文章目录
| 主要内容 | 用途 |
|---|---|
| 交叉验证 | 一种更可靠的评估泛化性能的方法 |
| 网格搜索 | 一种调节监督模型参数以获得最佳泛化性能的有效方法 |
| 其他评估分类和回归性能的方法 | 在默认度量(score方法给出的精度和 R2 )之外的方法 |
一、交叉验证(主要用到sklearn.model_selection)
交叉验证(cross-validation)是一种评估泛化性能的统计学方法。
1.1 k 折交叉验证
最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。在执行 5 折交叉验证时,首先将数据划分为(大致)相等的 5 部分,每一部分叫作折(fold)。

from sklearn.model_selection import cross_val_score # 导入交叉验证函数
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
iris = load_iris()
logreg =LogisticRegression()
scores = cross_val_score(logreg, iris.data, iris.target, cv=3) # 参数 cv 表示折数
scores.mean() # 总结交叉验证精度的一种常用方法是计算平均值- 优点
使用交叉验证,每个样例都会刚好在测试集中出现一次:每个样例位于一个折中,而每个折都在测试集中出现一次。这样可以告诉我们将模型应用于新数据时在最坏情况和最好情况下的可能表现。我们对数据的使用更加高效。
- 缺点
增加计算成本。现在我们要训练 k 个模型而不是单个模型,所以交叉验证的速度要比数据的单次划分大约慢 k 倍。
1.2 分层k折交叉验证
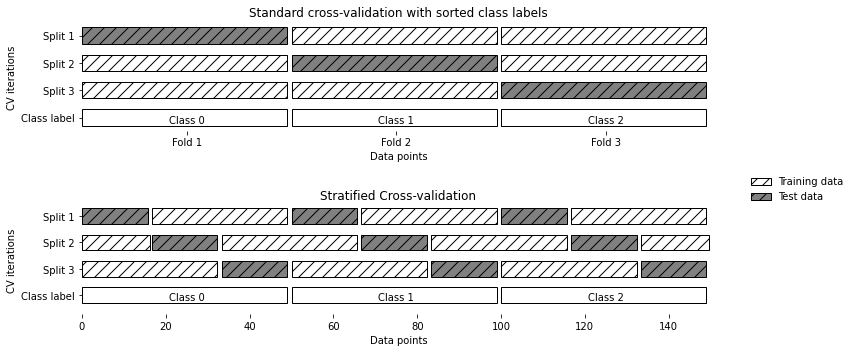
引入交叉验证分离器(cross-validation splitter)
从 model_selection 模块中导入 KFold 分离器类,并用我们想要使用的折数来将其实例化。
from sklearn.model_selection import KFold
kfold = KFold(n_splits=3) # 不分层k折交叉验证
cross_val_score(logreg, iris.data, iris.target, cv=kfold) 解决类别标签排序问题的另一种方法是将数据打乱来代替分层,以打乱样本按标签的排序。
kfold = KFold(n_splits=3, shuffle=True, random_state=0) # 参数 shuffle 代表是否打乱数据1.3 其他策略
- 留一法交叉验证
另一种常用的交叉验证方法是留一法(leave-one-out),看作是每折只包含单个样本的 k 折交叉验证。这种方法可能非常耗时,特别是对于大型数据集来说,但在小型数据集上有时可以给出更好的估计结果。
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
scores = cross_val_score(logreg, iris.data, iris.target, cv=loo)- 打乱划分交叉验证
另一种非常灵活的交叉验证策略是打乱划分交叉验证(shufflfle-split cross-validation)。
在打乱划分交叉验证中,每次划分为训练集取样 train_size 个点,为测试集取样 test_size 个(不相交的)点。将这一划分方法重复n_iter 次。

from sklearn.model_selection import ShuffleSplit
shuffle_split = ShuffleSplit(test_size=.5, train_size=.25, n_splits=10)
scores = cross_val_score(logreg, iris.data, iris.target, cv=shuffle_split)ShuffleSplit 还有一种分层的形式,其名称为 StratifiedShuffleSplit,它可以为分类任务提供更可靠的结果。
- 分组交叉验证
另一种非常常见的交叉验证适用于数据中的分组高度相关时。为了实现这一点,我们可以使用 GroupKFold,它以 groups 数组作为参数,可以用来说明照片中对应的是哪个人或者语音属于哪个人。

from sklearn.datasets import make_blobs
from sklearn.model_selection import GroupKFold
X, y = make_blobs(n_samples=12, random_state=0)
groups = [0, 0, 0, 1, 1, 1, 1, 2, 2, 3, 3, 3]
scores = cross_val_score(logreg, X, y, groups, cv=GroupKFold(n_splits=3))更多应用: http://scikit-learn.org/stable/modules/cross_validation.html
