写在前面
最近每周都在参加组内的论文学习会议,每周都有组内的师兄师姐分享论文。因为我是网络安全的小白,再加上我正好有很多空闲时间,所以会将师兄师姐们分享的论文阅读一下,学习一下。这周学习的是How To Backdoor Federated Learning这篇论文。
论文介绍
联邦学习(Federated learning)是一种在保证各个参与方不需要相互交换训练要用的隐私数据的前提下,构建一个深度学习模型。例如,多个智能手机可以一起合作训练一个next-word predictor(下一个单词预测器),但是不需要知道单个用户的打字内容。联邦学习的基本原理就是整合每个参与方提交上来的参数值等。为了对训练数据进行机密保护,整合方是不会知道更新的参数值是怎么产生的。这篇论文会说明一个问题,那就是联邦学习更容易受到model-poisoning attack,而这种对于模型的攻击比只针对训练数据进行攻击更强有力,危害性也更大。一个恶意的参与方是可以通过模型替换(model replacement)来给最终的模型种入一个后门(backdoor)的,例如可以设法改变一个图像分类器,让它可以将包含某个特定特征的所有图像都被标记(label)成攻击者选定的一个恶意标签,或者让一个单词预测器可以使用攻击者选定的单词来完成某个句子。而这种攻击并不是必须要多方参与者参与才能完成(单个参与者也是可以完成攻击的)。基于标准联邦学习下的一些假设,我们对模型替换进行评估,最后发现采用模型替换比直接去影响训练数据要好很多(比如修改标签,修改训练数据等)。 联邦学习采用了一些安全的整合手段来保护每个参与者的本地模型,这样也带来了问题,那就是给我们去检测本地参与者提交的参数值的异常带来了挑战,这样整合后的模型就很容易被本地提交的异常参数值所攻击。
研究背景
最近联邦学习成为几千甚至百万参与者共同参与深度学习模型的大规模分布式训练下会使用的一个很好的结构。中央服务器会把模型一点点分配给下面的参与者。每一个参与者会在本地训练好模型,然后将更新的模型(例如参数值等)提交给中央服务器,中央服务器就会把获得的一些值更新整合到模型中。联邦学习的应用包括图像分类器, 智能手机中的next-word predictor等。但是中央服务器对参与者使用的地方训练数据以及训练过程一无所知,基于这个特点,我们会深入探索联邦学习是否真的容易受到一些model poisoning的攻击(这里我的理解是联邦学习的模型容易被参与者直接攻击)。
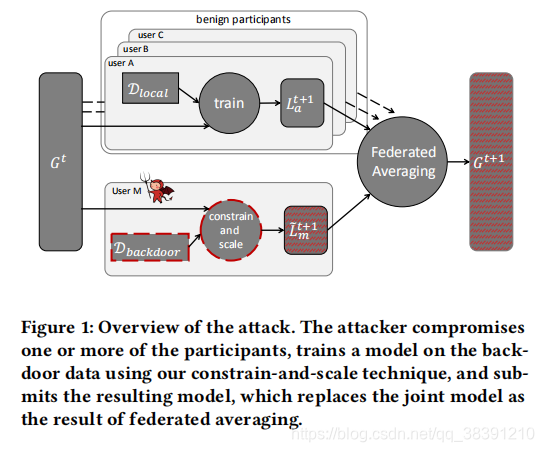 联邦学习的过程如上图所示,每一个地方参与者(user A,user B,user C)在本地训练自己的数据并且提交 L a t + 1 {L_a}^{t+1} Lat+1给中央服务器得到整合模型 G t + 1 G^{t+1} Gt+1,但是会有恶意的参与者(user M)会给地方自己的数据植入后门从而得到恶意的模型数据 L m t + 1 {L_m}^{t+1} Lmt+1,同样提交上去,影响到最后的 G t + 1 G^{t+1} Gt+1。这里参与者的恶意攻击可以包括:一个带有后门的图像分类模型可以将带有某种特定特征的图像分类成攻击者选好的类别;一个带有后门的单词预测器可以将特定的句子中的某个单词预测成攻击者选好的单词。参与者可以做的事情包括:任意的修改地方模型的参数;将对潜在攻击行为的规避加入到训练本地模型用的loss值中(这里我的理解是,因为训练的时候loss值是越来越小,加入这个值,就相当于让规避攻击风险的能力不断降低,所以模型就更容易被攻击了)。
联邦学习的过程如上图所示,每一个地方参与者(user A,user B,user C)在本地训练自己的数据并且提交 L a t + 1 {L_a}^{t+1} Lat+1给中央服务器得到整合模型 G t + 1 G^{t+1} Gt+1,但是会有恶意的参与者(user M)会给地方自己的数据植入后门从而得到恶意的模型数据 L m t + 1 {L_m}^{t+1} Lmt+1,同样提交上去,影响到最后的 G t + 1 G^{t+1} Gt+1。这里参与者的恶意攻击可以包括:一个带有后门的图像分类模型可以将带有某种特定特征的图像分类成攻击者选好的类别;一个带有后门的单词预测器可以将特定的句子中的某个单词预测成攻击者选好的单词。参与者可以做的事情包括:任意的修改地方模型的参数;将对潜在攻击行为的规避加入到训练本地模型用的loss值中(这里我的理解是,因为训练的时候loss值是越来越小,加入这个值,就相当于让规避攻击风险的能力不断降低,所以模型就更容易被攻击了)。
这篇论文在两个数据集上对这种攻击进行实践: CIFAR-10数据集(用于实践对图像分类模型的攻击),Reddit corpus(用于实践对单词预测器的攻击)。在一个由8000个参与者共同维护训练的单词预测器中,就算是只拿出来8个参与者进行本论文中的后门攻击,也会达到50%的攻击成功率,而data-poisoning攻击(也就是前面说的单纯只对于训练数据进行攻击破坏)在取得同样的50%的成功率的前提下需要有400个恶意参与者。
研究实现
攻击者需要使用植入了后门的输入数据来训练自己的模型,但是要注意的是每一个training batch都需要既有正确标注的数据,也要有植入了后门的数据,来帮助模型区分二者的区别。攻击者也可以改变本地的learning rate以及epoch的数目来将被植入后门的数据过拟合。 最近发现这里模型采用的loss function(损失函数)必须要满足 Lipschitz约束 才可以。这个Naive Approach是:中央服务器的整合会去除掉大部分被植入后门的本地模型,并且整合的模型会很快忘记后门。需要一直指定攻击参与者,虽然这样模型的替换过程会很慢,但是这篇论文中还是采用了朴素的方法(Naive Approach)。
 算法步骤如上图所示。
算法步骤如上图所示。
攻击者可以进行如下的提交:
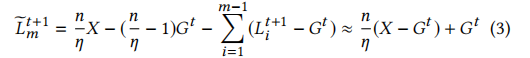 如上式所示,攻击者可以通过改变γ = 增大被植入了后门的模型X的权重,从而保证在中央服务器整合所有的本地模型参数值时,后门依旧存在,整合模型也才可以正确的被X替换。
如上式所示,攻击者可以通过改变γ = 增大被植入了后门的模型X的权重,从而保证在中央服务器整合所有的本地模型参数值时,后门依旧存在,整合模型也才可以正确的被X替换。