此次爬取的信息有:
1、视频名称
2、在线观看人数
3、弹幕内容
4、弹幕发送时间
5、弹幕在视频中的位置
6、点赞
7、收藏
8、投币数

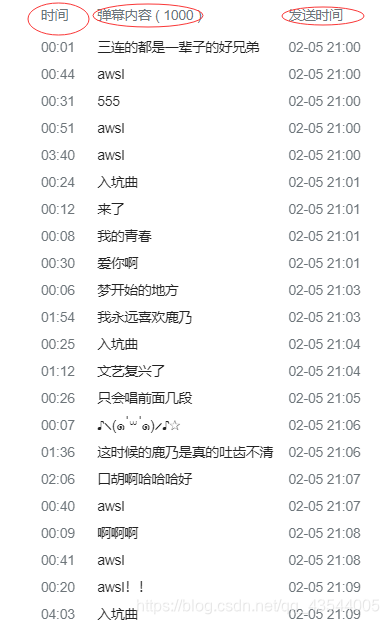
由于b站的很多信息是动态加载的。所以部分信息,需要自己抓包,进入对应的网址抽取信息。例如在线观看视频人数,投币数,收藏数等等。
我的思路
首先拿到这个小项目时,分析出 要获取的数据如上。观察,不同信息对应的url。首先,我们应先在B站首页,获取出 要爬取视频的 名字,url地址。但此时存在一个问题:
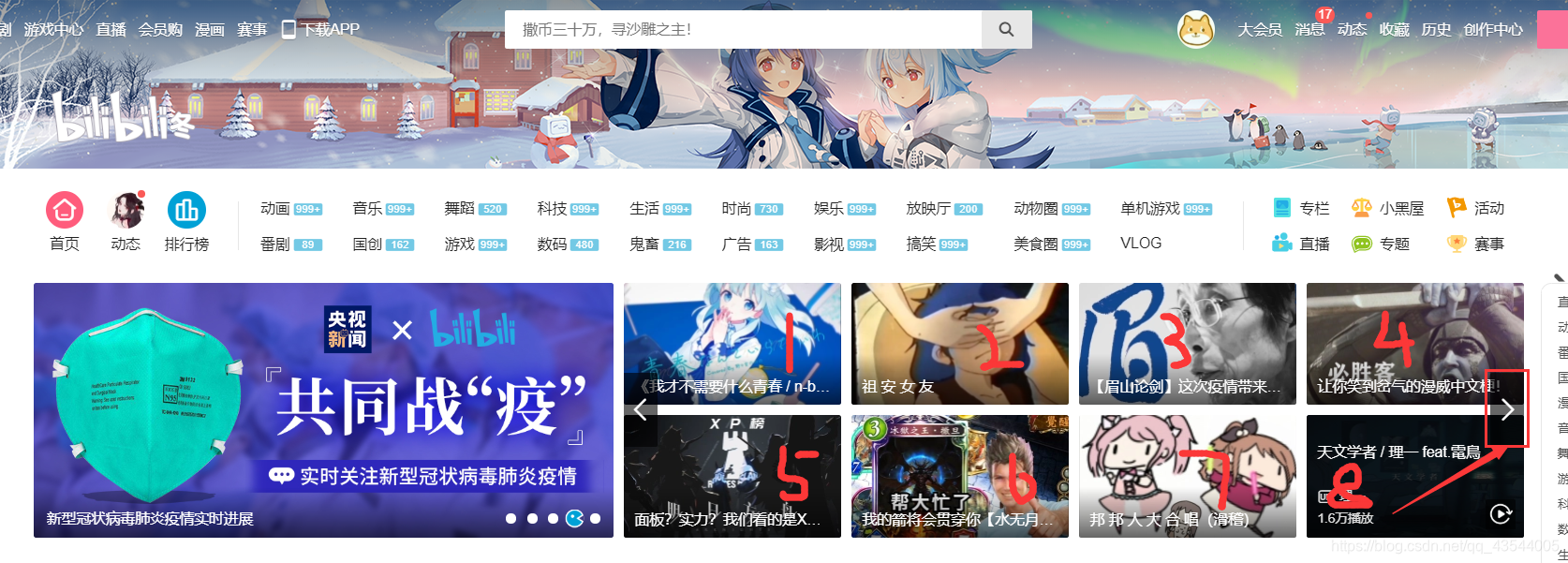
若直接发送请求获取响应,只能的到8个视频的url和名字,其实这一栏共有24个视频信息,但这个是轮播图,不能一次性得到。起先,我试图通过抓包,希望能够得到接口地址,得到所有信息。但事与愿违,经过使用开发者工具及分析页面源码,我发现这个网页 用的vue的响应式,就是监听左右翻,然后把对应页数里的数据改到html上的href的里面 不是xhr请求。翻页更新是通过js改的html的数据。与是乎,我想到了用selenium来进行 翻页操作。并用
webdriver.Chrome().page_source来获取当前网页源码,来获得翻页后的视频信息。
上代码:
#通过selenium 间隔0.1秒点击3次 右翻页 获取 视频的名称 地址
video_names = []
video_urls = []
chrome = webdriver.Chrome()
url = 'https://www.bilibili.com/'
chrome.get(url)
for i in range(3):
response = chrome.page_source
e = etree.HTML(response)
video_names += e.xpath('//div[@class="info"]/p[@class="title"]/text()')
video_urls += e.xpath('//div[@class="recommend-box"]//a/@href')
chrome.find_element_by_xpath('//i[@class="bilifont bili-icon_caozuo_xiangyou"]').click() #点击翻页
time.sleep(0.1)
此时,得到了 两个列表,一个是视频名,视频url。各有24个元素,对应24个视频。
接下来我们要 进入具体某个视频 得到其他信息。
