目录
一、论文
二、网络结构
三、代码
四、翻译
1、介绍
2、相关工作
3、方法
4、实验结果
一、论文
《Multi-Level Wavelet Convolutional Neural Networks》
摘要:在计算机视觉中,卷积网络(CNN)通常采用合并来扩大接收域,其优点是计算复杂度低。 但是,合并可能导致信息丢失,因此不利于进一步的操作,例如特征提取和分析。 最近,已经提出了扩张滤波器来在接收场大小和效率之间进行折衷。 但是,伴随的网格化效果可能导致对具有棋盘格图案的输入图像进行稀疏采样。 为了解决这个问题,在本文中,我们提出了一种新颖的多级小波CNN(MWCNN)模型,以在接收场大小和计算效率之间取得更好的折衷。 核心思想是将小波变换嵌入CNN架构中,以降低特征图的分辨率,同时增加接收场。 具体来说,用于图像恢复的MWCNN基于U-Net架构,并且部署了逆小波变换(IWT)来重建高分辨率(HR)特征图。 提出的MWCNN也可以看作是对扩张滤波器的改进和对平均池化的概括,并且不仅可以应用于图像恢复任务,而且可以应用于需要池化操作的任何CNN。
实验结果证明了所提出的MWCNN在诸如图像去噪,单图像超分辨率,JPEG图像伪影去除和对象分类等任务上的有效性。
二、网络结构

从WPT到MWCNN。 直观地讲,WPT可以看作是我们的MWCNN的特例,没有(a)和(b)所示的CNN块。 通过将CNN块插入WPT,我们将MWCNN设计为(b)。 显然,我们的MWCNN是多级WPT的概括,当每个CNN块成为身份映射时,将其简化为WPT。

图3.多级小波CNN架构。 它由两部分组成:收缩和扩展子网。 每个实体框对应一个多通道要素图。 通道数标注在框的顶部。 卷积层数设置为24。此外,通过复制第三级子网的配置,我们的MWCNN可以进一步扩展到更高的级别。

图4.平均池,膨胀滤波器和建议的MWCNN的图示。 以一个CNN块为例:(a)因数为2的求和合并会导致最显着的信息丢失,不适合图像恢复; (b)速率为2的膨胀滤波等于子图像上的共享参数卷积; (c)拟议的MWCNN首先将图像分解为4个子带,然后将它们合并为CNN块的输入。 然后,将IWT用作上采样层以恢复图像的分辨率。
三、代码
代码下载:https://github.com/lpj-github-io/MWCNNv2/tree/master/MWCNN_code
from model import common
import torch
import torch.nn as nn
import scipy.io as sio
def make_model(args, parent=False):
return MWCNN(args)
class MWCNN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(MWCNN, self).__init__()
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
self.scale_idx = 0
nColor = args.n_colors
act = nn.ReLU(True)
self.DWT = common.DWT()
self.IWT = common.IWT()
n = 1
m_head = [common.BBlock(conv, nColor, n_feats, kernel_size, act=act)]
d_l0 = []
d_l0.append(common.DBlock_com1(conv, n_feats, n_feats, kernel_size, act=act, bn=False))
d_l1 = [common.BBlock(conv, n_feats * 4, n_feats * 2, kernel_size, act=act, bn=False)]
d_l1.append(common.DBlock_com1(conv, n_feats * 2, n_feats * 2, kernel_size, act=act, bn=False))
d_l2 = []
d_l2.append(common.BBlock(conv, n_feats * 8, n_feats * 4, kernel_size, act=act, bn=False))
d_l2.append(common.DBlock_com1(conv, n_feats * 4, n_feats * 4, kernel_size, act=act, bn=False))
pro_l3 = []
pro_l3.append(common.BBlock(conv, n_feats * 16, n_feats * 8, kernel_size, act=act, bn=False))
pro_l3.append(common.DBlock_com(conv, n_feats * 8, n_feats * 8, kernel_size, act=act, bn=False))
pro_l3.append(common.DBlock_inv(conv, n_feats * 8, n_feats * 8, kernel_size, act=act, bn=False))
pro_l3.append(common.BBlock(conv, n_feats * 8, n_feats * 16, kernel_size, act=act, bn=False))
i_l2 = [common.DBlock_inv1(conv, n_feats * 4, n_feats * 4, kernel_size, act=act, bn=False)]
i_l2.append(common.BBlock(conv, n_feats * 4, n_feats * 8, kernel_size, act=act, bn=False))
i_l1 = [common.DBlock_inv1(conv, n_feats * 2, n_feats * 2, kernel_size, act=act, bn=False)]
i_l1.append(common.BBlock(conv, n_feats * 2, n_feats * 4, kernel_size, act=act, bn=False))
i_l0 = [common.DBlock_inv1(conv, n_feats, n_feats, kernel_size, act=act, bn=False)]
m_tail = [conv(n_feats, nColor, kernel_size)]
self.head = nn.Sequential(*m_head)
self.d_l2 = nn.Sequential(*d_l2)
self.d_l1 = nn.Sequential(*d_l1)
self.d_l0 = nn.Sequential(*d_l0)
self.pro_l3 = nn.Sequential(*pro_l3)
self.i_l2 = nn.Sequential(*i_l2)
self.i_l1 = nn.Sequential(*i_l1)
self.i_l0 = nn.Sequential(*i_l0)
self.tail = nn.Sequential(*m_tail)
def forward(self, x):
x0 = self.d_l0(self.head(x))
x1 = self.d_l1(self.DWT(x0))
x2 = self.d_l2(self.DWT(x1))
x_ = self.IWT(self.pro_l3(self.DWT(x2))) + x2
x_ = self.IWT(self.i_l2(x_)) + x1
x_ = self.IWT(self.i_l1(x_)) + x0
x = self.tail(self.i_l0(x_)) + x
return x
def set_scale(self, scale_idx):
self.scale_idx = scale_idximport math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
def default_conv(in_channels, out_channels, kernel_size, bias=True, dilation=1):
return nn.Conv2d(
