上一片文章我们学习冒泡排序、插入排序、选择排序这三种排序算法(点击文末链接查看),它们的时间复杂度都是 O(n2),比较高,适合小规模数据的排序。今天,我们学习时间复杂度为 O(nlogn) 的排序算法,归并排序和快速排序。这两种排序算法适合大规模的数据排序,比上篇文章学习的那三种排序算法要更常用。
归并排序
归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
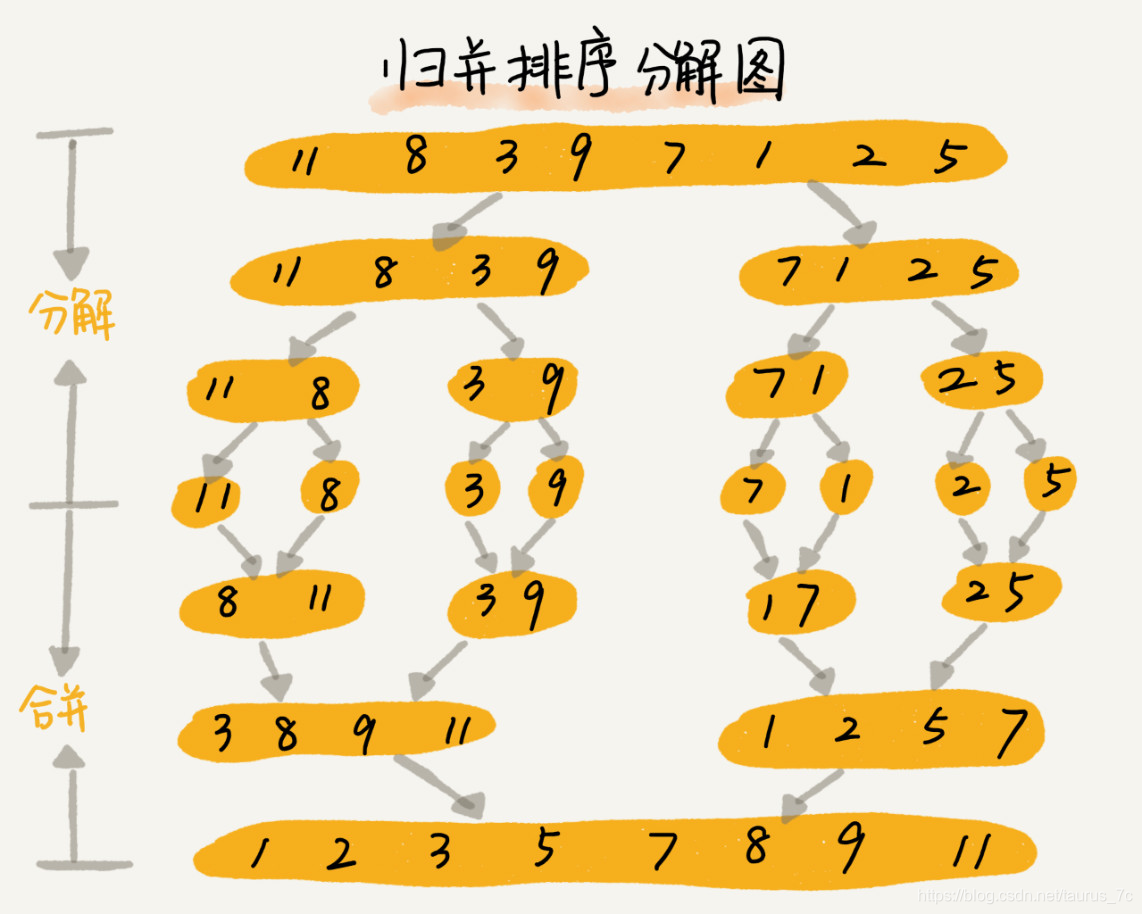
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。
这里要重点明说下写递归代码的技巧就是,分析得出递推公式,然后找到终止条件,最后将递推公式翻译成递归代码。所以,要想写出归并排序的代码,我们先写出归并排序的递推公式。
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解
刚学的朋友可能理解会有点困难,这里做个解释:
merge_sort(p…r) 表示,给下标从 p 到 r 之间的数组排序。我们将这个排序问题转化为了两个子问题,merge_sort(p…q) 和 merge_sort(q+1…r),其中下标 q 等于 p 和 r 的中间位置,也就是 (p+r)/2。当下标从 p 到 q 和从 q+1 到 r 这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从 p 到 r 之间的数据就也排好序了。
喜欢思考的朋友可能会注意到,上面的递推公式中,最外层的 merge 函数作用就是将分解后的已经有序小数组合并成一个有序数组,具体该如何做呢?