二、网格搜索
找到一个模型的重要参数(提供最佳泛化性能的参数),最常用的方法就是网格搜索(grid search),它主要是指尝试我们关心的参数的所有可能组合。
2.1 简单网格搜索: 遍历法
2.2 引入验证集
当尝试了许多不同的参数,并选择了在测试集上精度最高的那个,但这个精度不一定能推广到新数据上。因此,对数据进行 3 折划分,分为训练集、验证集和测试集。

X_trainval, X_test, y_trainval, y_test = train_test_split(iris.data, iris.target, random_state=0)
X_train, X_valid, y_train, y_valid = train_test_split(X_trainval, y_trainval, random_state=1)-
任何根据测试集精度所做的选择都会将测试集的信息“泄漏”(leak)到模型中。因此,保留一个单独的测试集是很重要的,它仅用于最终评估。
-
好的做法是利用训练集和验证集的组合完成所有的探索性分析与模型选择,并保留测试集用于最终评估——即使对于探索性可视化也是如此。
-
严格来说,在测试集上对不止一个模型进行评估并选择更好的那个,将会导致对模型精度过于乐观的估计。
2.3 带交叉验证的网格搜索
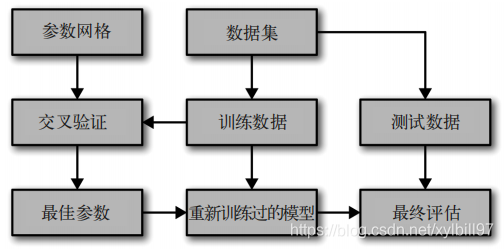
- 通俗地讲:
首先遍历参数列表+交叉验证计算精度确定最优参数,用最优参数重新训练模型,用模型+测试集进行最终评估。
- 具体步骤如下:
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {
'C': [0.001, 0.01, 0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
grid_search = GridSearchCV(SVC(), param_grid, cv=5)X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
grid_search.fit(X_train, y_train)
grid_search.score(X_test, y_test)grid_search.best_params_ # 最优参数
grid_search.best_score_ # 保存的是交叉验证的平均精度,是在训练集上进行交叉验证得到的
grid_search.best_estimator_ # 访问最佳参数对应的模型,它是在整个训练集上训练得到的
results = pd.DataFrame(grid_search.cv_results_) # 网格搜索的结果,将字典转换成 pandas 数据框后再查看使用 score 方法(或者对 predict 方法的输出进行评估)采用的是在整个训练集上训练的模型。而 best_score_ 属性保存的是交叉验证的平均精度,是在训练集上进行交叉验证得到的。
2.4 其他情况
- 在非网格的空间中搜索
GridSearchCV 的 param_grid 可以是字典组成的列表(a list of dictionaries)。列表中的每个字典可扩展为一个独立的网格。
param_grid =
[{
'kernel': ['rbf'],'C': [0.001, 0.01, 0.1, 1, 10, 100],'gamma': [0.001, 0.01, 0.1, 1, 10, 100]},
{
'kernel': ['linear'],'C': [0.001, 0.01, 0.1, 1, 10, 100]}]- 使用不同的交叉验证策略进行网格搜索
将数据单次划分为训练集和测试集,这可能会导致结果不稳定,过于依赖数据的此次划分。
嵌套交叉验证(nested cross-validation):不是只将原始数据一次划分为训练集和测试集,而是使用交叉验证进行多次划分。
scores = cross_val_score(GridSearchCV(SVC(), param_grid, cv=5), iris.data, iris.target, cv=5)- 交叉验证与网格搜索并行
这使得网格搜索与交叉验证成为多个 CPU 内核或集群上并行化的理想选择。
注意:scikit-learn 不允许并行操作的嵌套。
三、评估指标与评分(主要用到sklearn.metrics)
在选择机器学习指标之前,你应该考虑应用的高级目标,这通常被称为商业指标(business metric)。对于一个机器学习应用,选择特定算法的结果被称为商业影响(business impact)。
3.1 二分类指标(本节重点)
二分类可能是实践中最常见的机器学习应用,也是概念最简单的应用。
对于二分类问题,我们通常会说正类(positive class)和反类(negative class),而正类是我们要寻找的类。
- 错误类型
错误的阳性预测叫作假正例(false positive),在统计学中,假正例也叫作第一类错误(type I error);
错误的阴性预测叫作假反例(false negative),假反例也叫作第二类错误(type II error)。
我们希望尽量避免假反例!