in_channels, out_channels, kernel_size,
padding=(kernel_size//2)+dilation-1, bias=bias, dilation=dilation)
def default_conv1(in_channels, out_channels, kernel_size, bias=True, groups=3):
return nn.Conv2d(
in_channels,out_channels, kernel_size,
padding=(kernel_size//2), bias=bias, groups=groups)
#def shuffle_channel()
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
def pixel_down_shuffle(x, downsacale_factor):
batchsize, num_channels, height, width = x.size()
out_height = height // downsacale_factor
out_width = width // downsacale_factor
input_view = x.contiguous().view(batchsize, num_channels, out_height, downsacale_factor, out_width,
downsacale_factor)
num_channels *= downsacale_factor ** 2
unshuffle_out = input_view.permute(0,1,3,5,2,4).contiguous()
return unshuffle_out.view(batchsize, num_channels, out_height, out_width)
def sp_init(x):
x01 = x[:, :, 0::2, :]
x02 = x[:, :, 1::2, :]
x_LL = x01[:, :, :, 0::2]
x_HL = x02[:, :, :, 0::2]
x_LH = x01[:, :, :, 1::2]
x_HH = x02[:, :, :, 1::2]
return torch.cat((x_LL, x_HL, x_LH, x_HH), 1)
def dwt_init(x):
x01 = x[:, :, 0::2, :] / 2
x02 = x[:, :, 1::2, :] / 2
x1 = x01[:, :, :, 0::2]
x2 = x02[:, :, :, 0::2]
x3 = x01[:, :, :, 1::2]
x4 = x02[:, :, :, 1::2]
x_LL = x1 + x2 + x3 + x4
x_HL = -x1 - x2 + x3 + x4
x_LH = -x1 + x2 - x3 + x4
x_HH = x1 - x2 - x3 + x4
return torch.cat((x_LL, x_HL, x_LH, x_HH), 1)
def iwt_init(x):
r = 2
in_batch, in_channel, in_height, in_width = x.size()
#print([in_batch, in_channel, in_height, in_width])
out_batch, out_channel, out_height, out_width = in_batch, int(
in_channel / (r ** 2)), r * in_height, r * in_width
x1 = x[:, 0:out_channel, :, :] / 2
x2 = x[:, out_channel:out_channel * 2, :, :] / 2
x3 = x[:, out_channel * 2:out_channel * 3, :, :] / 2
x4 = x[:, out_channel * 3:out_channel * 4, :, :] / 2
h = torch.zeros([out_batch, out_channel, out_height, out_width]).float().cuda()
h[:, :, 0::2, 0::2] = x1 - x2 - x3 + x4
h[:, :, 1::2, 0::2] = x1 - x2 + x3 - x4
h[:, :, 0::2, 1::2] = x1 + x2 - x3 - x4
h[:, :, 1::2, 1::2] = x1 + x2 + x3 + x4
return h
class Channel_Shuffle(nn.Module):
def __init__(self, conv_groups):
super(Channel_Shuffle, self).__init__()
self.conv_groups = conv_groups
self.requires_grad = False
def forward(self, x):
return channel_shuffle(x, self.conv_groups)
class SP(nn.Module):
def __init__(self):
super(SP, self).__init__()
self.requires_grad = False
def forward(self, x):
return sp_init(x)
class Pixel_Down_Shuffle(nn.Module):
def __init__(self):
super(Pixel_Down_Shuffle, self).__init__()
self.requires_grad = False
def forward(self, x):
return pixel_down_shuffle(x, 2)
class DWT(nn.Module):
def __init__(self):
super(DWT, self).__init__()
self.requires_grad = False
def forward(self, x):
return dwt_init(x)
class IWT(nn.Module):
def __init__(self):
super(IWT, self).__init__()
self.requires_grad = False
def forward(self, x):
return iwt_init(x)
class MeanShift(nn.Conv2d):
def __init__(self, rgb_range, rgb_mean, rgb_std, sign=-1):
super(MeanShift, self).__init__(3, 3, kernel_size=1)
std = torch.Tensor(rgb_std)
self.weight.data = torch.eye(3).view(3, 3, 1, 1)
self.weight.data.div_(std.view(3, 1, 1, 1))
self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean)
self.bias.data.div_(std)
self.requires_grad = False
if sign==-1:
self.create_graph = False
self.volatile = True
class MeanShift2(nn.Conv2d):
def __init__(self, rgb_range, rgb_mean, rgb_std, sign=-1):
super(MeanShift2, self).__init__(4, 4, kernel_size=1)
std = torch.Tensor(rgb_std)
self.weight.data = torch.eye(4).view(4, 4, 1, 1)
self.weight.data.div_(std.view(4, 1, 1, 1))
self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean)
self.bias.data.div_(std)
