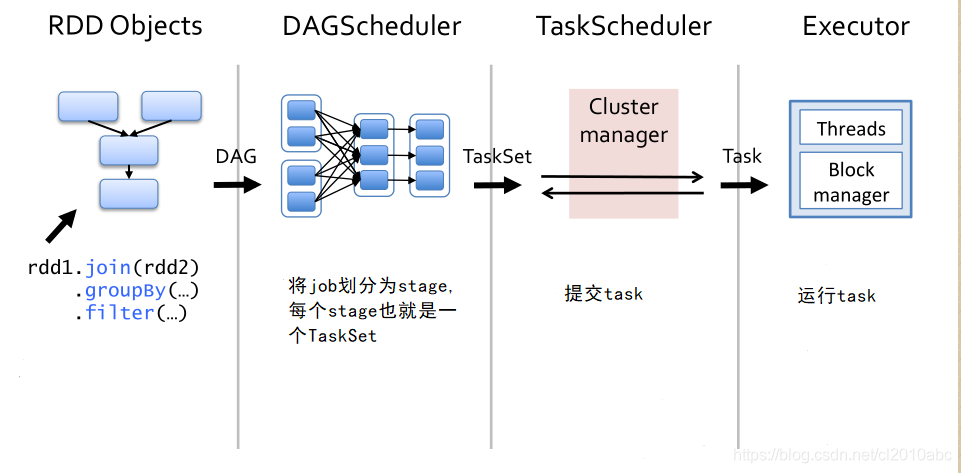
Spark job相关概念
- job
spark程序遇到一个action算子时就会提交一个job,一般一个spark应用程序会触发多个job。 - stage
一个job通常包含一个或多个stage,每个stage里的task可以并行执行,stage的划分依据是宽依赖,当出现了宽依赖就会划分出一个新的stage。 - task
task是spark的基本执行单元,Task 分为ShuffleMapTask和ResultTask。
spark job提交过程主要分为两个阶段:
- DAGScheduler将job划分为多个stage,每个stage里的任务也叫做一个TaskSet。
- TaskScheduler将每个stage(TaskSet)里的任务提交到所有的Executor上运行。
源代码分析
1.stage划分
为了追踪job提交流程,这里选择collect算子。
def collect[U: ClassTag](f: PartialFunction[T, U]): RDD[U] = withScope {
// 调用runJob
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
def runJob[T, U: ClassTag](
rdd: RDD[T],
processPartition: Iterator[T] => U,
resultHandler: (Int, U) => Unit)
{
val processFunc = (context: TaskContext, iter: Iterator[T]) => processPartition(iter)
runJob[T, U](rdd, processFunc, 0 until rdd.partitions.length, resultHandler)
}
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
...
// 调用dagScheduler runjob
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
...
}
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
...
//提交任务,返回值waiter用来确定job是否成功
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
...
}
}
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
...
//向内部事件循环器发送消息 JobSubmitted
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
...
}
submitJob的核心操作就是将JobSubmitted放入到eventProcessLoop。
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)
...
