论文学习之综述:《Deep learning》
文章目录
前言:
将第一年安排书写到这,应用方面继续将婴儿监护系统做下去,开发OnePasswd软件解决密码多记不住的问题。论文方面跟学综述Deep learning、Alexnet、VGG、ResNet、Googlenet、YOLO、SSD等,复现完dl论文后尝试花一个月的时间用Guilite(我主要完成图形加速)发计算机工程核心期刊,试一试难度。
第一部分:深度学习基础(1-4)页
作者介绍:
Geoffrey Hinton:误差反向传播的创始人,并提出了玻尔兹曼机,2012年在imageNet比赛上使用改进版本卷积神经网络引起巨大轰动。

Yann LeCun:首先发明CNN并制作了minisit数据集

Yoshua Bengio:自然语言创始人,花书作者之一。

前期知识储备:
线性代数,概率论,梯度优化,约束优化、机器学习基础等知识(PS:其实我也会的不多,知道梯度是变化率最大的方向。。。)。
背景介绍部分:(第一页supervised learning之前的内容)
下图是这篇论文介绍的深度学习应用领域,另外论文中表示,相比较传统方法如专家系统,深度学习不通过人为经验来设置特征提取器,主要是采用多层网络机制来进行学习,通过层层参数调整会逐步放大和结果有关的变化,和结果无关的特征会在训练中会慢慢缩小。
 图1:机器学习的应用领域和学习
图1:机器学习的应用领域和学习
监督学习:(upervised learning标题下的内容)
监督学习介绍:
监督学习是指对有lab的数据进行学习,人和动物在学习过程中还有无监督学习,比如我们人在学习许多技能时候会发现哪些技能是有相同作用的。在深度学习领域发展较好的还是监督学习,无监督学习作为未来的突破点有很大的研究价值。
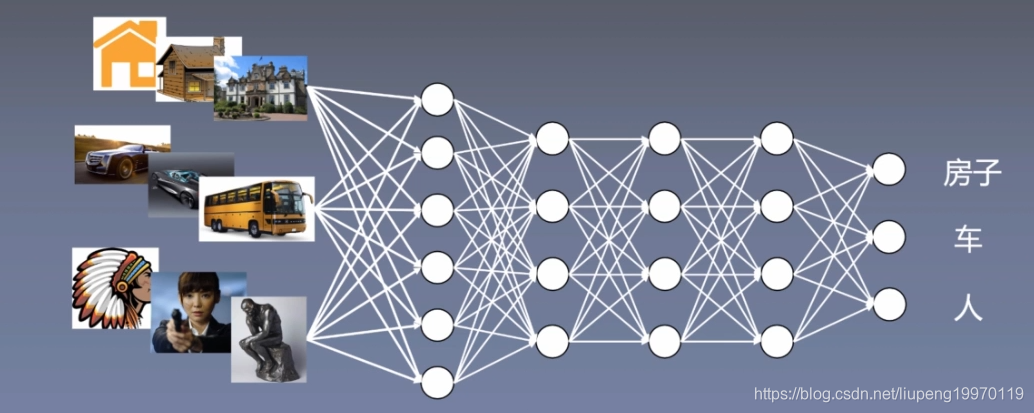 图2:监督学习介绍
图2:监督学习介绍
监督学习训练步骤:
1. 收集三类别的图片,打标签
2. 训练过程中对输入图片输出一个得分向量
3. 设计好期望输出与实际输出向量的差距计算函数(目标函数)
4. 通过SGD或者BP算法更新每层神经元的W,达到目标函数最小。
学习过程中做什么?:
从论文的图1-a中可以看出如果你想输出数据属于哪条线,那么学习的过程中会捕捉到你这个特征,将两条线段的数据尽可能分开,便于区分。
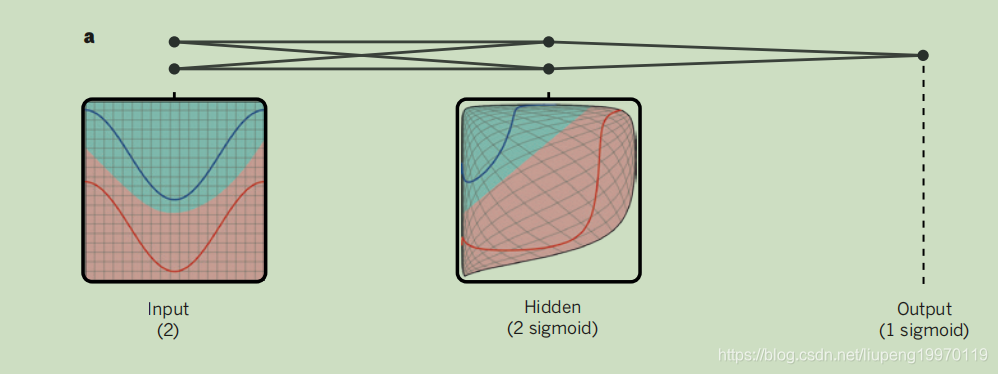
图3:隐藏层的工作
激活函数:
为什么深度学习要用非线性激活函数呢?生活中很多问题都是非线性,如果每层网络只用y=2x,y=0.5x这种线性的函数,那么我们得到的叠加结果还是一个线性的函数,它无法解决需要曲线来进行分类的问题。在深度学习中使用了很多经典的激活函数,常用的激活函数有如下几个:
 图4:激活函数
图4:激活函数
随机梯度下降法:
这个方法也是最常用的方法之一,改良的算法虽然性能好一些,但是由于要求二阶导会导致运算量过大。我分享一下纯手动的梯度下降代码(随机是指随机取数据进行梯度计算):
def _numerical_gradient_no_batch(f, x):#F是损失函数,x是w与b,它们作为变量进行变换
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
def numerical_gradient(f, X):
if X.ndim == 1:
return _numerical_gradient_no_batch(f, X)
else:
grad = np.zeros_like(X)
for idx, x in enumerate(X):
grad[idx] = _numerical_gradient_no_batch(f, x)
return grad#这里可以返回grad的数组
def SGD()#只截取了一段代码,整个代码太长了,我没贴上来,核心就是更新参数。
for i in 10000:
grad = numerical_gradient(x_batch, t_batch)
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
反向传播:
反向传播在求gradient上不会像梯度下降法那样,循环求x+h与f(x+h),BP算法通过一次前向传播之后可以得到各个层的值,将这些值保存下来可以进行梯度计算。反向传播的时候会使用sigmoid_grad等(已经推导好的链式法函数)*后面传来的链式变化数值去计算每一层的W,B,这样算起来更为快捷和高效(因为层化,并且前向传播值可以直接用来反向传播)。
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
补充内容:
这篇论文是15年发布的,作者想告诉大家一些深度学习的误解,刚开始一些人认为深度学习这种不需要预先训练的方法是不可靠的,但是随着硬件性能提升如GPU、大数据时代的来临,经过海量数据训练得到结果具有很好的泛化能力。其次人们认为梯度下降法会陷入局部最优解,这样会导致无法求出全局最优解。作者给出了实验结果表示:在选择较为平滑的激活函数之后,得出来的局部最优解很大可能是全局最优解,即使不是也相差不远,其实真正的问题是如何解决梯度消失导致没法继续走下去。
第二部分:CNN学习(4-6)页