self.requires_grad = False
if sign==-1:
self.volatile = True
class BasicBlock(nn.Sequential):
def __init__(
self, in_channels, out_channels, kernel_size, stride=1, bias=False,
bn=False, act=nn.ReLU(True)):
m = [nn.Conv2d(
in_channels, out_channels, kernel_size,
padding=(kernel_size//2), stride=stride, bias=bias)
]
if bn: m.append(nn.BatchNorm2d(out_channels))
if act is not None: m.append(act)
super(BasicBlock, self).__init__(*m)
class BBlock(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(BBlock, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x).mul(self.res_scale)
return x
class DBlock_com(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DBlock_com, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=3))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x)
return x
class DBlock_inv(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DBlock_inv, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=3))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x)
return x
class DBlock_com1(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DBlock_com1, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=1))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x)
return x
class DBlock_inv1(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DBlock_inv1, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=1))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x)
return x
class DBlock_com2(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DBlock_com2, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x)
return x
class DBlock_inv2(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DBlock_inv2, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
m.append(conv(in_channels, out_channels, kernel_size, bias=bias, dilation=2))
if bn: m.append(nn.BatchNorm2d(out_channels, eps=1e-4, momentum=0.95))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x)
return x
class ShuffleBlock(nn.Module):
def __init__(
self, conv, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1,conv_groups=1):
super(ShuffleBlock, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias))
m.append(Channel_Shuffle(conv_groups))
if bn: m.append(nn.BatchNorm2d(out_channels))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x).mul(self.res_scale)
return x
class DWBlock(nn.Module):
def __init__(
self, conv, conv1, in_channels, out_channels, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(DWBlock, self).__init__()
m = []
m.append(conv(in_channels, out_channels, kernel_size, bias=bias))
if bn: m.append(nn.BatchNorm2d(out_channels))
m.append(act)
m.append(conv1(in_channels, out_channels, 1, bias=bias))
if bn: m.append(nn.BatchNorm2d(out_channels))
m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
x = self.body(x).mul(self.res_scale)
return x
class ResBlock(nn.Module):
def __init__(
self, conv, n_feat, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(ResBlock, self).__init__()
m = []
for i in range(2):
m.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn: m.append(nn.BatchNorm2d(n_feat))
if i == 0: m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x).mul(self.res_scale)
res += x
return res
class Block(nn.Module):
def __init__(
self, conv, n_feat, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(Block, self).__init__()
m = []
for i in range(4):
m.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn: m.append(nn.BatchNorm2d(n_feat))
if i == 0: m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x).mul(self.res_scale)
# res += x
return res
class Upsampler(nn.Sequential):
def __init__(self, conv, scale, n_feat, bn=False, act=False, bias=True):
m = []
if (scale & (scale - 1)) == 0: # Is scale = 2^n?