// 启动eventProcessLoop
eventProcessLoop.start()
DAGSchedulerEventProcessLoop继承自EventLoop
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging
EventLoop中开启了一个线程eventThread,该线程的run方法一直从队列里取出元素并
调用onReceive(event)方法。
private[spark] abstract class EventLoop[E](name: String) extends Logging {
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
private val stopped = new AtomicBoolean(false)
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
// 调用onReceive(event)
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
def start(): Unit = {
if (stopped.get) {
throw new IllegalStateException(name + " has already been stopped")
}
onStart()
// 启动eventThread线程
eventThread.start()
}
def stop(): Unit = {
if (stopped.compareAndSet(false, true)) {
eventThread.interrupt()
var onStopCalled = false
try {
eventThread.join()
onStopCalled = true
onStop()
} catch {
case ie: InterruptedException =>
Thread.currentThread().interrupt()
if (!onStopCalled) {
onStop()
}
}
} else {
}
}
def post(event: E): Unit = {
eventQueue.put(event)
}
def isActive: Boolean = eventThread.isAlive
protected def onStart(): Unit = {}
protected def onStop(): Unit = {}
protected def onReceive(event: E): Unit
}
eventProcessLoop是DAGSchedulerEventProcessLoop实例,因此实际调用的是DAGSchedulerEventProcessLoop类的onReceive(event: DAGSchedulerEvent)方法。
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging {
private[this] val timer = dagScheduler.metricsSource.messageProcessingTimer
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
// 调用doOnReceive
doOnReceive(event)
} finally {
timerContext.stop()
}
}
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
//处理提交的job
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, workerLost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}
override def onError(e: Throwable): Unit = {
logError("DAGSchedulerEventProcessLoop failed; shutting down SparkContext", e)
try {
dagScheduler.doCancelAllJobs()
} catch {
case t: Throwable => logError("DAGScheduler failed to cancel all jobs.", t)
}
dagScheduler.sc.stopInNewThread()
}
override def onStop(): Unit = {
// Cancel any active jobs in postStop hook
dagScheduler.cleanUpAfterSchedulerStop()
}
}
doOnReceive 中通过模式匹配的方式把执行路由到case JobSubmitted时,调用dagScheduler handleJobSubmitted方法。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
//表示最后一阶段
var finalStage: ResultStage = null
try {
//stage是从后往前划分,所以先创建最后一个阶段
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
//提交finalstage,内部会递归提交那些没有被提交的父stage
submitStage(finalStage)
}
handleJobSubmitted方法里会调用submitStage
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 1.找到没有提交的stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
//2.如果为空,则从当前stage直接提交
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
//3.如果不为空,则递归的向上查找
for (parent <- missing) {
submitStage(parent)
}
//4.当前stage加入到待提交的stage 集合中
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
当前stage没有父依赖时submitStage会调用submitMissingTasks提交当前stage。
private def submitMissingTasks(stage: Stage, jobId: Int) {
...
// 广播task
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
//根据stage不同,分成不同的task
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
//提交task
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
// 把上面创建好的task的集合封装成TaskSet,发送给taskScheduler
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
...
}
}
submitMissingTasks方法中会将stage封装成TaskSet发送给taskScheduler。至此stage划分阶段的工作完成。
2.Task提交
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
submitTasks最终调用的是TaskSchedulerImpl中的submitTasks方法
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging {
...
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 创建TaskManager 对象,用来跟踪每个任务 每个stage对应一个TaskManager
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 把任务提交给调度池来调度,默认是FIFO策略
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
// 通知SchedulerBackend 给自己发送消息 reviveOffers
backend.reviveOffers()
}
...
}
backend.reviveOffers()实际调用的是CoarseGrainedSchedulerBackend类的reviveOffers()方法。
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}
当driverEndpoint发送ReviveOffers消息后,receive方法将会被调用。
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
case ReviveOffers =>
// 把任务发给executors
makeOffers()
case KillTask(taskId, executorId, interruptThread, reason) =>
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.executorEndpoint.send(
KillTask(taskId, executorId, interruptThread, reason))
case None =>
// Ignoring the task kill since the executor is not registered.
logWarning(s"Attempted to kill task $taskId for unknown executor $executorId.")
}
case KillExecutorsOnHost(host) =>
scheduler.getExecutorsAliveOnHost(host).foreach { exec =>
killExecutors(exec.toSeq, replace = true, force = true)
}
case UpdateDelegationTokens(newDelegationTokens) =>
executorDataMap.values.foreach { ed =>
ed.executorEndpoint.send(UpdateDelegationTokens(newDelegationTokens))
}
case RemoveExecutor(executorId, reason) =>
// We will remove the executor's state and cannot restore it. However, the connection
// between the driver and the executor may be still alive so that the executor won't exit
// automatically, so try to tell the executor to stop itself. See SPARK-13519.
