Datawhale零基础入门分词-数据分析
标签: 数据分析 二手车交易预测
注:本博文是在一群大神编写的教程基础上加入了一些自己的想法和注释,对很多关键性名字做出了注解。一来帮助自己加深学习,另一方面可以帮助新人降低门槛。
数据探索性分析
1. 目标
- 熟悉字段含义,了解数据集
- 利用可视化查看变量与预测值之间存在的关系
- 进行数据处理和特征工程
2. 内容
2.1 python库
- 数据科学库(pandas、numpy、scipy)
- 可视化库(matplotlib、seabon)
2.2 数据的载入及观察
- 载入训练集和测试集
- 观察数据
- 通过describe()方法熟悉相关变量
- 通过info()熟悉数据类型
- 查看每列的nan值情况
- 异常值检测
2.3 了解预测值分布
- 总体分布情况
- 查看skewness and kurtosis
- 查看预测值的具体频数
2.4 类别特征和数字特征,并对类别特征查看unique分布
2.5 数字特征分析
- 相关性分析
- 查看特征得偏度和峰值
- 每个数字的分布可视化
- 数字特征相互之间的关系可视化
- 多变量互相回归可视化
2.6 类型特征分析
- unique分布
- 类别特征箱型可视化
- 类别特征的小提琴图可视化
- 特征的每个类别频数可视化
- 类别特征的柱形图可视化类别
- 特征的每个类别频数可视化
2.7 用pandas_profiling生成数据报告
3. 示例代码及注释
3.1 python导包
#pandas、numpy是两个超级好用的数据科学库
import pandas as pd
import numpy as np
#matplotlib和seaborn为常见的可视化库
import matplotlib.pyplot as plt
import seaborn as sns
#缺失值可视化处理包
import missingno as msno
3.2 加载训集练和测试集数据
#注意相对路径和绝对路径
Train_data = pd.read_csv('./data/used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv('./data/used_car_testA_20200313.csv', sep=' ')
3.3 数据的特征集
| 属性 | 含义 |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuelType | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| creatDate | 汽车上线时间,即开始售卖时间 |
| price | 汽车价格 |
| v_0,…,v_14 | 匿名特征 |
交易ID:二手车交易唯一ID,主键
汽车交易名称:例如(奥迪A6L 2006款 2.4 CVT 舒适型)个人理解
汽车注册日期[1]:机动车所有者向车管所申请注册(提供申请表,校验机动车的来历证明、整车的出厂合格证、免税证、强制保险证等证明)获得批准的日期
车型编码[2]:根据编码规则,车型编码由企业代号、车辆类别、主要参数、产品序号、企业自定代号组成
匿名特征:从v_0到v_14根据汽车的其他交易数据人工构造的经过脱敏处理的匿名特征
3.4 观察数据集
#显示训练数据集的头和尾(图1)
Train_data.head().append(Train_data.tail())
#显示测试数据集的头和尾(图2)
TestA_data.head().append(TestA_data.tail())


由上图中的数据可以看出训练数据集数据行数为150000(0-149999),列数为31列;测试数据集行数为50000,列数为30(需要预测价格列);观察数据集的好处就在对于那些数据量超级大且不好用exel打开的情况下,快速的了解数据集的行列状况,让自己对数据的表示方式有一个直观的认识。
3.5 从上帝视角观察数据
拿到整个数据集后一脸懵逼的我们有着同一种想法: 辣么大的数据集,我从哪里下手?我太难了吧!