for _ in range(int(math.log(scale, 2))):
m.append(conv(n_feat, 4 * n_feat, 3, bias))
m.append(nn.PixelShuffle(2))
if bn: m.append(nn.BatchNorm2d(n_feat))
if act: m.append(act())
elif scale == 3:
m.append(conv(n_feat, 9 * n_feat, 3, bias))
m.append(nn.PixelShuffle(3))
if bn: m.append(nn.BatchNorm2d(n_feat))
if act: m.append(act())
else:
raise NotImplementedError
super(Upsampler, self).__init__(*m)
四、翻译
1、介绍
如今,卷积网络已成为许多计算机视觉任务(例如计算机视觉任务)背后的主导技术。图像恢复[1] – [5]和对象分类[6] – [10]。 随着CNN的不断发展,可以在大型数据集上广泛轻松地学习CNN,而通过日益先进的GPU设备可以加快CNN的学习速度,并且与传统方法相比,CNN经常具有最先进的性能。 CNN在计算机视觉中很受欢迎的原因可以归结为两个方面。 首先,现有的基于CNN的解决方案在性能上优于其他方法,例如单图像超分辨率(SISR)[1],[2],[11],图像去噪[5],图像, 去模糊[12],压缩图像[13]和对象分类[6]。 其次,CNN可以作为模块的一部分并插入传统方法中,这也促进了CNN的广泛使用[12],[14],[15]。
实际上,计算机视觉中的CNN可以看作是从输入图像到目标的非线性映射。 通常,较大的接收场有助于通过考虑更多的空间环境来提高CNN的拟合能力并提高准确的性能。 通常,可以通过增加网络深度,扩大滤波器大小或使用合并操作来扩大接收场。 但是,增加网络深度或扩大过滤器大小不可避免地会导致更高的计算成本。 合并可以通过直接降低特征图的空间分辨率来扩大接收范围并确保效率。 但是,这可能会导致信息丢失。 最近,有人提出通过在卷积滤波中插入“零孔”来扩大接收滤波[8],从而在接收场大小和效率之间进行权衡。然而,固定因子大于1的膨胀滤波的接收场仅考虑到具有棋盘格模式的输入的稀疏采样,因此可能导致固有的网格效应[16]。 根据以上分析,可以看出,如果要避免增加计算负担并避免潜在的性能损失,则在扩大接受域时应格外小心。 从图1可以看出,尽管DRRN [17]和MemNet [19]比VDSR [2]和DnCNN [5]拥有更大的接收场和更高的PSNR性能,但是它们的速度却慢了几个数量级。
为了解决前面提到的问题,我们提出了一种有效的基于CNN的方法,旨在在性能和效率之间进行权衡。 更具体地说,我们提出了一种利用离散小波变换(DWT)代替合并操作的多级小波CNN(MWCNN)。 由于DWT的可逆性,所提出的下采样方案不会丢失任何图像信息或中间特征。 而且,特征图的频率和位置信息都由DWT [21],[22]捕获,这有助于在使用多频特征表示时保留详细的纹理。更具体地说,我们采用带扩展卷积层的逆小波变换(IWT)来还原图像恢复任务中特征图的分辨率,其中U-Net架构[23]被用作骨干网络架构。 而且,采用逐元素求和来组合特征图,从而丰富了特征表示。
从与相关工作的关系来看,我们表明膨胀滤波可以被解释为MWCNN的一种特殊变体,并且所提出的方法在扩大接收领域方面更为通用和有效。 使用经过集成多级小波训练的此类网络的整体,我们可以获得PSNR / SSIM值,该值在图像恢复任务(例如图像去噪,SISR和JPEG图像伪影去除)中的最佳已知结果上得到了改善。对于对象分类的任务,与采用池化层时相比,所提出的MWCNN可以实现更高的性能。 如图1所示,尽管MWCNN比LapSRN [3],DnCNN [5]和VDSR [2]慢一些,但是MWCNN可以具有更大的接收场并获得更高的PSNR值。
本文是我们先前工作的延伸[24]。 与以前的工作[24]相比,我们提出了一种更通用的方法来提高性能,将其进一步扩展到高层任务,并提供更多的分析和讨论。总而言之,这项工作的贡献包括:
•一个新颖的MWCNN模型,通过引入小波变换来扩大接收范围,并在效率和恢复性能之间取得更好的平衡。
•由于DWT具有良好的时频定位特性,因此有希望保留细节。
•在使用池化操作的任何CNN中嵌入小波变换的通用方法。
•在图像去噪,SISR,JPEG图像伪影去除和分类方面具有最先进的性能。
在本文的其余部分安排如下。 第二部分简要回顾了用于图像恢复和分类的CNN的发展。 第三部分详细描述了提出的MWCNN模型。 第四部分报告了性能评估方面的实验结果。 最后,总结论文。
2、相关工作
在本节中,将简要回顾用于图像恢复任务的CNN的开发。 特别是,我们讨论了将DWT纳入CNN的相关工作。 最后,介绍了相关的对象分类工作。
A.图像恢复
图像恢复旨在从其退化的观察值y中恢复潜在的清洁图像x。 几十年来,已经从先前的建模和判别学习的角度对图像恢复进行了研究[25] – [30]。最近,随着蓬勃发展,基于CNN的方法比传统方法具有最先进的性能。
1)提高CNNS的图像恢复性能和效率
在早期尝试中,基于CNN的方法在某些图像恢复任务上效果不佳。 例如,与BM3D [27]在2007年相比,[31]-[33]的方法无法实现最新的降噪性能。在[34]中,多层感知(MLP)的性能可与BM3D媲美。 学习从噪声补丁到干净补丁的映射。 2014年,Dong等人。 [1]首次仅采用了三层FCN,而没有为SISR合并,这仅实现了较小的接收场,但实现了最新的性能。 然后,董等人 [35]提出了一种用于减少JPEG图像伪影的4层ARCNN。
近来,越来越多的深层网络被用于图像恢复。 对于SISR,Kim等人[2]堆叠了一个20层的CNN,具有残余学习和可调整的梯度裁剪功能。 随后,一些工作,例如非常深的网络[5],[36],[37],对称跳过连接[20],残差单元[11],拉普拉斯金字塔[3]和递归架构[17],[ 38],也有人建议扩大接受领域。 但是,随着网络深度的增加,这些方法的接受领域会扩大,这可能会扩展到更深的网络。
为了在速度和性能之间取得更好的平衡,Zhang等人提出了一种带有扩张滤波功能的7层FCN作为降噪器。 [12]。 Santhanam等。 [39]采用池化/池化来获得和聚合多上下文表示以进行图像降噪。 在[40]中,Zhang等。考虑在降采样的子图像上使用CNN去噪器。 郭等。 [41]利用基于U-Net [23]的CNN作为非盲降噪器。 考虑到SISR的特殊性,可以通过以低分辨率(LR)图像作为输入并使用上采样操作放大特征来更好地权衡接收场大小和效率[4],[18],[42] 。 但是,该策略只能用于SISR,不适用于其他任务,例如图像去噪和JPEG图像伪影去除。
2)图像恢复的普遍性
考虑到诸如图像去噪,SISR和JPEG图像伪影去除等任务的相似性,只需通过重新训练同一网络即可将针对一项任务建议的模型轻松扩展至其他图像恢复任务。 例如,DnCNN [5]和MemNet [19]均已在所有这三个任务上进行了评估。 此外,CNN去噪器还可以用作即插即用的一种。 因此,任何恢复任务都可以通过结合展开的推论[12]依次应用CNN降噪器来解决。为了提供明确的功能来定义由去噪器引起的正则化,Romano等人。 [14]进一步提出了一种去噪的正则化框架。 在[43]和[44]中,具有模糊核的LR图像被合并到用于非盲SR的CNN中。 这些方法不仅促进了CNN在低视力中的应用,而且提出了为其他图像恢复任务部署CNN去噪器的解决方案。
3)在CNNS中合并DWT
还进行了一些研究,将小波变换合并到CNN中。 Bae等。 [45]提出了一种小波残差网络(WavResNet),发现了CNN学习可以受益于具有更多信道特征的小波子带的学习。 为了恢复子带中丢失的细节,Guo等人。 [46]提出了一种深小波超分辨率(DWSR)方法。 随后,针对低剂量CT和反问题开发了深度卷积框架(DCF)[47],[48]。 但是,在WavResNet和DWSR中仅考虑了一级小波分解,这可能会限制小波变换的应用。 受到分解观点的启发,DCF独立处理每个子带,这些子带自发地忽略了这些子带之间的依赖性。 相比之下,我们的MWCNN考虑了多级小波变换,以扩大接收域,其中计算负担几乎没有增加..
