在本书中这一篇章就写的略显单薄,不过作者也说明了,本书是NLP入门实践书籍,句法分析又属于NLP中较为高阶的问题,所以并没有深入讲解,我学习本书也是入门NLP,学习完本书后会学习《统计自然语言处理》。
由于本章实战内容很少,而且也没有特别晦涩的代码,所以在本文中更多的是讲解windows配置等问题。
一、JDK安装与配置
因为stanford parser是基于统计概率句法分析的一个java实现,所以需要安装JDK,JDK下载链接在这里。
我下载的是1.8版本的jdk,因为两三年前我还在碰java的时候就是用的1.8……
之前听一个做工程很久的大佬说JDK最好安装在默认目录,也就是C盘的program files文件夹里面,不过也不影响,反正只要路径对了就行,我安装在的D盘。因为安装包里面有个JDK和JRE,所以我用的两个文件夹来分别包装的。安装过程就是傻瓜式安装,点点点就对了。这个是我的安装目录:

安装好了之后就是配置环境变量,右键点击计算机>属性>高级系统设置>环境变量。这里说一下用户变量与系统变量的区别:
- 用户变量:指的是仅能本用户使用。对应的就是你开机时选择的用户,比如你哥哥或者弟弟有些小电影不想分享给你,就在这个电脑上新创建了一个用户,而你配置的用户变量,你哥哥或者弟弟就使用不了。
- 系统变量:指的是本电脑上所有用户都能使用。就是你和你哥哥或者弟弟一起共享小电影。
具体配置在哪里都可以,如果电脑上多个用户都需要可以配置在系统变量中,当然也可以配置在用户变量中。
配置JDK最简单的方式就是在环境变量中任意一个path中添加上"root/jdk/bin"就行了,比如我的安装路径的话就是在path中添加:
D:\java\JDK\bin
但是这种会有个问题,就是如果需要和其他插件等结合的时候,许多情况下需要有JAVA_HOME(比如我们这个程序),所以最规范的还是配置JAVA_HOME,CLASSPATH和path,下面开始讲解如何配置。
- 新建变量,变量名字为JAVA_HOME,变量值为JDK存储的地方,比如我的配置路径如下:
D:\java\JDK
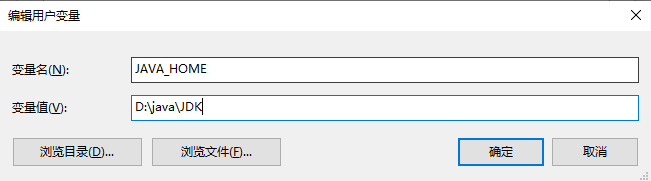
- 新建变量,变量名字为CLASSPATH,变量值为:
.;%JAVA_HOME%\lib\tools,jar;%JAVA_HOME%\lib\dt.jar;
这个直接复制是可以的哟,因为只要JAVA_HOME配置好了,就是有变量存储你的JDK路径了。
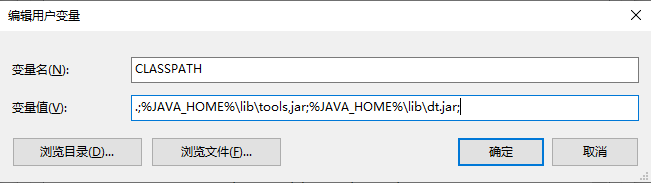
- 双击path,在path的变量值最后新增两行:
%JAVA_HOME%\bin
%PATH%

注:JAVA_HOME,CLASSPATH和配置的path一定要在同一个用户/系统变量中,比如我都是配置在的用户变量中,如果不在同一个变量中,那么会识别不到JDK。
配置好后,一路确定到底,打开cmd分别输入命令:
java -version
javac
如果出现了以下内容,那么恭喜你配置成功,否则就重新配置。

注:如果出错,那么重新配置后需要把cmd关闭后重启,不然你再次输入命令还是上次出现的结果。
二、PCFG文件下载
文件下载地址如下:https://nlp.stanford.edu/software/lex-parser.shtml#Download,一共需要下载两个文件,我下载的如下:

- 上面的下载链接下载下来的是stanford-parser-4.0.0.zip,里面包含的内容是本项目中需要的Stanford Parser的jar包和Stanford Parser训练好的模型包。
- 下面的下载链接下载下来的PCFG的模型。
我将这两个文件解压到的是项目的路径下,在我的项目中是如下的:
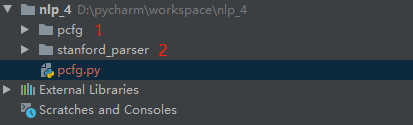
在1中存储的是下面链接下载下来的PCFG的模型,2中存储的是Stanford Parser的jar包和Stanford Parser训练好的模型包。
注:这里要考虑到文件路径,因为后面代码中的路径要依据这个进行更改。
三、代码
import jieba
from nltk.parse import stanford
import os
string = '他骑自行车去了菜市场。'
seg_list = jieba.cut(string, cut_all=False, HMM=True)
seg_str = " ".join(seg_list)
root = "./" # 根目录
parser_path = root + 'stanford_parser/stanford-parser.jar'
model_path = root + 'stanford_parser/stanford-parser-4.0.0-models.jar'
# 指定JDK路径
if not os.environ.get("JAVA_HOME"):
JAVA_HOME = 'D:/java/JDK'
os.environ['JAVA_HOME'] = JAVA_HOME
# PCFG模型路径
pcfg_path = root + "pcfg/edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz"
parser = stanford.StanfordParser(
path_to_jar=parser_path, # 指定stanford parser的jar包
path_to_models_jar=model_path, # 指定训练好的模型jar包
model_path=pcfg_path # 指定需要调用的句法分析算法的java class路径
)
sentence = parser.raw_parse(seg_str)
print("sentence:", sentence)
for line in sentence:
print(line)
print(line.leaves())
line.draw()
代码里面需要注意的点如下:
- seg_str后面的引号里面是个空格,这里是因为Stanford Parser的句法分析器接收的输入是分词完后以空格隔开的句子。
- 书上导入的包有笔误,我用的书是2018.4(2020.3重印),如果读者用的书是之后的书,有可能没有这个错误。书上是:
from nltk.parser import staford
这里应该是:
from nltk.parse import stanford
- 路径和文件名的问题。书上例子中的路径如下:
parser_path = "./stanford-parser.jar"
model_path = './stanford-parser-3.8.0-models.jar'
pcfg_path = "edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz"
但是我这里因为是重新建了两个文件夹,并且安装的版本不同,所以在我这个项目中路径应该如下:
parser_path = './stanford_parser/stanford-parser.jar'
model_path = './stanford_parser/stanford-parser-4.0.0-models.jar'
pcfg_path = "./pcfg/edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz"
读者依据自己的路径来调整这里的路径问题。可以使用如下代码测试文件是否存在:
print(os.path.exist(path))
- 最后就是说到的JAVA_HOME的问题了。
- 读者使用上面代码的时候应该看到了一个warning:
DeprecationWarning: The StanfordParser will be deprecated
Please use nltk.parse.corenlp.CoreNLPParser instead.
model_path=pcfg_path # 指定需要调用的句法分析算法的java class路径
这说明这个方法要被废弃了,所以最好使用他们推荐的包,再查查文档就可以解决这个警告问题了。
由于这里本身就是具体的应用问题,我也没有深入了解关于这个库的具体内容,所以也就只是浅尝辄止,后面学习《统计自然语言处理》的时候再慢慢回来学习句法分析。
相关的输出如下:
上面的内容是print(line)的内容,下面的内容是print(line.leaves())的内容。


四、总结
本文主要介绍了《python自然语言处理实战核心技术与算法》第六章句法分析中的基于PCFG的中文句法分析实战的下载、安装、配置以及代码。
五、参考
[1]涂铭,刘祥,刘树春.python自然语言处理实战核心技术与算法[M].机械工业出版社:北京,2018.4:116.