为什么要发明CNN:
全连接网络对于非关联的输入x可以很好训练出参数w,但图像这种局部有关联的输入数据将其展开成向量形式进行全链接处理会忽略图像局部关联,什么事局部关联呢?局部关联是指图形的一块小区域在像素级别上有一定的相关性,如果能将这种小区域内的关联性在神经网络中体现出来,那么得到的精度肯定要比之前要好的多。针对这一个需求,三位作者中第二个作者发明了cnn,提出了通过卷积层和池化层来提取输入图片的特征,训练出合适的参数。我们知道一层的卷积核实际上就是对图像进行像素边缘化处理,这样卷积后的图像放在下一层的输入中再次卷积,会提取出一些更为抽象的数据特征,并且多维度不同的卷积核提取出来的局部特征是不一样的。
CNN的基础:
卷积核:
下图就是卷积核在卷积的过程,在这过程中有步长padding和卷积核大小这两个概念,一般卷积核大小是3*3的,在卷积核内部数值设定时候是有一定的技巧和经验的,不同的数据设置会反映出图像的不同特征。常用的卷积核不多。
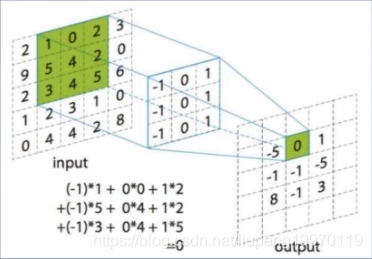
图5:卷积核
池化层:
将语义相近的特征进行融合,求平均或者是求最大。
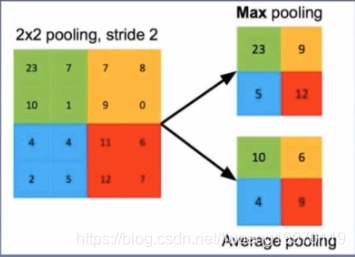
图6:池化层
CNN样例:
下图是CNN模型图示,首先一只狗有三个通道,将其降维度到二维,通过第一层卷积提取边缘,进行激活函数后再进行池化层衰减上一层微弱变化的影响。后面的卷积会逐步识别图像的纹理,组件,最终到物体。
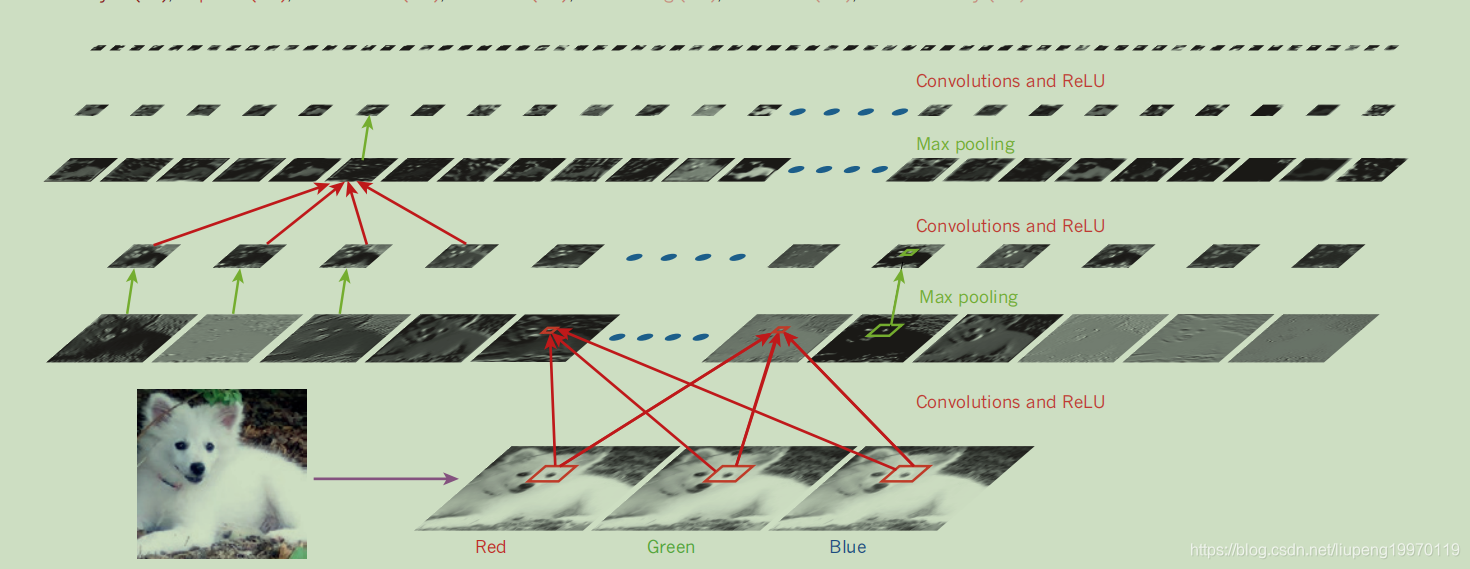
图7:CNN工作流程
常用的CNN:
AlexNet
LetNet
VGG
GoogelNet
ResNet
DenseNet
FaceNet
补充:
GPU,Relu,Dropout是CNN成功的驱动。
第三部分:循环神经网络RNN原理、论文中对未来的展望(7-9)页
RNN简单的理解:
RNN是循环序列网络,在自然语言处理中,一句话相邻的单词和字之间是有相关性的,RNN能捕捉这种相关性,通过输入一个“我” 可以预测句子中下一个字,如预测”是“概率30%,”可以“概率20%。同时在处理语言时候要结合上下文,所以设计一个机制来捕捉上下文语义,用来更准确的预测文本。
未来的展望:
无监督学习:可能是下一个研究的突破点,主要分为聚类和关联问题。聚类问题是在数据中发现内在的分组,关联问题是发现看似无关的数据之间的联系。在人类和动物学习中无监督学习还是占据主导作用,感觉如果能很好的实现无监督学习,那么离强人工智能也不会太远。
强化学习:通过奖励机制来加强我们想要实现的结果。
GAN: 还不懂。。