B.对象分类
AlexNet [6]是一个用于对象分类的8层网络,并且在ILSVRC2012数据集上首次实现了比其他方法更高的性能。 在这种方法中,采用了不同大小的滤波器来提取和增强特征。 但是,Simonyan和Zisserman [7]发现,仅使用3×3尺寸的卷积滤波器,具有更深的体系结构,就可以实现更大的接收场并获得比AlexNet更好的性能。 Yu和Koltun [8]采用了扩展的卷积来扩大接收场的大小,而不增加计算负担。 后来,提出了残差块[9],[10],初始模型[49],金字塔结构[50],双CNN [51]和其他结构[52],[53]用于对象分类。 还提出了一些关于池化操作的措施,例如并行网格池[54]和二阶池的门控混合[55],以增强特征提取器或特征表示以提高性能。 通常,通常采用诸如平均池和最大池之类的池操作来进行下采样功能和扩大接收域,但它可能导致大量信息丢失。 为了避免这种不利影响,我们通过在不更改主体系结构的情况下替换池化操作而将DWT用作我们的下采样层,从而获得了增强功能表示的更多功能。
3、方法
在本节中,我们首先简要介绍多级小波包变换(WPT)的概念并提供我们的动机。 然后,我们正式提出基于多层WPT的MWCNN,并描述其用于图像还原和对象分类的网络体系结构。 最后,提出了讨论以分析MWCNN与平均池和扩张滤波的联系。
A.从多层次WPT到MWCNN
给定一个图像x,我们可以使用带有四个卷积滤波器的2D DWT [56],即低通滤波器![]() 和高通滤波器
和高通滤波器![]() 将x分解为四个子带图像,即
将x分解为四个子带图像,即![]() 。 请注意,在转换过程中,四个滤波器的卷积步长为2,具有固定的参数。 以Haar小波为例,四个滤波器定义为
。 请注意,在转换过程中,四个滤波器的卷积步长为2,具有固定的参数。 以Haar小波为例,四个滤波器定义为
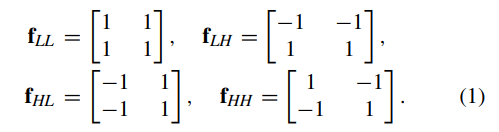
显然,fLL,fLH,fHL和fHH彼此正交,并形成4×4可逆矩阵。 DWT的操作定义为![]() ,
,![]() 其中
其中![]() 表示卷积算符,
表示卷积算符,![]() 表示因子为2的标准下采样算子。换句话说,DWT在数学上涉及四个跨度为2的固定卷积滤波器,以实现下采样算子。 此外,根据Haar变换[56]的理论,二维Haar变换后
表示因子为2的标准下采样算子。换句话说,DWT在数学上涉及四个跨度为2的固定卷积滤波器,以实现下采样算子。 此外,根据Haar变换[56]的理论,二维Haar变换后![]() 的第(i,j)个值可写为
的第(i,j)个值可写为

尽管部署了下采样操作,但是由于DWT的双正交性,IWT可以准确地重建原始图像x而不会丢失信息,即![]() 。 对于Haar小波,IWT可以定义如下:
。 对于Haar小波,IWT可以定义如下:

通常,子带图像xLL,xLH,xHL和xHH可以由DWT顺序分解,以便在多级WPT中进行进一步处理[22],[57]。 为了获得两级WPT的结果,分别使用DWT将每个子带图像![]() 分解为四个子带图像
分解为四个子带图像![]() 。 递归地,可以获得三级或更高级别WPT的结果。相应地,通过IWT通过完全逆运算来实现每个级别子带图像的重构。 图2(a)中说明了图像的上述分解和重建过程。 如果我们将WPT的过滤器视为具有预定义权重的卷积滤波器,则可以看到WPT是FCN的一种特殊情况,没有非线性层。 显然,原始图像x可以先通过WPT分解,然后再通过逆WPT进行精确重构而不会丢失任何信息。
。 递归地,可以获得三级或更高级别WPT的结果。相应地,通过IWT通过完全逆运算来实现每个级别子带图像的重构。 图2(a)中说明了图像的上述分解和重建过程。 如果我们将WPT的过滤器视为具有预定义权重的卷积滤波器,则可以看到WPT是FCN的一种特殊情况,没有非线性层。 显然,原始图像x可以先通过WPT分解,然后再通过逆WPT进行精确重构而不会丢失任何信息。

图2.从WPT到MWCNN。 直观地讲,WPT可以看作是我们的MWCNN的特例,没有(a)和(b)所示的CNN块。 通过将CNN块插入WPT,我们将MWCNN设计为(b)。 显然,我们的MWCNN是多级WPT的概括,当每个CNN块成为身份映射时,将其简化为WPT。