这时候我站起来反手就给你两(吨)推荐:describe()函数和info()函数
#显示常见的数据统计指标
Train_data.describe()
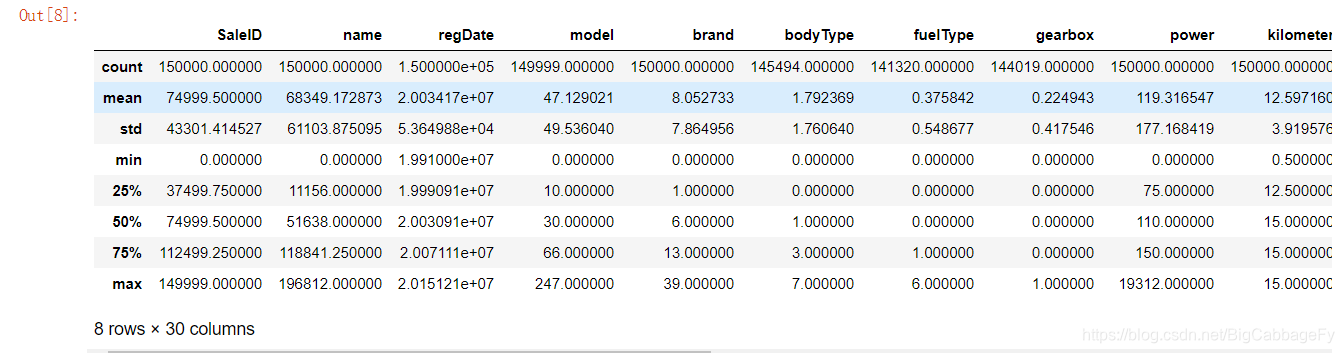
describe函数官方文档
describe函数博文
每一列的统计量分别代表了:count个数统计、mean平均值、std方差、min最小值、25%、50%、75%的中位数、max最大值。这里可以了解到整个数据集的数据值的大致分布情况。值得注意的是可能会出现精度问题例如regDate的count值。
#用来查看各列数据的non值和数据类型情况
Train_data.info()
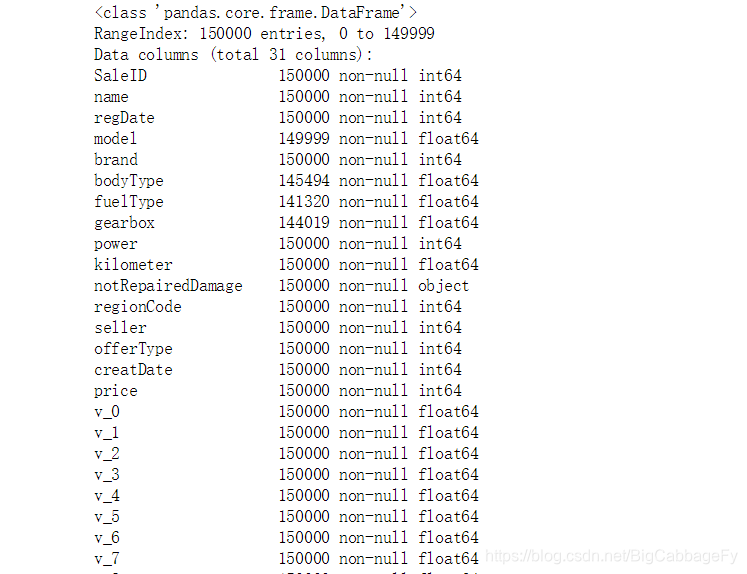
info函数官方文档
info函数主要是为了查看数据的数据类型和nan值情况及其分布。方便我们后续对nan值填补或者是删除
3.6 查看nan值分布情况
#统计训练集数据为空的情况
Train_data.isnull().sum()
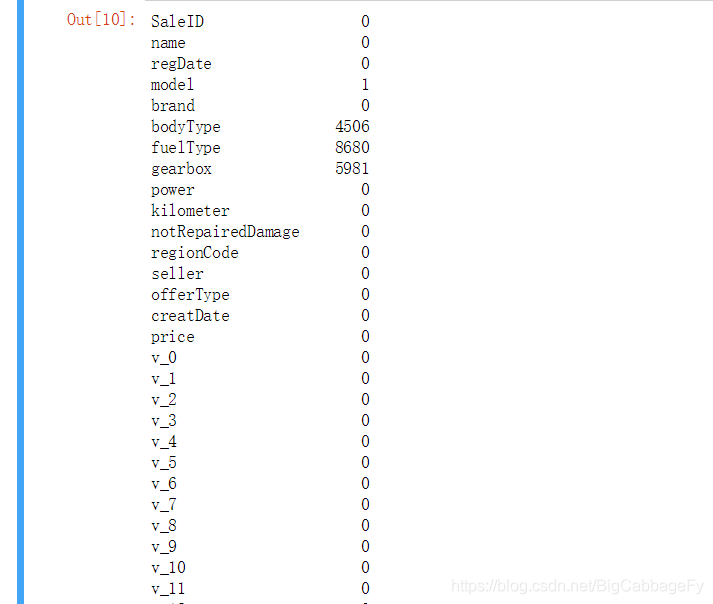
可视化缺省值分布
#用于无效矩阵的数据密集分布观测,
msno.matrix(Train_data.sample(250))

