://fullstack:[email protected]/note-app?retryWrites=true'
PORT=3001将服务器的硬编码端口添加到 PORT 环境变量中。
.env 文件应立即放到gitignore中,因为不希望在网上公开任何机密!

可以使用require('dotenv').config()命令来使用 .env 文件中定义的环境变量。
更改index.js 文件:
require('dotenv').config()const express = require('express')
const app = express()
const Note = require('./models/note')
// ..
const PORT = process.env.PORTapp.listen(PORT, () => {
console.log(`Server running on port ${PORT}`)
})需要在导入note 模型之前导入dotenv。 这样可以确保在导入其他模块的代码之前, .env 文件是全局可用的。
Using database in route handlers
【在路由处理程序中使用数据库】
接下来,让我们更改后端功能的其余部分来使用数据库。
创建一个新的便笺是这样完成的:
app.post('/api/notes', (request, response) => {
const body = request.body
if (body.content === undefined) {
return response.status(400).json({ error: 'content missing' })
}
const note = new Note({
content: body.content,
important: body.important || false,
date: new Date(),
})
note.save().then(savedNote => {
response.json(savedNote)
})
})使用 Note 构造函数创建 Note 对象。 请求的响应是在保存操作的回调函数中发送的。 这确保只有在操作成功时才发送响应。 稍后将讨论错误处理。
回调函数中的 savedNote 参数是保存的和新创建的便笺。 返回的数据是用 toJSON 方法创建的格式化版本:
response.json(savedNote)使用Mongoose的findById 方法,取一个单独的便笺代码改为:
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id).then(note => {
response.json(note)
})
})Verifying frontend and backend integration
【验证前端和后端的集成】
当后端扩展时,最好先用 浏览器,Postman 或者 VS Code REST 客户端 来测试后端。
尝试在使用数据库之后创建一个新的便笺:
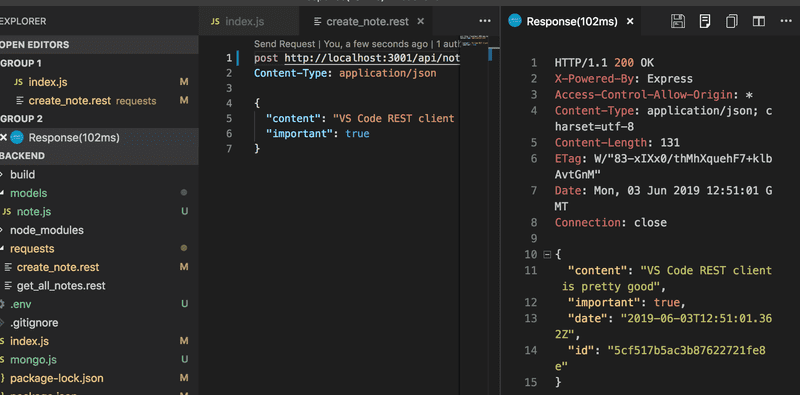
当后端工作正常时,再测试前端与后端的协同性。
Error handling
【错误处理】
现在如果我们试图向数据库访问一个实际上并不存在的 id 的便笺的 URL,比如 http://localhost:3001/api/notes/5c41c90e84d891c15dfa3431 ,那么返回值将会是 null。
改变行为,当给定id的note不存在时,服务端会向请求响应404状态。
实现一个简单的catch代码块,来处理findById方法返回rejected的情况:
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => {
console.log(error)
response.status(500).end()
})
})如果在数据库中没有找到匹配的对象,note 的值会是 null, 于是 else 代码块执行。因此返回的状态是404 not found。而如果 findById 方法的promise 状态会是 500 internal server error。 可以在控制台中看到更多的错误打印信息。
On top of the non-existing note, there's one more error situation needed to be handled. In this situation, we are trying to fetch a note with a wrong kind of id, meaning an id that doesn't match the mongo identifier format. 出了note 不存在的错误,还有许多错误是需要处理的。现在,我们尝试获取一个错误的 id, 也就是一个与mongo 标识符格式不匹配的 id 。
如果提出如下请求,将得到错误消息:
Method: GET
Path: /api/notes/someInvalidId
Body: {}
---
{ CastError: Cast to ObjectId failed for value "someInvalidId" at path "_id"
at CastError (/Users/mluukkai/opetus/_fullstack/osa3-muisiinpanot/node_modules/mongoose/lib/error/cast.js:27:11)
at ObjectId.cast (/Users/mluukkai/opetus/_fullstack/osa3-muisiinpanot/node_modules/mongoose/lib/schema/objectid.js:158:13)
...
当给出了一个奇怪的id作为参数时,findById 方法会抛出一个错误,进而会导致promise返回了rejected,因此也就会触发catch代码块中的函数。
应该区分这两种不同类型的错误情况。 后者实际上是由我们自己的输入引起的错误。
修改代码:
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => {
console.log(error)
response.status(400).send({ error: 'malformatted id' })
})
})如果 id 的格式不正确,那么将在 catch 块中定义的错误处理程序中结束。 适合这种情况的状态代码是 400 Bad Request:
The request could not be understood by the server due to malformed syntax. The client SHOULD NOT repeat the request without modifications.