executorDataMap.get(executorId).foreach(_.executorEndpoint.send(StopExecutor))
removeExecutor(executorId, reason)
}
private def makeOffers() {
// Make sure no executor is killed while some task is launching on it
val taskDescs = CoarseGrainedSchedulerBackend.this.synchronized {
// Filter out executors under killing
// 过滤出Active exectors
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// 封装资源
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
// 启动任务
launchTasks(taskDescs)
}
}
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 序列化Task
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
// 发送任务到Executor, CoarseGrainedExecutorBackend会收到消息
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
launchTasks会将序列化后的任务发给Executor,CoarseGrainedExecutorBackend receive方法会收到消息。
private[spark] class CoarseGrainedExecutorBackend(
override val rpcEnv: RpcEnv,
driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
userClassPath: Seq[URL],
env: SparkEnv)
extends ThreadSafeRpcEndpoint with ExecutorBackend with Logging {
...
override def receive: PartialFunction[Any, Unit] = {
//向Driver注册
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
// 创建Executor 对象, 向driver注册
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
case RegisterExecutorFailed(message) =>
exitExecutor(1, "Slave registration failed: " + message)
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// 反序列化Task Description
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 启动任务
executor.launchTask(this, taskDesc)
}
case KillTask(taskId, _, interruptThread, reason) =>
if (executor == null) {
exitExecutor(1, "Received KillTask command but executor was null")
} else {
executor.killTask(taskId, interruptThread, reason)
}
case StopExecutor =>
stopping.set(true)
logInfo("Driver commanded a shutdown")
self.send(Shutdown)
case Shutdown =>
stopping.set(true)
new Thread("CoarseGrainedExecutorBackend-stop-executor") {
override def run(): Unit = {
executor.stop()
}
}.start()
case UpdateDelegationTokens(tokenBytes) =>
logInfo(s"Received tokens of ${tokenBytes.length} bytes")
SparkHadoopUtil.get.addDelegationTokens(tokenBytes, env.conf)
}
...
}
receive方法中匹配到LaunchTask后会调用executor.launchTask(this, taskDesc)来启动任务
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
// 构造Runnable
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
// 将Runnable放入线程池
threadPool.execute(tr)
}
threadPool是工作线程池
private val threadPool = {
val threadFactory = new ThreadFactoryBuilder()
.setDaemon(true)
.setNameFormat("Executor task launch worker-%d")
.setThreadFactory(new ThreadFactory {
override def newThread(r: Runnable): Thread =
new UninterruptibleThread(r, "unused") // thread name will be set by ThreadFactoryBuilder
})
.build()
Executors.newCachedThreadPool(threadFactory).asInstanceOf[ThreadPoolExecutor]
}
Task的具体运行逻辑位于TaskRunner的run方法中
override def run(): Unit = {
threadId = Thread.currentThread.getId
Thread.currentThread.setName(threadName)
val threadMXBean = ManagementFactory.getThreadMXBean
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
// 向driver更新task状态
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
var taskStartCpu: Long = 0
startGCTime = computeTotalGcTime()
try {
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
// 反序列化task相关数据
Executor.taskDeserializationProps.set(taskDescription.properties)
updateDependencies(taskDescription.addedFiles, taskDescription.addedJars)
task = ser.deserialize[Task[Any]](
taskDescription.serializedTask, Thread.currentThread.getContextClassLoader)
task.localProperties = taskDescription.properties
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
val killReason = reasonIfKilled
if (killReason.isDefined) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException(killReason.get)
}
// The purpose of updating the epoch here is to invalidate executor map output status cache
// in case FetchFailures have occurred. In local mode `env.mapOutputTracker` will be
// MapOutputTrackerMaster and its cache invalidation is not based on epoch numbers so
// we don't need to make any special calls here.