在图像处理应用中,例如图像去噪和压缩,通常需要一些操作,例如软阈值和量化,以处理分解部分[58],[59],如图所示。 2(a)。这些操作可以视为针对特定任务的某种非线性。 在这项工作中,我们通过将CNN块插入传统的基于WPT的方法中,将WPT扩展到多级小波CNN(MWCNN),如图2(b)所示。由于WPT具有双正交性,因此我们的MWCNN可以使用二次采样和上采样 安全操作,不会造成信息丢失。 显然,我们的MWCNN是多级WPT的概括,当每个CNN块成为身份映射时,将其简化为WPT。 此外,DWT可被视为下采样操作,并扩展到需要池化操作的任何CNN。
B.网络体系结构
1)图像恢复
如前所述。 III-A,我们基于WPT的原理设计了用于图像恢复的MWCNN架构,如图2(b)所示。 关键思想是在DWT的每个级别之前(或之后)将CNN块插入WPT。 如图3所示,每个CNN块都是一个三层FCN,没有池,并以低频子带和高频子带为输入。 更具体地讲,每一层都包含3×3滤波器(Conv)和整流线性单位(ReLU)操作的卷积。在最后一层仅采用Conv来预测残差结果。 卷积层数设置为24。有关MWCNN设置的更多详细信息,请参阅图3。
我们的MWCNN在三个方面修改了U-Net。 (i)在常规的U-Net中,池化和反卷积被用作下采样和上采样层。 相比之下MWCNN中使用了DWT和IWT。 (ii)在DWT之后,我们部署了另一个CNN块,以减少用于紧凑表示和建模带间相关性的特征图通道的数量。 然后采用卷积增加特征图通道的数量,并利用IWT对特征图进行升采样。 相比之下,传统的采用卷积层的U-Net用于增加特征图通道,这对合并后的特征图通道数没有影响。 对于上采样,直接采用去卷积层来放大特征图。(iii)在MWCNN中,使用逐元素求和来合并来自收缩和扩展子网的特征图。在传统的U-Net中,采用了串联。 与我们之前的工作[24]相比,我们进行了如下改进:(i)代替使用DWT直接分解输入图像,我们首先使用conv块从输入中提取特征,这从经验上证明对图像恢复是有益的 。 (ii)在第三层次中,我们使用更多的特征图来增强特征表示。 在我们的实现中,MWCNN中采用Haar小波作为默认小波。 我们的实验中也考虑了其他小波,例如Daubechies 2(DB2)。
用![]() 表示MWCNN的网络参数,即
表示MWCNN的网络参数,即![]() 是网络输出。 令
是网络输出。 令![]() 为训练集,其中yi为第i个输入图像,xi为相应的地面真实图像。 然后通过以下公式给出学习MWCNN的目标函数
为训练集,其中yi为第i个输入图像,xi为相应的地面真实图像。 然后通过以下公式给出学习MWCNN的目标函数

通过最小化目标函数,采用ADAM算法[60]训练MWCNN。
2)扩展对象分类
与图像恢复类似,DWT通常用作下采样操作,而无需上采样操作来代替合并操作。 DWT变换后,随后使用具有1⇥1 Conv的压缩滤波器。请注意,我们不会修改其他冻结或损失函数。通过此改进,可以通过自适应学习进一步选择和增强功能。 此外,可以考虑使用任何使用池化的CNN代替DWT操作,并且可以将特征图的信息传输到下一层而不会丢失信息。 DWT可以看作是安全的下采样模块,可以插入任何CNN中,而无需更改网络体系结构,并且可以为不同任务提取更强大的功能。
C.讨论
1)连接到池操作所提出的MWCNN中的DWT与池操作和扩张过滤密切相关。 以Haar小波为例,我们解释了DWT和平均池之间的联系。 根据因子为2的平均池化理论,池化后第l层的特征图![]() 的第(i,j)个值可写为
的第(i,j)个值可写为

其中![]() 是合并操作之前的特征图。很显然,等式5与等式2中DWT的低频分量相同,这也意味着所有高频信息在合并操作期间都会丢失。在图4(a)中,特征图首先被分解为步幅为2的四个子图像。平均池化操作可以看作是对所有具有固定系数1/4的子图像求和,以生成新的子图像。 相比之下,DWT使用具有四个固定正交权重的所有子图像来获取四个新的子图像。 通过考虑所有子带,MWCNN因此可以避免由常规子采样引起的信息丢失,并且可以有利于恢复和分类。 因此,平均池可被视为所提出的MWCNN的简化变体。