经过对网页的分析,其过程我不再赘述。发现了储存点赞 投币 收藏 信息的网址 格式为:
aid
url = 'https://api.bilibili.com/x/web-interface/archive/stat?aid='

数据形式以json形式展现
而弹幕是存放在一个xml文件地址里的
cid
xml_url='http://comment.bilibili.com/{}.xml'.format(cids[i])
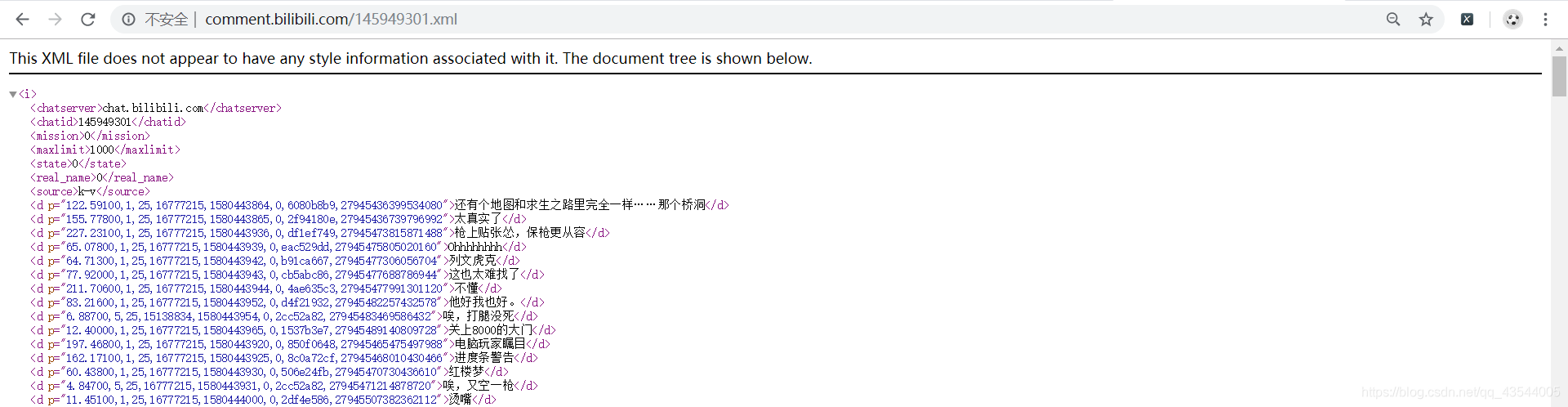
举个栗子
<d p="122.59100,1,25,16777215,1580443864,0,6080b8b9,27945436399534080">还有个地图和求生之路里完全一样……那个桥洞</d>
这其中,122.59100指的是 弹幕在视频出现的时间戳,27945436399534080指的是弹幕发送时的时间戳。分别需要转化为x分x秒,x月x日x时x秒。具体代码:
# # #----------------------------------------------------------------弹幕内容 时间--------------------------------------------------------------------------
# 合成弹幕xml文件地址
xml_url='http://comment.bilibili.com/{}.xml'.format(cids[i])
response = requests.get(url=xml_url)
response.encoding = 'utf-8_sig'
# print(response.text)
Barrage_html = response.text
soup = BS(Barrage_html, 'lxml')
all_d = soup.select('d')
for d in all_d:
# 把d标签中P的各个属性分离开
Barrage_list = d['p'].split(',')
# d.get_text()是弹幕内容
Barrage_list.append(d.get_text())
#删去xml解析信息的列表里,不要的元素
for i in range(3):
del Barrage_list[1]
for j in range(3):
del Barrage_list[2]
#将弹幕在视频出现的时间戳,转化并替换为 分 秒
total_time = time.strftime("%M:%S", time.gmtime(float(Barrage_list[0])))