if (!isLocal) {
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.asInstanceOf[MapOutputTrackerWorker].updateEpoch(task.epoch)
}
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
taskStartCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
var threwException = true
val value = try {
//开始运行task
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory > 0 && !threwException) {
val errMsg = s"Managed memory leak detected; size = $freedMemory bytes, TID = $taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty && !threwException) {
val errMsg =
s"${releasedLocks.size} block locks were not released by TID = $taskId:\n" +
releasedLocks.mkString("[", ", ", "]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak", false)) {
throw new SparkException(errMsg)
} else {
logInfo(errMsg)
}
}
}
task.context.fetchFailed.foreach { fetchFailure =>
// uh-oh. it appears the user code has caught the fetch-failure without throwing any
// other exceptions. Its *possible* this is what the user meant to do (though highly
// unlikely). So we will log an error and keep going.
logError(s"TID ${taskId} completed successfully though internally it encountered " +
s"unrecoverable fetch failures! Most likely this means user code is incorrectly " +
s"swallowing Spark's internal ${classOf[FetchFailedException]}", fetchFailure)
}
val taskFinish = System.currentTimeMillis()
val taskFinishCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// If the task has been killed, let's fail it.
task.context.killTaskIfInterrupted()
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run.
task.metrics.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
task.metrics.setExecutorDeserializeCpuTime(
(taskStartCpu - deserializeStartCpuTime) + task.executorDeserializeCpuTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
task.metrics.setExecutorCpuTime(
(taskFinishCpu - taskStartCpu) - task.executorDeserializeCpuTime)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.metrics.setResultSerializationTime(afterSerialization - beforeSerialization)
// Expose task metrics using the Dropwizard metrics system.
// Update task metrics counters
executorSource.METRIC_CPU_TIME.inc(task.metrics.executorCpuTime)
executorSource.METRIC_RUN_TIME.inc(task.metrics.executorRunTime)
executorSource.METRIC_JVM_GC_TIME.inc(task.metrics.jvmGCTime)
executorSource.METRIC_DESERIALIZE_TIME.inc(task.metrics.executorDeserializeTime)
executorSource.METRIC_DESERIALIZE_CPU_TIME.inc(task.metrics.executorDeserializeCpuTime)
executorSource.METRIC_RESULT_SERIALIZE_TIME.inc(task.metrics.resultSerializationTime)
executorSource.METRIC_SHUFFLE_FETCH_WAIT_TIME
.inc(task.metrics.shuffleReadMetrics.fetchWaitTime)
executorSource.METRIC_SHUFFLE_WRITE_TIME.inc(task.metrics.shuffleWriteMetrics.writeTime)
executorSource.METRIC_SHUFFLE_TOTAL_BYTES_READ
.inc(task.metrics.shuffleReadMetrics.totalBytesRead)
executorSource.METRIC_SHUFFLE_REMOTE_BYTES_READ
.inc(task.metrics.shuffleReadMetrics.remoteBytesRead)
executorSource.METRIC_SHUFFLE_REMOTE_BYTES_READ_TO_DISK
.inc(task.metrics.shuffleReadMetrics.remoteBytesReadToDisk)
executorSource.METRIC_SHUFFLE_LOCAL_BYTES_READ
.inc(task.metrics.shuffleReadMetrics.localBytesRead)
executorSource.METRIC_SHUFFLE_RECORDS_READ
.inc(task.metrics.shuffleReadMetrics.recordsRead)
executorSource.METRIC_SHUFFLE_REMOTE_BLOCKS_FETCHED
.inc(task.metrics.shuffleReadMetrics.remoteBlocksFetched)
executorSource.METRIC_SHUFFLE_LOCAL_BLOCKS_FETCHED
.inc(task.metrics.shuffleReadMetrics.localBlocksFetched)
executorSource.METRIC_SHUFFLE_BYTES_WRITTEN
.inc(task.metrics.shuffleWriteMetrics.bytesWritten)
executorSource.METRIC_SHUFFLE_RECORDS_WRITTEN
.inc(task.metrics.shuffleWriteMetrics.recordsWritten)
executorSource.METRIC_INPUT_BYTES_READ
.inc(task.metrics.inputMetrics.bytesRead)
executorSource.METRIC_INPUT_RECORDS_READ
.inc(task.metrics.inputMetrics.recordsRead)
executorSource.METRIC_OUTPUT_BYTES_WRITTEN
.inc(task.metrics.outputMetrics.bytesWritten)
executorSource.METRIC_OUTPUT_RECORDS_WRITTEN
.inc(task.metrics.inputMetrics.recordsRead)
executorSource.METRIC_RESULT_SIZE.inc(task.metrics.resultSize)
executorSource.METRIC_DISK_BYTES_SPILLED.inc(task.metrics.diskBytesSpilled)
executorSource.METRIC_MEMORY_BYTES_SPILLED.inc(task.metrics.memoryBytesSpilled)
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
// TODO: do not serialize value twice
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit()
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
case t: Throwable if hasFetchFailure && !Utils.isFatalError(t) =>
val reason = task.context.fetchFailed.get.toTaskFailedReason
if (!t.isInstanceOf[FetchFailedException]) {
// there was a fetch failure in the task, but some user code wrapped that exception
// and threw something else. Regardless, we treat it as a fetch failure.
