学习资料参考
这篇论文的地位和意义
作者使用了 ReLU 方法加快训练速度,并且使用 Dropout 来防止过拟合,通过多 GPU 的训练降低训练时间,尽管这些都不是作者自己提出的技巧,但是,作者的工作引起来大家的广泛关注,使得很多人开始利用 GPU 来训练大型的 CNN 网络。当然,作者提出的局部响应正规化也在后来被证明没啥效果(看 VGG 的论文)。但不管如何,这篇论文引起了很多人对深度学习和 GPU 训练的重视,也算是非常有影响的工作了。
这篇论文的贡献
- trained one of the largest convolutional neural networks: AlexNet
- wrote a highly-optimized GPU implementation of 2D convolution
- contains a number of new and unusual features which improve its performance and reduce its training time
- used several effective techniques for preventing overfitting:Data Augmentation(image translations 、 horizontal reflections 、altering the intensities of the RGB channels)、Dropout
网络结构

ReLU 的非线性
类似 Tanh 的激活函数,是属于饱和非线性,使用梯度下降训练这种激活函数会比非饱和非线性激活函数,如 ReLU 要慢。
函数是否是饱和函数主要看定义域和值域的范围。非饱和函数的含义是指,当自变量趋于无穷大的时候,其值也趋向无穷大。这个函数如果不是非饱和函数,那么它就是饱和函数了。例如 Tanh 函数的值域是 [-1,1],显然不符合非饱和函数的定义,因此它就是饱和函数。而 ReLU 函数则是 非饱和函数。非饱和函数的含义是指,当自变量趋于无穷大的时候,其值也趋向无穷大。这个函数如果不是非饱和函数,那么它就是饱和函数了。例如 Tanh 函数的值域是 [-1,1],显然不符合非饱和函数的定义,因此它就是饱和函数。而 ReLU 函数则是非饱和函数。

局部响应归一化 LRN(Local Response Normalization):
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是 tanh 和 sigmoid 这些传统的激活函数的值域都是有范围的,但是 ReLU 激活函数得到的值域没有一个区间,所以要对 ReLU 得到的结果进行归一化。也就是 Local Response Normalization。局部响应归一化的方法如下面的公式:
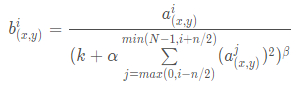
其中,a 代表的是 ReLU 在第 i 个 kernel 的 (x, y) 位置的输出,n 表示的是 a 的邻居个数,N 表示该 kernel 的总数量。b 表示的是 LRN 的结果。

每一个矩形表示的一个卷积核生成的 feature map。所有的 pixel 已经经过了ReLU激活函数,现在我们都要对具体的 pixel 进行局部的归一化。假设绿色箭头指向的是第 i 个 kernel 对应的map,其余的四个蓝色箭头是它周围的邻居 kernel 层对应的 map,假设矩形中间的绿色的 pixel 的位置为 (x, y),那么我需要提取出来进行局部归一化的数据就是周围邻居 kernel 对应的 map 的 (x, y) 位置的 pixel 的值。也就是上面式子中的 Σ 里的部分。然后把这些邻居 pixel 的值平方再加和。乘以一个系数 α 再加上一个常数 k,然后 β 次幂,就是分母。
分子就是第 i 个 kernel 对应的 map 的 (x, y) 位置的 pixel 值。
论文中参数最终确定的结果为:k = 2 , n = 5 , α = 10^(−4) , β = 0.75
- 原理讲解:https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190
- TensorFlow 实现:https://blog.csdn.net/sinat_21585785/article/details/75087768
Overlapping Pooling
论文中的 stride = 2, kernel_size = 3
其他问题
- 注意:TensorFlow 四维张量的含义:https://blog.csdn.net/qq_43797817/article/details/107009057
- 权重衰减:参考笔记:权重衰减(weight decay)