归并算法基于归并这个操作,即将两个有序的数组归并成一个更大的有序数组,人们根据归并操作发明了归并算法,将待排序元素的序列分成两部分分别排序(递归地),再将结果归并起来。
基本思想
1、将待排序的序列 分成大小为2/n的两部分
2、对两部分使用归并排序(递归地)
3、将排好序的两部分合并起来
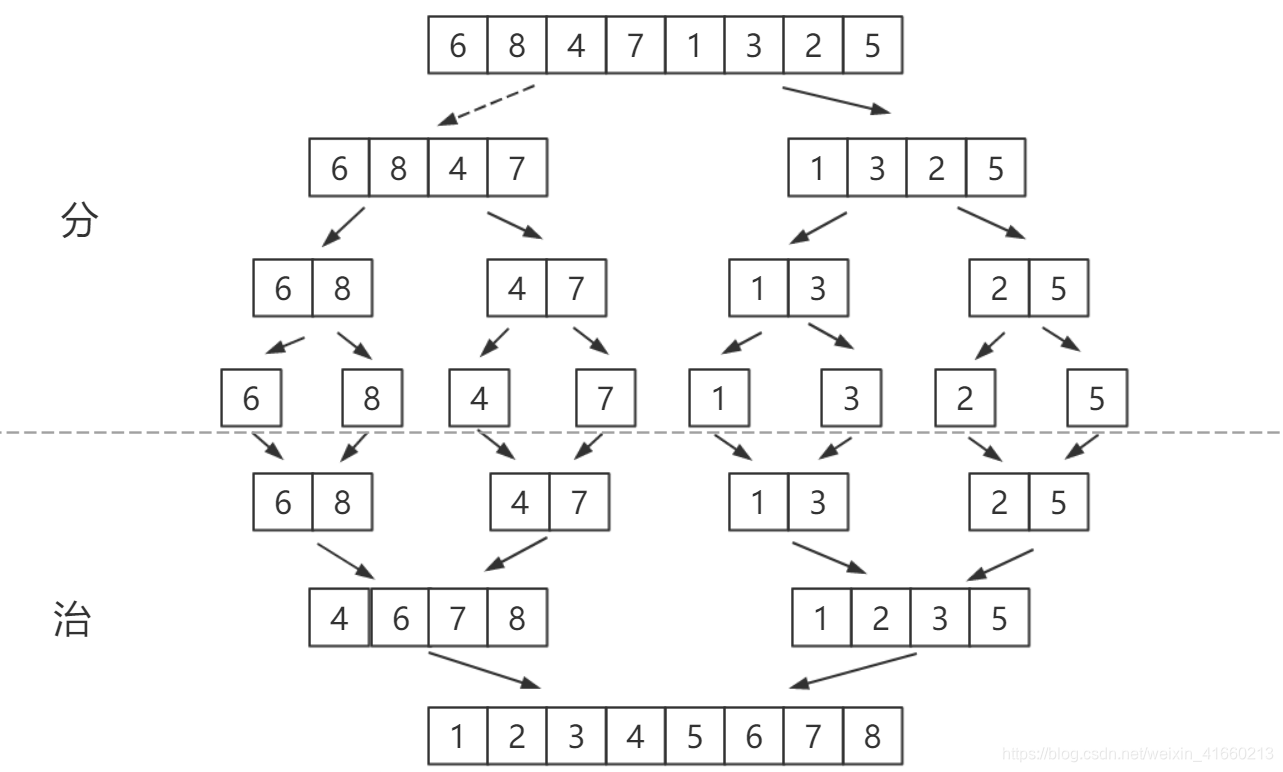
这张图体现了分而治之的思想,从图中我们可以看到,在“分”的阶段,原始数组被不断分成越来越小的子数组,直到子数组大小为1,在“治”的阶段,将小数组递归地排序并将结果修补在一起得到最终数组。
基本操作归并的详细过程如下:
以上图中归并的的最后一步为例,两个输入数组A、B(已排序),一个输出数组C,以及三个指针 i、j、k,它们初始都指向数组的第一位

