LogisticRegression类
逻辑回归的基本思想在前面已经写过,就不再赘述。主要是为了了解并使用scikit-learn中逻辑回归类库,在实践前先整理一下里面的参数、属性和方法。
我们使用
##加载线性模型
from sklearn import linear_model
model=linear_model.LogisticRegression()来加载逻辑回归模型。
【参数(Parameters)】
首先我们来看看LogisticRegression()有哪些参数。
penalty参数:
str, ‘l1’ or ‘l2’, default: ‘l2’
即选择正则化参数,str类型,可选L1和L2正则化,默认是L2正则化。
dual参数:
bool, default: False
即选择对偶公式(dual)或原始公式(primal),bool类型默认是原始公式,当样本数大于特征数时,更倾向于原始公式,即False。
tol参数:
float, default: 1e-4
对停止标准的容忍,即求解到多少的时候认为已经求得最优解,并停止。float类型,默认值为1e-4。
C参数:
float, default: 1.0
设置正则化强度的逆,值越小,正则化越强。float类型,默认值为1.0。
fit_intercept参数:
bool, default: True
即选择是否将偏差(也称截距)添加到决策函数中。bool类型,默认为True,添加。
intercept_scaling参数:
float, default 1
只在solver选择liblinear并且self.fit_intercept设置为True的时候才有用。float类型。在这种情况下x变为
x,self.intercept_scaling
class_weight参数:
dict or ‘balanced’, default: None
即类型权重参数,用于标示分类模型中各种类型的权重。可以用字典模式输入也可选择‘balanced’模式,默认是None,即所有类型的权重都一样。
可以通过直接输入{class_label: weight}来对每个类别权重进行赋值,如{0:0.3,1:0.7}就是指类型0的权重为30%,而类型1的权重为70%。
也可以通过选择‘balanced’来自动计算类型权重,实际计算公式为:
n_samples / (n_classes * np.bincount(y)),当然这是不需要我们计算的啦。
random_state参数:
int, RandomState instance or None, optional, default: None
随机数种子。仅在solver为‘sag’或者‘liblinear’时使用。int类型,默认为无。
solver参数:
{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’},
即选择逻辑回归损失函数优化算法的参数。默认情况是使用‘liblinear’算法。
对于小型数据集来说,选择‘liblinear’更好;对于大型数据集来说,‘saga’或者‘sag’会更快一些。
对于多类问题我们只能使用‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’。
对于正则化来说,‘newton-cg’,‘lbfgs’和‘sag’只能用于L2正则化(因为这些优化算法都需要损失函数的一阶或者二阶连续导数,因此无法用于没有连续导数的L1正则化);而‘liblinear’,‘saga’则可处理L1正则化。
max_iter参数:
int, default: 100
算法收敛最大迭代次数,int类型,默认为100。
只在solver为‘newton-cg’,‘sag’和‘lbfgs’是有用。
multi_class参数:
str, {‘ovr’, ‘multinomial’}, default: ‘ovr’
即选择分类方式的参数,可选参数有‘ovr’和‘multinomial’,str类型,默认为‘ovr’。
‘ovr’即one-vs-rest(OvR),而‘multinomial’即many-vs-many(MvM)。
verbose参数:
int, default: 0
日志冗长度;对于solver为‘liblinear’和‘lbfgs’将详细数字设置为任意正数以表示详细;int类型。默认为0。
warm_start参数:
bool, default: False
热启动参数;bool类型,默认为False。当设置为True时,重用上一次调用的解决方案作为初始化,否则,只需删除前面的解决方案。对于‘liblinear’没用。
n_jobs参数:
int, default: 1
并行数。int类型,默认为1,代表CPU的一个内核运行程序。
【属性(Attributes)】
与线性回归模型类似,有coef_(决策函数中的特征系数),intercept_(决策函数的偏置)和n_iter_(所有类的实际迭代次数)。最常用的就是coef_和intercept_。
【方法(Methods)】
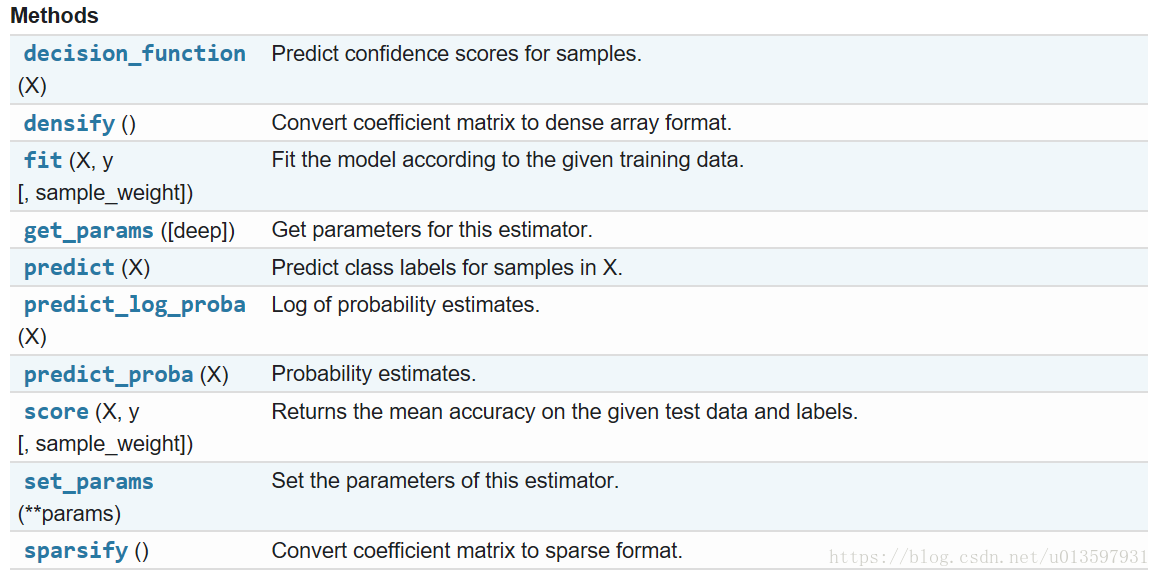
fit()、predict()、score()是经常会用到的。
fit()用于根据给定的数据拟合模型,predict()一般会传入测试样本然后得到预测值,score()用于评价模型,这里用的是平均精确度。