- 不平衡数据集
一个类别比另一个类别出现次数多很多的数据集,通常叫作不平衡数据集(imbalanced dataset)或者具有不平衡类别的数据集(dataset with imbalanced classes)。
- 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion = confusion_matrix(y_test, pred_logreg)
| 对应上图 | |
|---|---|
| 真反例(true negative),TN | 假正例(false positive),FP |
| 和假反例(false negative),FN | 真正例(true positive),TP |
- 指标计算公式
- 精度是正确预测的数量(TP 和 TN)除以所有样本的数量(混淆矩阵中所有元素的总和):
Accuracy = T P + T N T P + T N + F P + F N \text { Accuracy }=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{TN}+\mathrm{FP}+\mathrm{FN}} Accuracy =TP+TN+FP+FNTP+TN
- 准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例:
Precision = T P T P + F P \text { Precision }=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}} Precision =TP+FPTP
如果目标是限制假正例的数量,那么可以使用准确率作为性能指标。准确率也被称为阳性预测值(positive predictive value,PPV)。
- 召回率(recall)度量的是正类样本中有多少被预测为正类:
Recall = T P T P + F N \text { Recall }=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}} Recall =TP+FNTP
召回率的其他名称有灵敏度(sensitivity)、命中率(hit rate)和真正例率(true positive rate,TPR)。
- 将两种度量进行汇总的一种方法是 f-分数(f-score)或 f-度量(f-measure),它是准确率与召回率的调和平均:
F = 2 ⋅ precision ⋅ recall precision + recall \mathrm{F}=2 \cdot \frac{\text { precision } \cdot \text { recall }}{\text { precision }+\text { recall }} F=2⋅ precision + recall precision ⋅ recall
对准确率、召回率和 f1- 分数做一个更全面的总结,可以使用 classification_report 这个很方便的函数,它可以同时计算这三个值,并以美观的格式打印出来:
from sklearn.metrics import classification_report- 考虑不确定性
大多数分类器都提供了一个 decision_function 或 predict_proba 方法来评估预测的不确定度。
在二分类问题中,我们使用 0 作为 decision_function 的阈值,0.5 作为 predict_proba 的阈值。
- 准确率-召回率曲线
改变模型中用于做出分类决策的阈值,是一种调节给定分类器的准确率和召回率之间折中的方法。
为了更好地理解建模问题,很有启发性的做法是,同时查看所有可能的阈值或准确率和召回率的所有可能折中。利用一种叫作准确率 - 召回率曲线(precision-recall curve)。
对分类器设置要求(比如 90% 的召回率)通常被称为设置工作点(operating point)。在业务中固定工作点通常有助于为客户或组织内的其他小组提供性能保证。
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(y_test, svc.decision_function(X_test))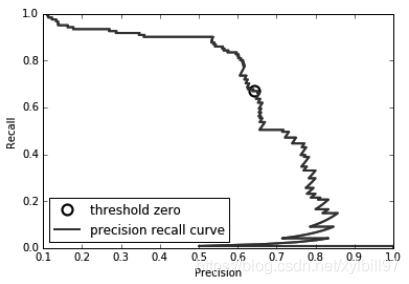
总结准确率 - 召回率曲线的一种方法是计算该曲线下的积分或面积,也叫作平均准确率(average precision),可以使用 average_precision_score 函数来计算平均准确率。
- 受试者工作特征(ROC)与AUC
3.2 多分类指标
3.3 回归指标
对于我们见过的大多数应用来说,使用默认 R2 就足够了,它由所有回归器的 score 方法给出。业务决策有时是根据均方误差或平均绝对误差做出的,这可能会鼓励人们使用这些指标来调节模型。
3.4 在模型选择中使用评估指标
scikit-learn 提供了一种非常简单的实现方法,就是 scoring 参数,它可以同时用于 GridSearchCV 和cross_val_score。你只需提供一个字符串,用于描述想要使用的评估指标。
对于分类问题,scoring 参数最重要的取值包括:
| 参数 | 解释 |
|---|---|
| accuracy | 默认值 |
| roc_auc | ROC 曲线下方的面积 |
| average_precision | 准确率 - 召回率曲线下方的面积 |
| f1、f1_macro、f1_micro 和 f1_weighted | 二分类的 f1- 分数以及各种加权变体 |
对于回归问题,最常用的取值包括:
| 参数 | 解释 |
|---|---|
| r2 | R2 分数 |
| mean_squared_error | 均方误差 |
| mean_absolute_error | 平均绝对误差 |
可以查看 metrics.scorer 模块中定义的 SCORER 字典
from sklearn.metrics.scorer import SCORERS
sorted(SCORERS.keys())四、总结
- 关于交叉验证和网格搜索
-
我们需要将数据集划分为训练数据、验证数据与测试数据,其中训练数据用于模型构建,验证数据用于选择模型与参数,测试数据用于模型评估。
-
最常用的形式(如前所述)是训练 / 测试划分用于评估,然后对训练集使用交叉验证来选择模型与参数。
- 关于评估指标
- 机器学习任务的最终目标很少是构建一个高精度的模型。一定要确保你用于模型评估与选择的指标能够很好地替代模型的实际用途。
- 在实际当中,分类问题很少会遇到平衡的类别,假正例和假反例也通常具有非常不同的后果。你一定要了解这些后果,并选择相应的评估指标。