《菜菜的机器学习》笔记
目录
一、逻辑回归
1.回归
线性回归是机器学习中最简单的的回归算法,它写作一个几乎人人熟悉的方程:
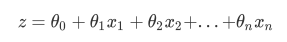
2.二元逻辑回归
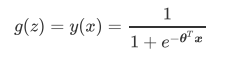
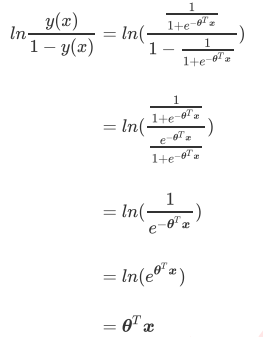
不难发现,y(x)的形似几率取对数的本质其实就是我们的线性回归z,我们实际上是在对线性回归模型的预测结果取对数几率来让其的结果无限逼近0和1。因此,其对应的模型被称为”对数几率回归“(logistic Regression),也就是我们的逻辑回归,这个名为“回归”却是用来做分类工作的分类器。
之前提到过,线性回归的核心任务是通过求解 构建 这个预测函数,并希望预测函数 能够尽量拟合数据,因此逻辑回归的核心任务也是类似的:求解 θ \theta θ来构建一个能够尽量拟合数据的预测函数 y ( x ) y(x) y(x),并通过向预测函数中输入特征矩阵来获取相应的标签值 y y y。
3.损失函数
使用”损失函数“这个评估指标,来衡量参数为 θ \theta θ的模型拟合训练集时产生的信息损失的大小,并以此衡量参数的优劣。如果用一组参数建模后,模型在训练集上表现良好,那我们就说模型拟合过程中的损失很小,损失函数的值很小,这一组参数就优秀。

由于我们追求损失函数的最小值,让模型在训练集上表现最优,可能会引发另一个问题:如果模型在训练集上表示优秀,却在测试集上表现糟糕,模型就会过拟合。虽然逻辑回归和线性回归是天生欠拟合的模型,但我们还是需要控制过拟合的技术来帮助我们调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。
二、sklearn中的逻辑回归
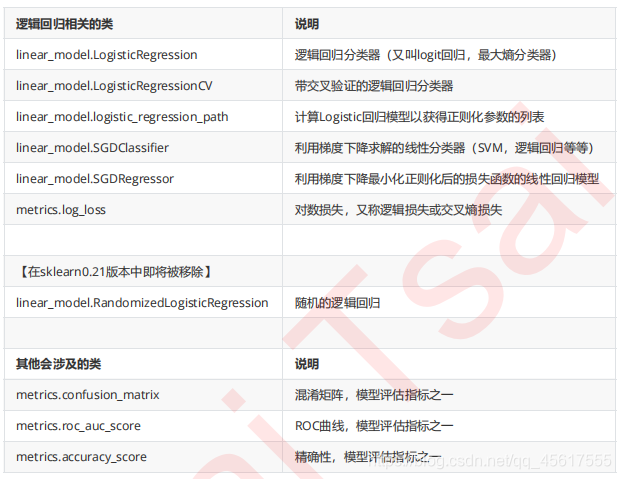
1.sklearn中的回归
2.linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression (
penalty=’l2’,
dual=False,
tol=0.0001,
C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver=’warn’,
max_iter=100,
multi_class=’warn’,
verbose=0,
warm_start=False,
n_jobs=None)
3.重要参数penalty&C
3.1正则化
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量的L1范式和L2范式的倍数来实现。
其中L1范式表现为参数向量中的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开方值。
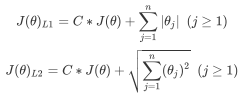

通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。
4.代码
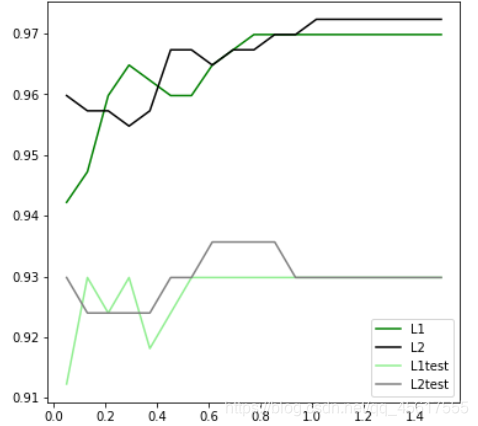
4.1判断L1、L2哪个效果好?
l1 = []
l2 = []
l1test = []
l2test = []
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
for i in np.linspace(0.05,1.5,19):
lrl1 = LR(penalty="l1",solver="liblinear",C=i,max_iter=1000)
lrl2 = LR(penalty="l2",solver="liblinear",C=i,max_iter=1000)
lrl1 = lrl1.fit(Xtrain,Ytrain)
l1.append(accuracy_score(lrl1.predict(Xtrain),Ytrain))
l1test.append(accuracy_score(lrl1.predict(Xtest),Ytest))
lrl2 = lrl2.fit(Xtrain,Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))
graph = [l1,l2,l1test,l2test]
color = ["green","black","lightgreen","gray"]
label = ["L1","L2","L1test","L2test"]
plt.figure(figsize=(6,6))
for i in range(len(graph)):
plt.plot(np.linspace(0.05,1.5,19),graph[i],color[i],label=label[i])
plt.legend(loc=4) #图例的位置在哪里?4表示,右下角
plt.show()
4.2嵌入法
fullx = []
fsx = []
C=np.arange(0.01,10.01,0.5)
for i in C:
LR_ = LR(solver="liblinear",C=i,random_state=420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv=10).mean())
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,X_embedded,data.target,cv=10).mean())
print(max(fsx),C[fsx.index(max(fsx))])
plt.figure(figsize=(20,5))
plt.plot(C,fullx,label="full")
plt.plot(C,fsx,label="feature selection")
plt.xticks(C)
plt.legend()
plt.show()