由于格式不正确的语法,服务器无法理解请求。 客户端不应该在没有修改的情况下重复请求。
在响应中添加一些数据阐明错误的原因。
在处理 Promises 时,建议多添加错误和异常处理,减少出现奇怪的 bug。
Moving error handling into middleware
【将错误处理移入中间件】
最好在单个位置实现所有错误处理。 如果想要将与错误相关的数据报告给外部的错误跟踪系统,比如Sentry,那么这么做就特别有用。
更改 /api/notes/:id 路由的处理程序,以便它使用next 函数向下传递错误。 下一个函数作为第三个参数传递给处理程序:
app.get('/api/notes/:id', (request, response, next) => {
Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => next(error))
})将向前传递的错误作为参数给 next 函数。 如果在没有参数的情况下调用 next,那么执行将简单地转移到下一个路由或中间件上。 如果使用参数调用next 函数,那么执行将继续到error 处理程序中间件。
Express error handlers是一种中间件,定义了一个接受4个参数 的函数。错误处理程序如下:
const errorHandler = (error, request, response, next) => {
console.error(error.message)
if (error.name === 'CastError' && error.kind === 'ObjectId') {
return response.status(400).send({ error: 'malformatted id' })
}
next(error)
}
app.use(errorHandler)错误处理程序检查错误是否是CastError 异常,在这种情况下,错误是由 Mongo 的无效对象 id 引起的。 此时错误处理程序将向浏览器发送响应,并将response对象作为参数传递。 在所有其他错误情况下,中间件将错误转发给缺省的 Express 错误处理程序。
The order of middleware loading
【中间件加载顺序】
中间件的执行顺序与通过 app.use 函数加载到 express 中的顺序相同。
正确的顺序如下:
app.use(express.static('build'))
app.use(express.json())
app.use(logger)
app.post('/api/notes', (request, response) => {
const body = request.body
// ...
})
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
// handler of requests with unknown endpoint
app.use(unknownEndpoint)
const errorHandler = (error, request, response, next) => {
// ...
}
// handler of requests with result to errors
app.use(errorHandler)Json-parser 中间件应该是最早加载到 Express 中的中间件之一,如果顺序变成了下面这样:
app.use(logger) // request.body is undefined!
app.post('/api/notes', (request, response) => {
// request.body is undefined!
const body = request.body
// ...
})
app.use(express.json())那么,由 HTTP 请求发送的 JSON 数据将不能用于日志记录器中间件或 POST 路由处理程序,因为此时 request.body 将是一个undefined。
用于处理不支持路由的中间件位于加载到 Express 的最后一个中间件的旁边,即错误处理程序之前。
例如,下面的加载顺序会导致一个问题:
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
// handler of requests with unknown endpoint
app.use(unknownEndpoint)
app.get('/api/notes', (request, response) => {
// ...
})现在,对未知端点的处理先于 HTTP 请求处理程序。 由于未知端点处理程序使用404未知端点 响应所有请求,在未知端点中间件发送响应之后,将不会调用任何路由或中间件。 唯一的例外是错误处理程序,它需要出现在未知的端点处理程序之后的最后一个端点。
Other operations
【其他操作】
为应用添加一些缺失的功能,包括删除和更新单个便笺。
从数据库中删除便笺最简单的方法是使用findByIdAndRemove方法:
app.delete('/api/notes/:id', (request, response, next) => {
Note.findByIdAndRemove(request.params.id)
.then(result => {
response.status(204).end()
})
.catch(error => next(error))
})在删除资源的两个“成功”案例中,后端都使用状态码 204 no content.进行响应。 两种不同的情况是删除已存在的便笺,以及删除数据库中不存在的便笺。 结果回调参数可用于检查资源是否实际被删除,如果认为有必要,我们可以使用该信息为两种情况返回不同的状态代码。 发生的任何异常都会传递到错误处理程序上。
通过findbyidanddupdate方法更改便笺的重要性。
app.put('/api/notes/:id', (request, response, next) => {
const body = request.body
const note = {
content: body.content,
important: body.important,
}
Note.findByIdAndUpdate(request.params.id, note, { new: true })
.then(updatedNote => {
response.json(updatedNote)
})
.catch(error => next(error))
})上面的代码中也允许编辑便笺的内容。
findByIdAndUpdate 方法接收一个常规的 JavaScript 对象作为参数,而不是用 Note 构造函数创建的新便笺对象。
关于 findByIdAndUpdate方法的使用有一个重要的细节。 默认情况下,事件处理程序的 updatedNote 参数接收原始文档无需修改。 我们添加了可选的代码{ new: true }参数,这将导致使用新修改的文档而不是原始文档调用事件处理程序。
在使用 Postman 和 VS Code REST 客户端直接测试后端之后,我们可以验证它似乎可以工作。 前端似乎也与使用数据库的后端一起工作。