我们申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位。
继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组 tmp 中的数据拷贝到原数组 A[p…r]中。可以参考下图加深理解。
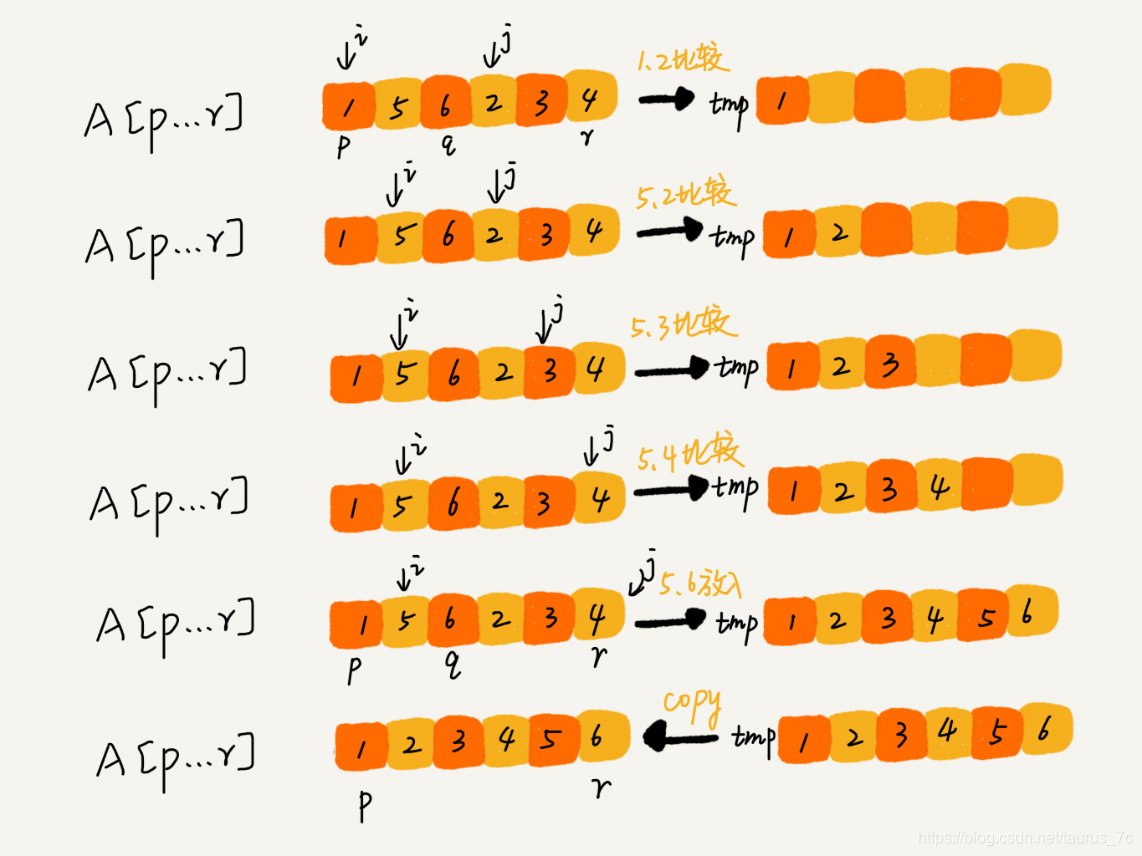
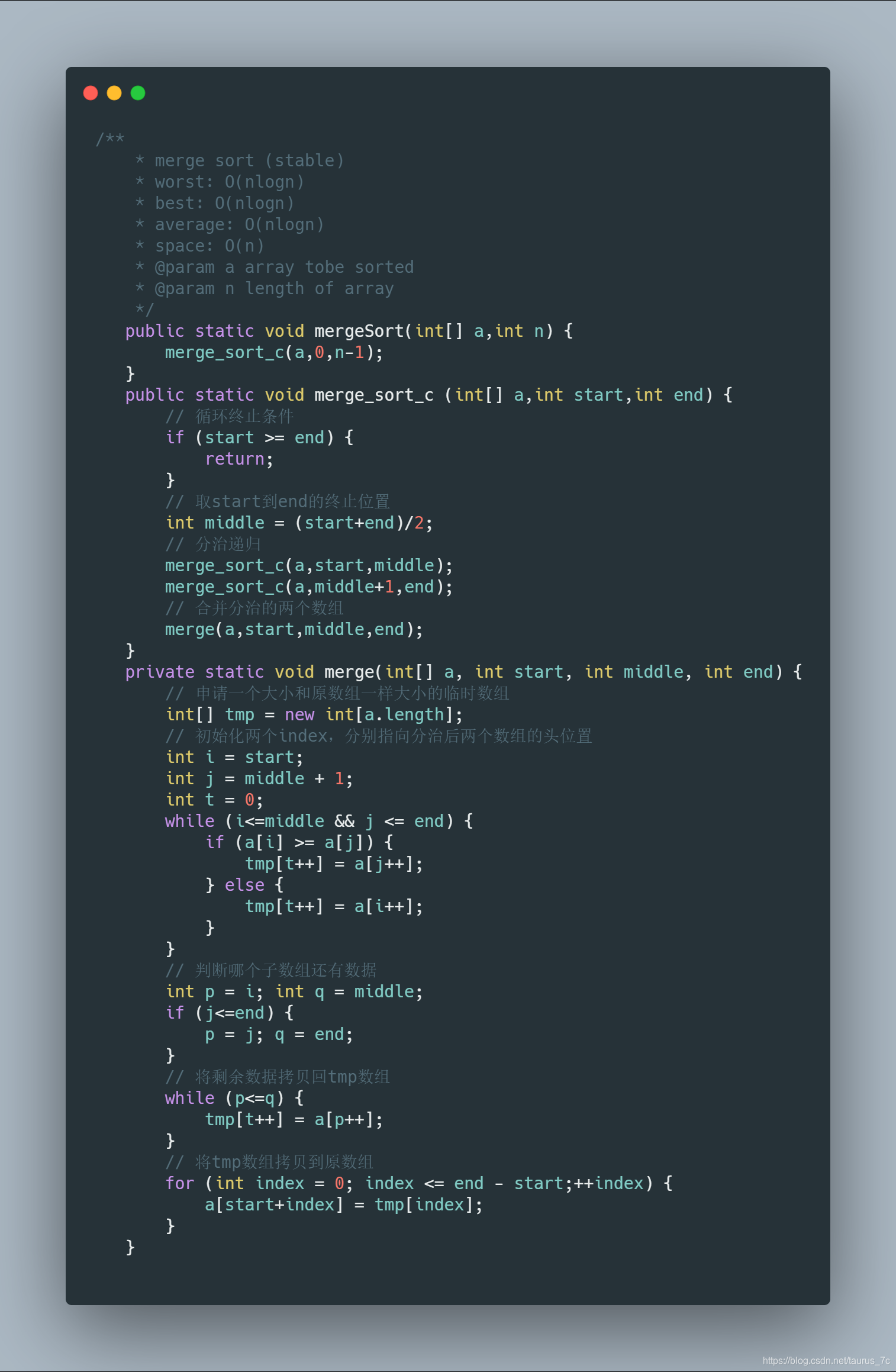
接下来就是 show code time了,你可以参考下我这里的实现:
快速排序
我们再来看快速排序算法(Quicksort),我们习惯性把它简称为“快排”。快排利用的也是分治思想。乍看起来,它有点像归并排序,但是思路其实完全不一样。
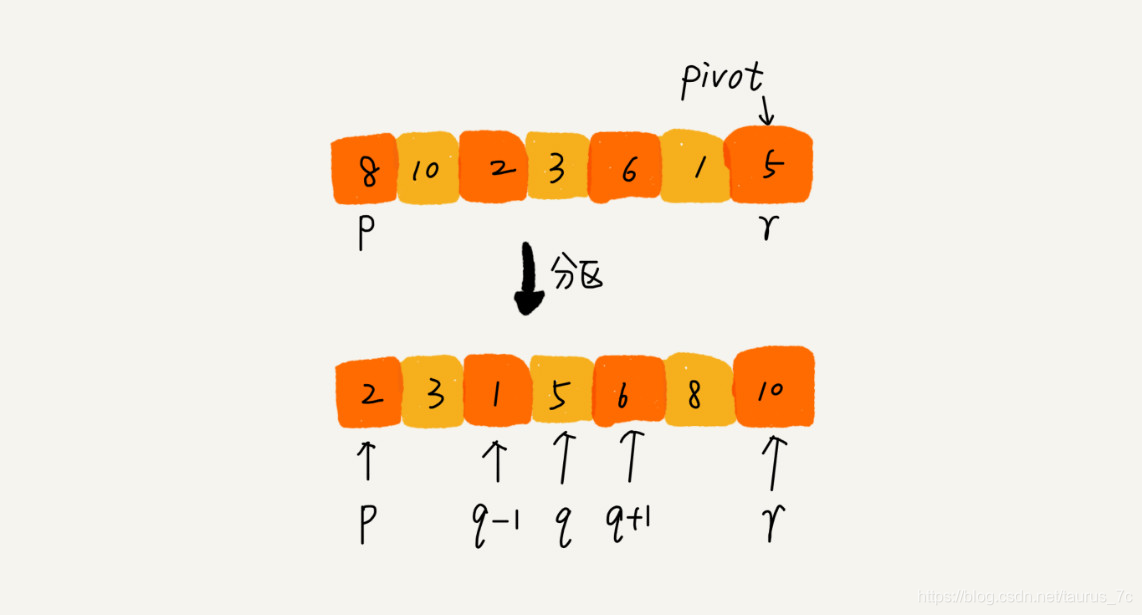
快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