是合并操作之前的特征图。很显然,等式5与等式2中DWT的低频分量相同,这也意味着所有高频信息在合并操作期间都会丢失。在图4(a)中,特征图首先被分解为步幅为2的四个子图像。平均池化操作可以看作是对所有具有固定系数1/4的子图像求和,以生成新的子图像。 相比之下,DWT使用具有四个固定正交权重的所有子图像来获取四个新的子图像。 通过考虑所有子带,MWCNN因此可以避免由常规子采样引起的信息丢失,并且可以有利于恢复和分类。 因此,平均池可被视为所提出的MWCNN的简化变体。

2)扩展过滤的连接
为了说明MWCNN和膨胀过滤之间的连接,我们首先给出因子2的膨胀过滤的定义:

其中![]() 表示具有因子2的卷积运算,
表示具有因子2的卷积运算,![]() 是卷积核k中的位置,(p,q)是特征xl的卷积范围内的位置。
是卷积核k中的位置,(p,q)是特征xl的卷积范围内的位置。
等式 (6)可以分解为两个步骤,即采样和卷积。 通过在约束p + 2s = i,q + 2t = j的情况下以一个间隔像素在x的中心位置(i,j)进行采样来获得采样补丁。 然后,通过将采样补丁与内核k卷积获得值![]() 。 因此,用因子2进行的膨胀滤波可表示为:首先将一个图像分解为四个子图像,然后在这些子图像上使用共享的标准卷积核,如图所示。 4(b)。 我们重写式。 (6)用于如下获得像素值
。 因此,用因子2进行的膨胀滤波可表示为:首先将一个图像分解为四个子图像,然后在这些子图像上使用共享的标准卷积核,如图所示。 4(b)。 我们重写式。 (6)用于如下获得像素值![]() :
:

然后可以以相同的方式获得像素值![]() 和
和![]() 。 实际上,可以通过在子带图像
。 实际上,可以通过在子带图像![]() 上应用IWT来获得位置
上应用IWT来获得位置![]() 和
和![]() 处的
处的![]() 值 基于等式(3)因此,扩张滤波可以表示为与子带图像的卷积,如下所示:
值 基于等式(3)因此,扩张滤波可以表示为与子带图像的卷积,如下所示:

与扩张滤波不同,图4(c)中的MWCNN定义为![]() ,
,
注意,![]() 可以使用IWT准确地重建
可以使用IWT准确地重建![]() 。 与等式相比 (8),每个子带
。 与等式相比 (8),每个子带![]() 的权重和对应的卷积
的权重和对应的卷积![]() 是不同的。 这意味着如果等式中的IWT之后,子带
是不同的。 这意味着如果等式中的IWT之后,子带![]() 被子图像代替,则我们的MWCNN可以简化为膨胀滤波。 (3),并且k中的卷积
被子图像代替,则我们的MWCNN可以简化为膨胀滤波。 (3),并且k中的卷积![]() 彼此共享。 因此,扩张滤波可以被视为所提出的MWCNN的变体。
彼此共享。 因此,扩张滤波可以被视为所提出的MWCNN的变体。

图5.网格效果的图示。 以3层CNN为例:(a)速率为2的扩张滤波会遭受大量信息丢失;(b)两个相邻像素基于完全不重叠位置的信息;(c)我们的MWCNN 可以完全避免潜在的弊端。
与膨胀滤波相比,MWCNN还可以避免网格效应。 随着深度的增加,固定因子大于1的膨胀滤波仅考虑棋盘格模式中单位的稀疏采样,从而导致大量信息丢失(请参见图5(a))。 扩张滤波的另一个问题是,两个输出相邻像素可能是根据来自完全不重叠的单元的输入信息来计算的(请参见图5(b)),并且可能导致局部信息的不一致。 图5(c)说明了MWCNN的接收场,它与膨胀滤波完全不同。 对于密集采样,卷积滤波器将多频信息作为输入,并在DWT之后导致双接收场。 可以看到,MWCNN能够很好地解决本地信息的稀疏采样和不一致问题,并且有望从数量上受益于恢复
4、实验结果

对于图像去噪,我们考虑三个噪声级别,即“ 15、25和50”,并在三个数据集(即Set12 [5],BSD68 [63]和Urban100 [64])上评估我们的去噪方法。在图像恢复中,为每个降级设置学习MWCNN模型。 采用![]()
![]() 的ADAM算法[60]进行优化,我们使用的最小批量大小为24。学习率从
的ADAM算法[60]进行优化,我们使用的最小批量大小为24。学习率从![]() 呈指数衰减。 在小批量学习期间使用基于旋转或/和翻转的数据增强。
呈指数衰减。 在小批量学习期间使用基于旋转或/和翻转的数据增强。