del Barrage_list[0]
Barrage_list.insert(0, total_time)
#将时间戳转化为北京时间,并替换
timeNum = int(Barrage_list[1])
timeArray = time.localtime(timeNum)
otherStyleTime = time.strftime("%m-%d %H:%M", timeArray)
del Barrage_list[1]
Barrage_list.insert(1, otherStyleTime)
#d弹幕在视频的时间
video_time = Barrage_list[0]
#发送弹幕时间
Barrage_time = Barrage_list[1]
#弹幕内容
Barrage_content = Barrage_list[2]
在线人数信息的获取,需要aid
向wss://broadcast.chat.bilibili.com:7823/sub发送请求建立连接。
def connect(plz):
url = "wss://broadcast.chat.bilibili.com:7823/sub"
normal = base64.b64decode('AAAAIQASAAEAAAACAAAACQAAW29iamVjdCBPYmplY3Rd')
ws = websocket.create_connection(url, timeout=10)
ws.send(bytes(plz))
get = ws.recv()
# print(get)
ws.send(bytes(normal))
get = ws.recv()
# print(get)
if get.find(b'online') != -1:
# online = get_online(get)
online = get_online(get)
return online
else:
print("None")
def get_online_from_av(av):
send = make_send(av)
online = connect(send)
return online
audience_online = get_online_from_av(avid)
最后将得到 信息返回, 写入数据库。
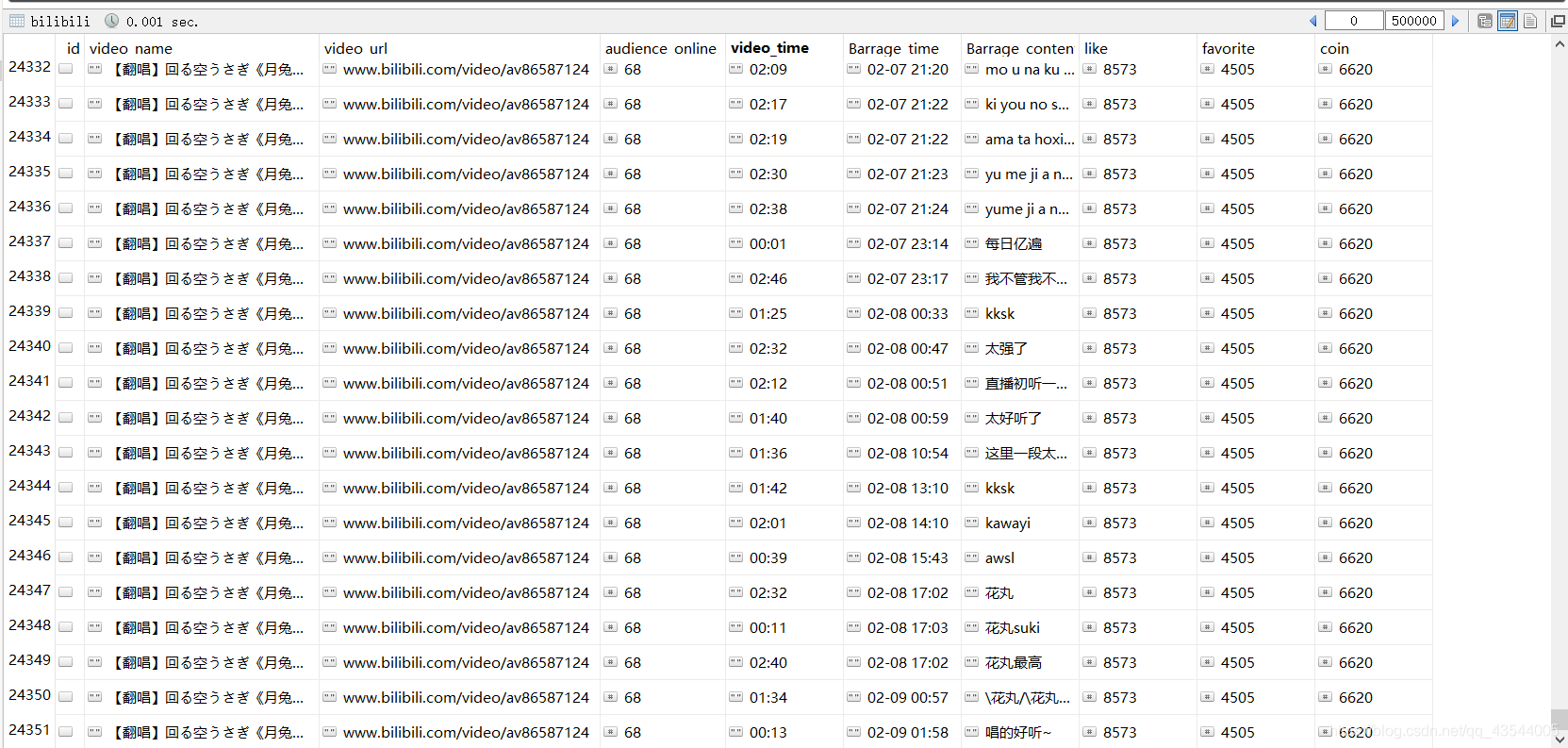
共计24351行。
其他小的问题,利用好
都没问题,善于使用搜索引擎,省时又省力。

Github也是一个不错的好地方。
