一、目标:
1.CNN基础与原理;
2.使用Pytorch框架构建CNN模型,并完成训练。
二、关于CNN
1)CNN介绍
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,[1]对于大型图像处理有出色表现。
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构[2]。
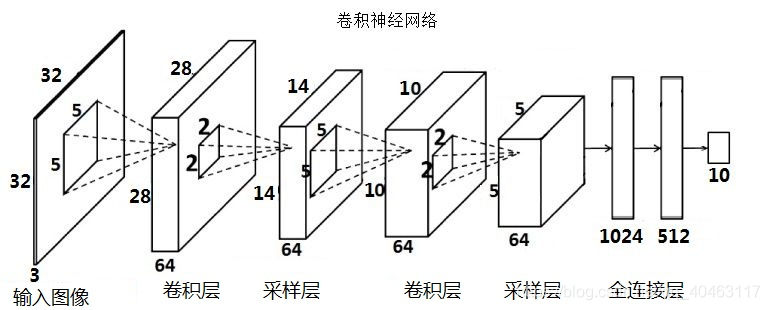
卷积神经网络(简称CNN)是一类特殊的人工神经网络,是深度学习中重要的一个分支。CNN在很多领域都表现优异,精度和速度比传统计算学习算法高很多。特别是在计算机视觉领域,CNN是解决图像分类、图像检索、物体检测和语义分割的主流模型。
CNN每一层由众多的卷积核组成,每个卷积核对输入的像素进行卷积操作,得到下一次的输入。随着网络层的增加卷积核会逐渐扩大感受野,并缩减图像的尺寸。
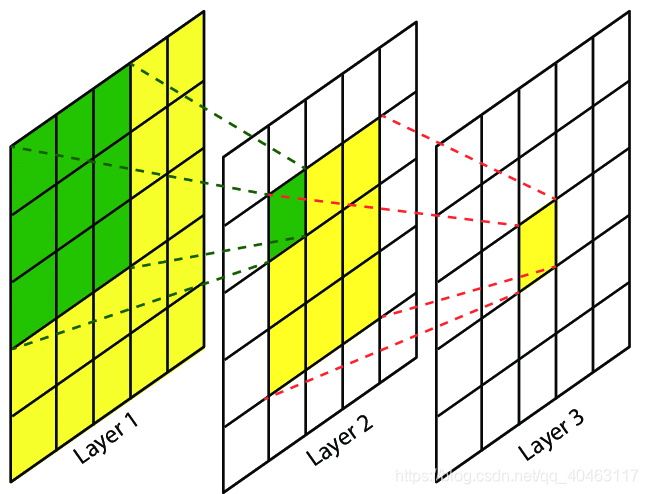
CNN是一种层次模型,输入的是原始的像素数据。CNN通过卷积(convolution)、池化(pooling)、非线性激活函数(non-linear activation function)和全连接层(fully connected layer)构成。
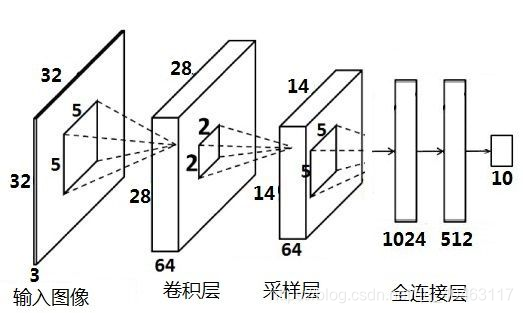
如下图所示为LeNet网络结构,是非常经典的字符识别模型。两个卷积层,两个池化层,两个全连接层组成。卷积核都是5×5,stride=1,池化层使用最大池化。
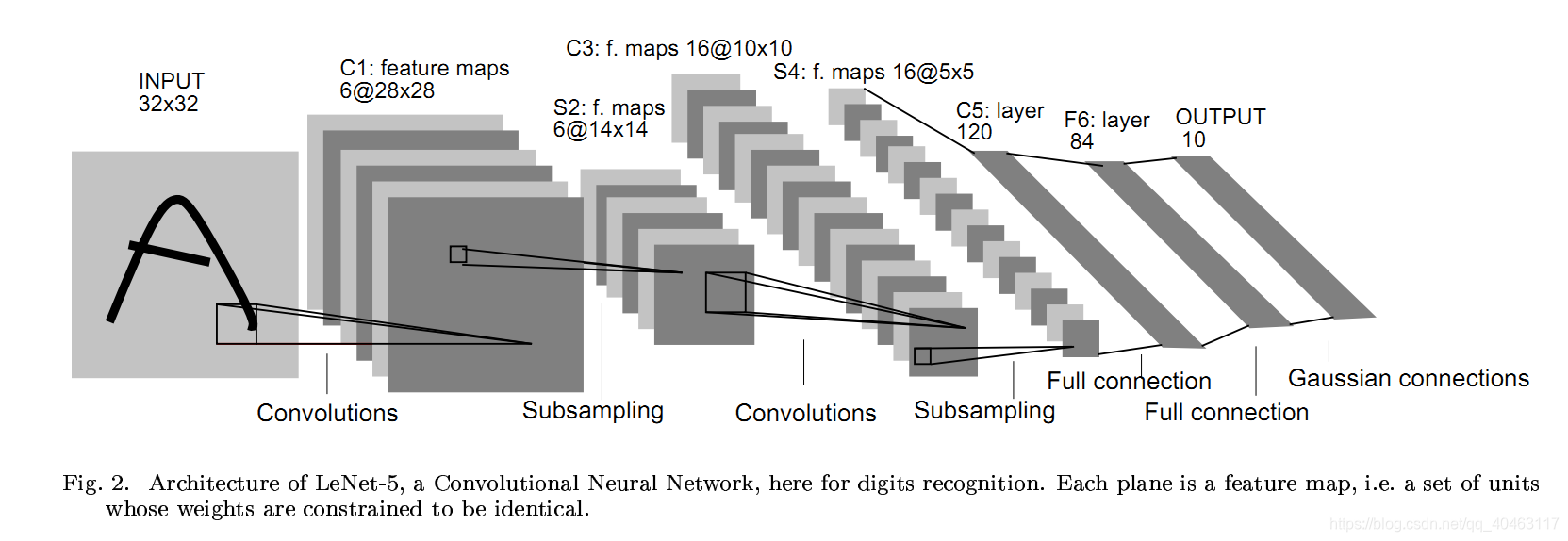
通过多次卷积和池化,CNN的最后一层将输入的图像像素映射为具体的输出。如在分类任务中会转换为不同类别的概率输出,然后计算真实标签与CNN模型的预测结果的差异,并通过反向传播更新每层的参数,并在更新完成后再次前向传播,如此反复直到训练完成 。
与传统机器学习模型相比,CNN具有一种端到端(End to End)的思路。在CNN训练的过程中是直接从图像像素到最终的输出,并不涉及到具体的特征提取和构建模型的过程,也不需要人工的参与。
2)CNN理解
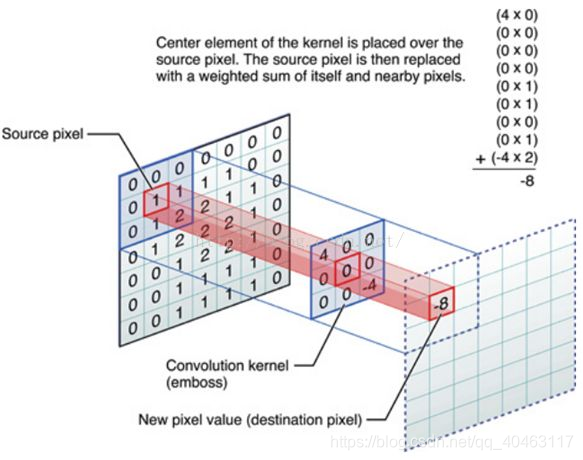
一个3x3 source pixels 经过一个3x3的卷积核后,source pixels 的特征映射成一个1x1 destination pixel。
根据人眼识别图像的性质:
问题:
1.卷积层提取的特征数量有限,而图片特征可能会过多;
2.最后采样层选出来的特征是否重要。
引入新概念——级联分类器(cascade of classifiers)
大概意思就是我从一堆弱分类器里面,挑出一个最符合要求的弱分类器,用着这个弱分类器把不想要的数据剔除,保留想要的数据