递推公式:
quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)
终止条件:
p >= r
将上面的递推公式转化为递归代码如下:
// 快速排序,A是数组,n表示数组的大小
quick_sort(A, n) {
quick_sort_c(A, 0, n-1)
}
// 快速排序递归函数,p,r为下标
quick_sort_c(A, p, r) {
if p >= r then return
q = partition(A, p, r) // 获取分区点
quick_sort_c(A, p, q-1)
quick_sort_c(A, q+1, r)
}
归并排序中有一个 merge() 合并函数,我们这里需要有一个 partition() 分区函数。就是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的最后一个元素),然后对 A[p…r]分区,函数返回 pivot 的下标。
因为我们都知道快排需要实现空间复杂度为O(1),因此需要原地分区。伪代码如下:
partition(A, p, r) {
pivot := A[r]
i := p
for j := p to r-1 do {
if A[j] < pivot {
swap A[i] with A[j]
i := i+1
}
}
swap A[i] with A[r]
return i
这里的处理有点类似选择排序。我们通过游标 i 把 A[p…r-1]分成两部分。A[p…i-1]的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,A[i…r-1]是“未处理区间”。我们每次都从未处理的区间 A[i…r-1]中取一个元素 A[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 A[i]的位置。
在数组某个位置插入元素,需要搬移数据,非常耗时。这里学习一种处理技巧,就是交换,在 O(1) 的时间复杂度内完成插入操作。只需要将 A[i]与 A[j]交换,就可以在 O(1) 时间复杂度内将 A[j]放到下标为 i 的位置。
文字不如图直观,所以我画了一张图来展示分区的整个过程。
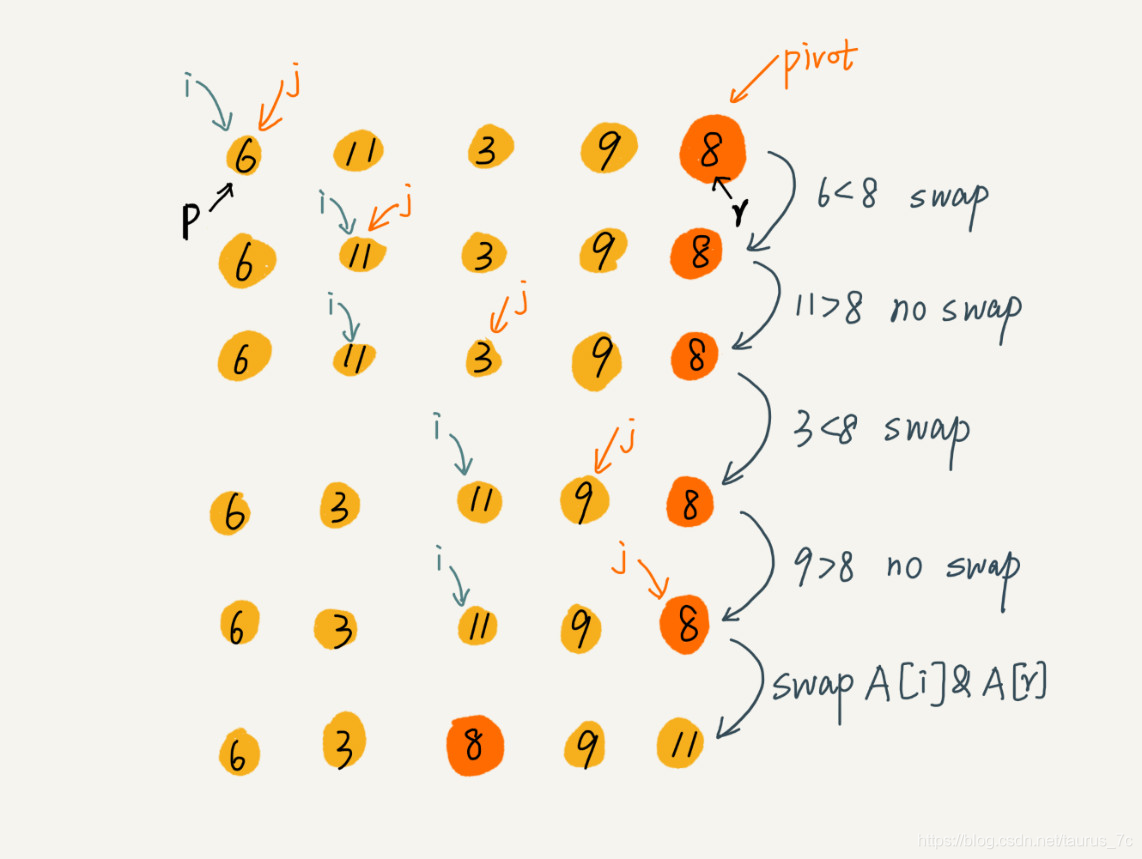
因为分区的过程涉及交换操作,如果数组中有两个相同的元素,比如序列 6,8,7,6,3,5,9,4,在经过第一次分区操作之后,两个 6 的相对先后顺序就会改变。所以,快速排序并不是一个稳定的排序算法(相同的值在排序过程中位置与原数组不同即为不稳定)。
show code, 提供给大家参考下:

对比思考
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢?
