论文地址:CPN
论文总结
本文方法名为CPN,是个top-down的检测方法,即先用检测器得到人类的bounding box,再使用CPN来检测关键点。CPN是2017年COCO关键点检测的冠军算法。
如名字所言,是一个级联的金字塔网络。CPN由三个子网络组成:Backbone、GlobalNet、RefineNet。其中Backbone用于提取特征,GlobalNet用于融合不同尺度的特征(金字塔),RefineNet用于得到精细的输出。文中Backbone使用的是ResNet。
在训练时,在每个GlobalNet的输出上都添加一个预测,当做“中间监督”,使得收敛更加容易。由于有多个输出,CPN旨在GlobalNet预测出较为“simple”的关键点,但可能对遮挡、不可见的关键点无效;在RefineNet预测出较为“hard”的关键点,为达这个目的,RefineNet输出的损失函数使用online hard-keypoint mining loss,简写为ohkm方法。由于设计时是对GlobalNet和RefineNet有不同的目标期待,所以CPN又称为two-stage的姿态估计方法,RefineNet的名字由来也是对输出的keypoint 进行Refine的意思。

论文介绍
CPN是个two-stage的网络架。GlobalNet使用FPN网络学习好的特征表示,去预测那些可以通过简单特征表现可以看出来的simple joints;RefineNet使用FPN网络得到的金字塔特征,去预测那些不可见、遮挡的hard joints。
CPN所使用的检测器为FPN detector,其将RoIAlign应用在FPN上,COCO数据集的80个类别都正常检测,最后只提取出human bounding box用于pose检测。
CPN所使用的backbone为ResNet,特征提取层(为Keypoints生成heatmaps)为 C 2 ∼ C 5 C2\sim C5 C2∼C5,即每个stage的残差快的最后一个输出。
在特征金字塔与上采样的特征进行element sum之前,使用一个 1 ∗ 1 1*1 1∗1卷积对提取出的特征进行处理。
经过上采样的融合特征,可以添加pose检测器直接预测关节点,即GlobalNet的各级输出。
RefineNet将GlobalNet中不同level的信息进行整合,最后通过上采样到相同尺度后,使用Concat操作结合在一起。而信息整合的过程,如上图所示,在较低level的特征上使用较多的bottleneck blocks,然后一步直接使用大尺度的双线性上采样到指定的输出尺度。RefineNet的损失函数使用ohkm方法后,只对Loss最大的k个joints进行关键点回归。
论文实验
实验细节
Crop策略:对每个human bounding box,都扩展到某个固定的比率(比如 256 : 192 256:192 256:192),然后从没有经过变形操作(长宽比)的图像中进行Crop操作。最后将crop出来的图片Resize到 256 ∗ 192 256*192 256∗192。
数据增强策略:在Crop之后,使用随机flip,随机rotation( − 45 ° ∼ 45 ° -45°\sim45° −45°∼45°),随机Scale( 0.7 ∼ 1.35 0.7\sim1.35 0.7∼1.35)。
在测试时,使用高斯核与predict heamaps上,用以减少预测的方差。
消融学习
在人类检测器上,hard NMS的阈值越高,keypoint检测的效果越好;soft NMS对于detections和key points detections都有效。
从下表可以看出,随着检测框的AP增加,keypoint detection获得的AP增益越来越少。因此,可以认为较高的检测AP已经包含了大部分的medium和large实例。

作者认为,现在姿态检测的关键在于加强姿态估计的难点keypoint的准确率。
在CPN上,使用Hourglass 和 ResNet50作为backbone的实验如下表所示。 2 2 2个stack hourglass已经达到了 8 8 8个stack glass的性能。dialation在浅层应用汇大大增加计算量(FLOPs)。

从上表可以看出,RefineNet的使用,可以为CPN增加2.0的AP。
RefineNet的消融学习如下所示,即(1)直接使用Concat;(2)使用1个bottleneck后使用Concat;(3)使用多个bottleneck后直接使用Concat。在concat后接一个conv生成heatmaps。

ohkm的top-k中的k的消融学习,可以看出在COCO数据集上,K取8时,会得到最好的结果;

损失函数的消融学习:没有中间监督会少0.9AP。

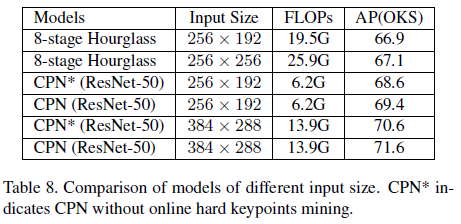
输入尺寸的消融学习:可以看出 256 ∗ 192 256*192 256∗192的效果和 256 ∗ 256 256*256 256∗256差不多,但 256 ∗ 256 256*256 256∗256比 256 ∗ 192 256*192 256∗192多了 6.4 G 6.4G 6.4GFOLPs。