基于天池DSW
数据下载
# 下载训练数据
!wget https://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531810/train_set.csv.zip
!unzip train_set.csv.zip
数据读取
每个新闻是不定长的,使用csv格式进行存储,数据列使用\t进行分割,使用Pandas读取数据的代码如下:
import pandas as pd
train_df = pd.read_csv('../data/train_set.csv', sep='\t', nrows=100)#读取路径,sep分隔符,nrows读取行数
train_df.head()
读取好的数据(label列表示新闻的类别,text列表示新闻的文字):
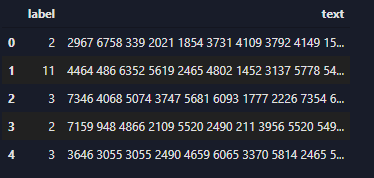
数据分析
非结构数据并不需要做很多的数据分析,但数据分析还是可以找出一些规律。
句子长度分析
赛题数据中每行句子的字符使用空格进行隔开,所以可以直接统计单词的个数来得到每个句子的长度。
#读取所有的数据
%pylab inline
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())
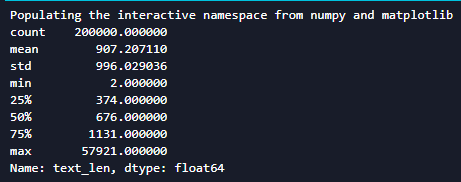
在训练数据集的20w数据中,每个句子平均由907个字符构成,最短的句子长度为2,最长的句子长度为57921。
绘制句子长度直方图
_ = plt.hist(train_df['text_len'],bins=200)
plt.xlabel('Text char count')
plt.ylabel('Histogram of char count')

大部分句子的长度集中在几千,少部分较长。
新闻类别分布
接下来可以对数据集的类别进行分布统计,具体统计每类新闻的样本个数。
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")
可以发现存在类别分布不均的情况,这会影响模型精度。

字符分布统计
将训练集中所有的句子进行拼接进而划分为字符,并统计每个字符的个数
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])
6869
(‘3750’, 7482224)
(‘3133’, 1)
从统计结果中可以看出,在训练集中总共包括6869个字,其中编号3750的字出现的次数最多,编号3133的字出现的次数最少。
根据字在每个句子的出现情况,反推出标点符号。覆盖率非常高的字符很有可能是标点符号。
from collections import Counter
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
print(word_count[1])
print(word_count[2])
(‘3750’, 197997)
(‘900’, 197653)
(‘648’, 191975)
可以发现3750、900、648三个字符出现次数最多,可能是标点符号。
结论
- 每个新闻平均字符个数较多,可能需要截断;
- 由于类别不均衡,会严重影响模型的精度。
作业
- 假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
- 统计每类新闻中出现次数最多的字符。
#假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
train_df['sentence_len'] = train_df['text'].apply(lambda x:sum([x.count('3750'),x.count('900'),x.count('648')]))
train_df['sentence_len'].describe()
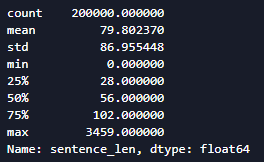
每篇新闻平均由79.8个句子构成
#统计每类新闻中出现次数最多的字符。
from collections import Counter
for i in range(0,14):
temp = train_df.loc[train_df['label'] == i,]
all_lines = ' '.join(list(temp['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
i = 0
while word_count[i][0] in ['3750','900','648']:
i+=1
print('类别%d新闻中出现次数最多的字符为%s,出现次数为%d'%(i,word_count[i][0],word_count[i][1]))

比赛地址:https://tianchi.aliyun.com/competition/entrance/531810/introduction
参考资料:
https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12586969.1002.9.6406111aIKCSLV&postId=118253