这该找工作了,俗话说的胡奥,金九银十嘛。一个一个招聘信息找着看,有点麻烦。所以心动了下,不如把我想找的信息都爬取下来,直接sql语句查询所有相关信息,多方便,是吧~
该内容主要是从我上篇博文:https://blog.csdn.net/qq_38044574/article/details/82111035
修改而来,这里主要提供详细更改的地方
希望对看官有所帮助。
如果有错误,欢迎指出。
注:
如果start-urls只设置一个的话,那么只会爬取等于或者小于40条数据(会有重复)
Spider块:
信息搜索,原本是想搜python、爬虫之类的,后来写着写着就变成java了。果真还是忘不了自己的母语言啊~
import scrapy
from liepinSpider.items import LiepinspiderItem
class LisPinSpider(scrapy.Spider):
name = 'liepin'
allowed_domains = ['www.liepin.com']
start_urls = [
'https://www.liepin.com/sh/zhaopin/?dqs=020&salary=&isAnalysis=true&init=1&searchType=1&fromSearchBtn=1&jobTitles=&industries=&industryType=&d_headId=89d222c119810d9835c864b9842ca41a&d_ckId=89d222c119810d9835c864b9842ca41a&d_sfrom=search_city&d_curPage=0&d_pageSize=40&siTag=&key=java'
]
#这个地址是该网站翻页第二页的地址,只需要在/zhaopin/后面加上pn1(第2页,以此类
#推)
#还有,在这里要吐槽下猎聘的这个翻页,搜索关键字和区域后,进行翻页,关键字和区域都
#没了,我还要手动修改拼接url地址。最主要的是,用户体验没了啊。不懂技术的人,压根
#不知道怎么看第二页内容了。。
#如果想做的更灵活,直接input,修改key关键字地址就行,中文需要更改下编码,
#就这样
# https://www.liepin.com/sh/zhaopin/pn1/?dqs=&salary=&isAnalysis=true&init=1&searchType=1&fromSearchBtn=1&jobTitles=&industries=&industryType=&d_headId=89d222c119810d9835c864b9842ca41a&d_ckId=89d222c119810d9835c864b9842ca41a&d_sfrom=search_city&d_curPage=0&d_pageSize=40&siTag=&key=java
def parse(self, response):
list = response.css('.sojob-list li')
for li in list:
html_url = li.css('.job-name a::attr(href)').extract_first()
yield scrapy.Request(html_url, callback=self.content)
#这个位置可以编写下一页的访问请求
#yield scrapy.Request('拼接好的url',callback=self.parse)
def content(self, response):
item = LiepinspiderItem()
#这个是直接获取该页面的url地址
html_url = response.url
title = response.css('.title-info h1::text').extract_first()
company = response.css('.title-info h3 a::text').extract_first()
money = response.css('.job-item-title::text').extract_first()
address = response.css('.basic-infor a::text').extract_first()
times = response.css('.basic-infor time::attr(title)').extract_first()
job_query_list = response.css('.job-qualifications span::text').extract()
job_query = ''