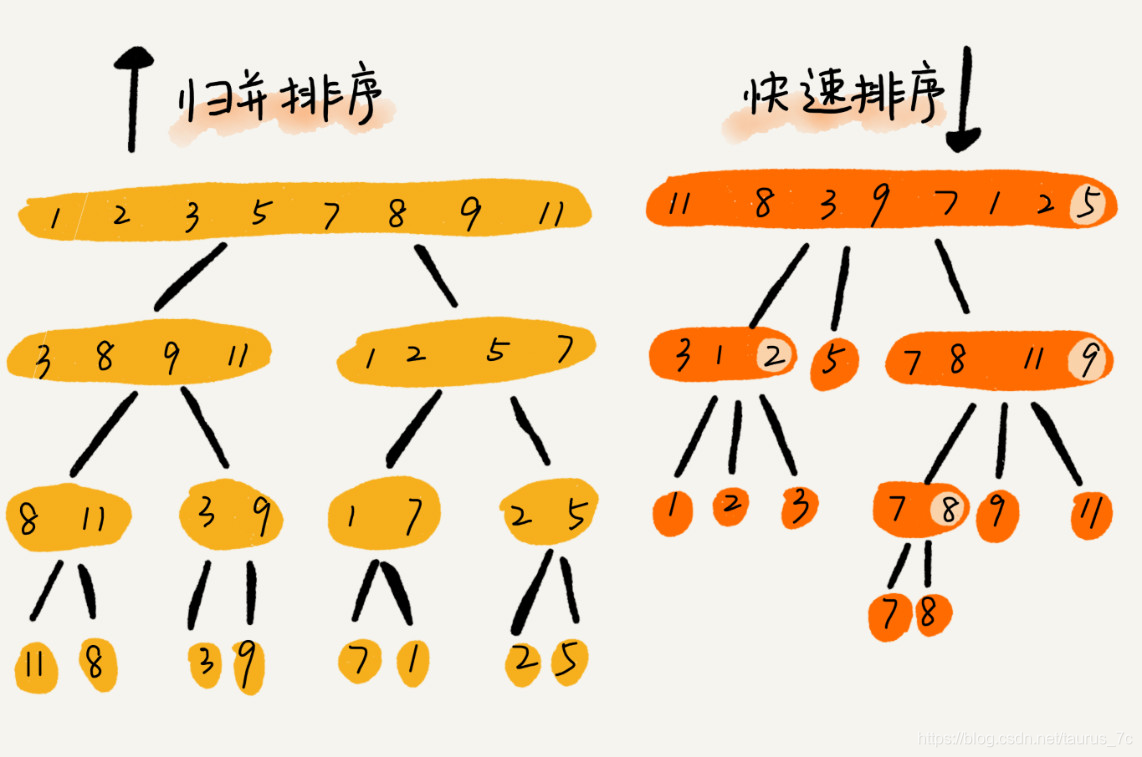
可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
扩展:常见的面试题
O(n) 时间复杂度内求无序数组中的第 K 大元素。比如,4, 2, 5, 12, 3 这样一组数据,第 3 大元素就是 4。
首先解决这个问题,毫无疑问,还是要联想到分治和分区。
我们选择数组区间 A[0…n-1]的最后一个元素 A[n-1]作为 pivot,对数组 A[0…n-1]原地分区,这样数组就分成了三部分,A[0…p-1]、A[p]、A[p+1…n-1]。
如果 p+1=K,那 A[p]就是要求解的元素;如果 K>p+1, 说明第 K 大元素出现在 A[p+1…n-1]区间,我们再按照上面的思路递归地在 A[p+1…n-1]这个区间内查找。同理,如果 K<p+1,那我们就在 A[0…p-1]区间查找。

你可能会问:为什么上述解决思路的时间复杂度是 O(n)?
第一次分区查找,我们需要对大小为 n 的数组执行分区操作,需要遍历 n 个元素。第二次分区查找,我们只需要对大小为 n/2 的数组执行分区操作,需要遍历 n/2 个元素。依次类推,分区遍历元素的个数分别为、n/2、n/4、n/8、n/16.……直到区间缩小为 1。
如果我们把每次分区遍历的元素个数加起来,就是:n+n/2+n/4+n/8+…+1。这是一个等比数列求和,最后的和等于 2n-1。所以,上述解决思路的时间复杂度就为 O(n)。
小结
归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。理解归并排序的重点是理解递推公式和 merge() 合并函数。同理,理解快排的重点也是理解递推公式,还有 partition() 分区函数。
归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。
推荐阅读
最近面试 字节、BAT,整理一份面试资料《Java 面试 BAT 通关手册》,覆盖了 Java 核心技术、JVM、Java 并发、SSM、微服务、数据库、数据结构等等。获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上