首先是 4 和 1 进行比较,1较小,被放入输出数组,同时 j 后移一位

然后是 4 和 2 进行比较,2较小,被放入输出数组,同时 j 后移一位

继续比较,直到6 和 5 比较,将 5 放进输入数组后,这时候子数组B已经用完了,
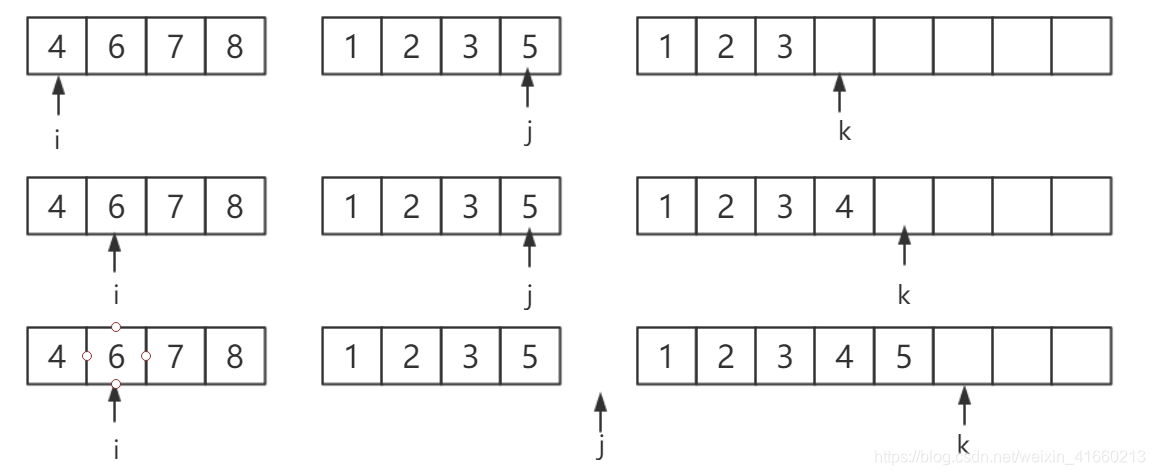
接下来只需要直接将A剩余的部分放入到C中,就完成合并了

合并两个已排序的表所用的时间是线性的,因为最多进行 n-1 次比较:每次比较都将一个元素放进数组 C 中,最后一次则会添加两个元素。
上个动态图直观感受一下整个过程
代码实现
import java.util.Random;
public class MergeSort {
private static int[] tempArr; //声明一个待使用的临时数组
public static void main(String[] args) {
Random ra = new Random();
int a [] = new int[15];
for(int i=0;i<15;i++) { //15个随机元素的数组
a[i] = ra.nextInt(15)-5;
}
sort(a); //调用sort方法来驱动mergeSort()
for(int num:a) {
System.out.print(num);
}
}
private static void sort(int a[]) {
tempArr = new int[a.length]; //给临时数组创建空间
mergeSort(a,0,a.length-1);
}
private static void mergeSort(int a[],int left,int right) {
if(left < right) {
int mid = (left + right) / 2;
mergeSort(a,left,mid); //递归地对左边的元素排序
mergeSort(a,mid+1,right); //递归地对右边的元素排序
merge(a,left,mid,right); //将两边已排序元素合并
}
}
private static void merge(int a[],int left,int mid,int right) {
int i = left;
int j = mid+1;
int k = 0;
while(i<=mid && j<=right) //当两个子数组中都还有元素
if(a[i]<a[j]) tempArr[k++] = a[i++];
else tempArr[k++] = a[j++];
while(i<=mid) //将左边的剩余元素填入
tempArr[k++] = a[i++];
while(j<=right) //将右边剩余元素填入
tempArr[k++] = a[j++];
for(int l=left;l<=right;l++) { //将元素拷贝回原数组
a[l] = tempArr[l];
}
}
}
可以看到,归并所用的 merge 方法中的 tempArray 并不是在 merge 方法中创建的,而是在 sort 中创建,作为参数传入 merge 中的,为什么呢?
因为这样可以避免每次合并的时候(特别是很小的数组的合并),都需要创建一个新数组,这样会影响归并排序的速度
时间复杂度
对归并排序进行分析也就是对一个递归的算法进行分析,我们可以写出递推关系并求解,这里就不写枯燥的数学公式了,毕竟我们理工科讲究实用主义,总之归并排序的时间复杂度为O(N logN)
与希尔排序的比较
在实际应用中,归并排序和希尔排序的差距常常在常数级别之内,并且在理论上,还没有人能证明希尔排序对于随机数据的运行时间是线性对数级别的,因此在平均情况下它的性能会有比归并排序更低的可能性。
归并排序的改进
有时间再补上好了
总结分析
1、虽然归并排序的运行时间为O(N logN),但是它需要用到的额外的内存与 N 有关,而且在算法中还要花费将整个数组拷贝到临时数组再放回来的时间,这大大拖慢了它的速度。
2、归并排序的运行时间严重依赖于比较元素和在数组中移动元素的开销,而这些开销是跟具体语言有关的。例如在Java中,执行一次泛型排序时,进行元素的比较是昂贵的,进行元素的移动则是省时的,正巧归并排序所用的比较次数在流行的排序算法里是最少的,因此Java类库中的泛型排序使用的算法就是归并排序改进而得到的。
此外,在Java中,快速排序用作基本类型的标准库排序,这里,比较和数据移动的开销是类似的,因此使用少得多的数据移动足以弥补那些附加的比较而且还有盈余。想要了解快速排序可以戳