for job_querys in job_query_list:
job_query += job_querys + ','
tag_list = response.css('.tag-list span::text').extract()
tags = ''
for tag_span in tag_list:
tags += tag_span + ','
job_contents = response.css('.job-description div::text').extract()
job_content=''
for job in job_contents:
job_content += job.replace('\r\n','')
#不要忘了在item中设置相关的参数呦
#招聘网页url
item['html_url'] = html_url
#标题
item['title'] = title
#公司名称
item['company'] = company
#薪水
item['money'] = money.strip()
#公司地址(这个是区域地址,详细地址可以在页面上找到,自己修改下就好了)
item['address'] = address
#发布时间
item['times'] = times
#简写的工作条件
item['job_query'] = job_query
#福利待遇
item['tags'] = tags
#详细的工作职责和工作条件
item['job_content'] = job_content.strip()
yield itempipelines块:
不要忘记在setting中开启pipelines模块啊~~
ITEM_PIPELINES = {
‘liepinSpider.pipelines.LiepinspiderPipeline’: 1,
}
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from scrapy.exceptions import DropItem
def dbHandle():
conn = pymysql.connect(
host='localhost',
user='root',
passwd='Cs123456.',
charset='utf8',
db='liepin',
use_unicode=False
)
return conn
class LiepinspiderPipeline(object):
def process_item(self, item, spider):
#连接数据库
db = dbHandle()
#开启游标
cursor = db.cursor()
#拼接sql
sql = 'insert into liepin_list (url, title, company, money, address, times, job_query, tags, job_content) ' \
'value ("{html_url}", "{title}", "{company}", "{money}", "{address}", "{times}", "{job_query}", "{tags}", "{job_content}");'.format(
**item)
try:
#判断
re = self.db_distinct(item['html_url'])
if re:
try:
cursor.execute(sql)
db.commit()
except:
raise DropItem('sql执行错误')
else:
raise DropItem('数据已存在')
except:
db.rollback()
cursor.close()
#通过招聘地址的url来判断这个页面是否被存储过
def db_distinct(self, html_url):
db = dbHandle()
cursor = db.cursor()
sql = 'select * from liepin_list where url ="{}"'.format(html_url)
cursor.execute(sql)
data = cursor.fetchone()
cursor.close()
if data == None:
return True
else:
return False
表结构:
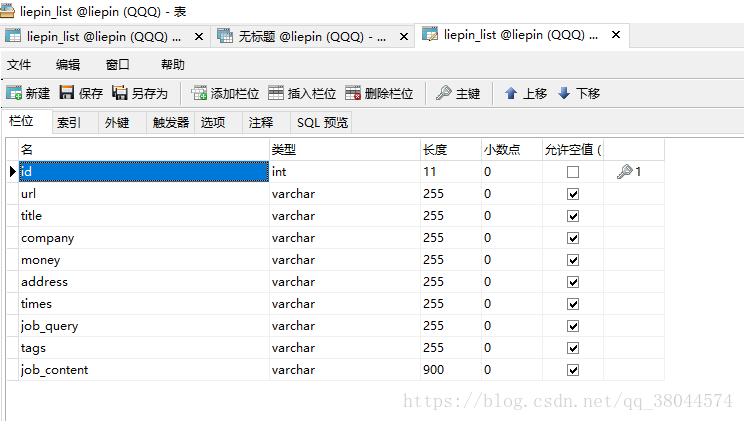
查询的部分数据:
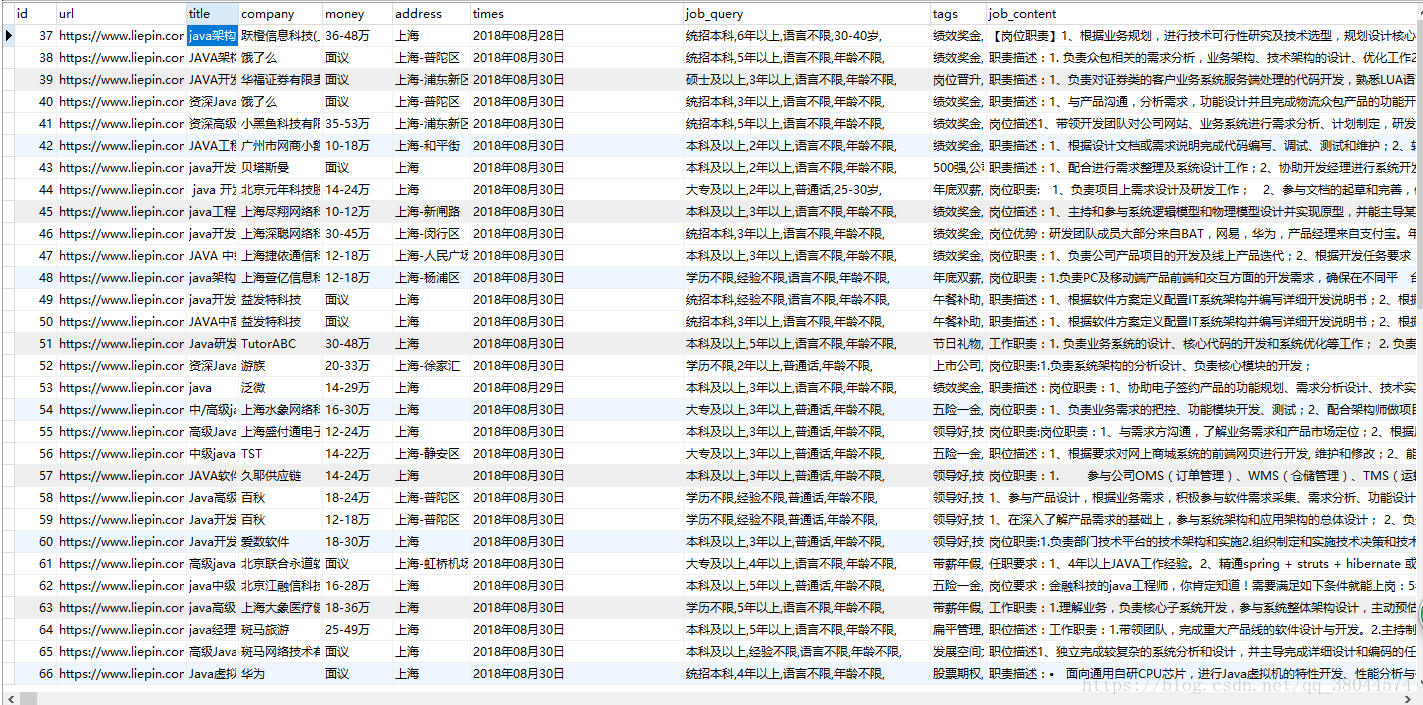
这样就大功告成了,谢谢观看。