val fetchFailedCls = classOf[FetchFailedException].getName
logWarning(s"TID ${taskId} encountered a ${fetchFailedCls} and " +
s"failed, but the ${fetchFailedCls} was hidden by another " +
s"exception. Spark is handling this like a fetch failure and ignoring the " +
s"other exception: $t")
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case t: TaskKilledException =>
logInfo(s"Executor killed $taskName (TID $taskId), reason: ${t.reason}")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled(t.reason)))
case _: InterruptedException | NonFatal(_) if
task != null && task.reasonIfKilled.isDefined =>
val killReason = task.reasonIfKilled.getOrElse("unknown reason")
logInfo(s"Executor interrupted and killed $taskName (TID $taskId), reason: $killReason")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(
taskId, TaskState.KILLED, ser.serialize(TaskKilled(killReason)))
case CausedBy(cDE: CommitDeniedException) =>
val reason = cDE.toTaskCommitDeniedReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(reason))
case t: Throwable =>
// Attempt to exit cleanly by informing the driver of our failure.
// If anything goes wrong (or this was a fatal exception), we will delegate to
// the default uncaught exception handler, which will terminate the Executor.
logError(s"Exception in $taskName (TID $taskId)", t)
// SPARK-20904: Do not report failure to driver if if happened during shut down. Because
// libraries may set up shutdown hooks that race with running tasks during shutdown,
// spurious failures may occur and can result in improper accounting in the driver (e.g.
// the task failure would not be ignored if the shutdown happened because of premption,
// instead of an app issue).
if (!ShutdownHookManager.inShutdown()) {
// Collect latest accumulator values to report back to the driver
val accums: Seq[AccumulatorV2[_, _]] =
if (task != null) {
task.metrics.setExecutorRunTime(System.currentTimeMillis() - taskStart)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.collectAccumulatorUpdates(taskFailed = true)
} else {
Seq.empty
}
val accUpdates = accums.map(acc => acc.toInfo(Some(acc.value), None))
val serializedTaskEndReason = {
try {
ser.serialize(new ExceptionFailure(t, accUpdates).withAccums(accums))
} catch {
case _: NotSerializableException =>
// t is not serializable so just send the stacktrace
ser.serialize(new ExceptionFailure(t, accUpdates, false).withAccums(accums))
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, serializedTaskEndReason)
} else {
logInfo("Not reporting error to driver during JVM shutdown.")
}
// Don't forcibly exit unless the exception was inherently fatal, to avoid
// stopping other tasks unnecessarily.
if (!t.isInstanceOf[SparkOutOfMemoryError] && Utils.isFatalError(t)) {
uncaughtExceptionHandler.uncaughtException(Thread.currentThread(), t)
}
} finally {
runningTasks.remove(taskId)
}
}
可以看出run方法中主要逻辑包括反序列化Task,运行Task以及向driver更新Task状态等操作。
至此一个TaskSet中的Task也被提交到Executor上运行。
总结
本文主要分析了job提交的流程,主要包括stage划分与Task提交的流程。