然后再从剩下的弱分类器里,再挑出一个最符合要求的弱分类器,对上一级保留的数据,把不想要的数据剔除,保留想要的数据。
最后,通过不断串联几个弱分类器,进过数据层层筛选,最后得到我们想要的数据。
CNN主要由3钟模块构成:
- 卷积层
- 采样层
- 全连接层
大致上可以理解为:
通过第一个卷积层提取最初特征,输出特征图(feature map)
通过第一个采样层对最初的特征图(feature map )进行特征选择,去除多余特征,重构新的特征图
第二个卷积层是对上一层的采样层的输出特征图(feature map)进行二次特征提取
第二个采样层也对上层输出进行二次特征选择
全连接层就是根据得到的特征进行分类
参考资料:卷积神经网络(CNN)入门讲解:https://zhuanlan.zhihu.com/p/31249821
三、Pytorch构建CNN模型
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
)
#
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
model = SVHN_Model1()
训练代码:
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), 0.005)
loss_plot, c0_plot = [], []
# 迭代10个Epoch
for epoch in range(10):
for data in train_loader:
c0, c1, c2, c3, c4, c5 = model(data[0])
loss = criterion(c0, data[1][:, 0]) + \
criterion(c1, data[1][:, 1]) + \
criterion(c2, data[1][:, 2]) + \
criterion(c3, data[1][:, 3]) + \
criterion(c4, data[1][:, 4]) + \
criterion(c5, data[1][:, 5])
loss /= 6
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_plot.append(loss.item())
c0_plot.append((c0.argmax(1) == data[1][:, 0]).sum().item()*1.0 / c0.shape[0])
print(epoch)
为了追求精度,也可以使用在ImageNet数据集上的预训练模型,具体方法如下:
class SVHN_Model2(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5