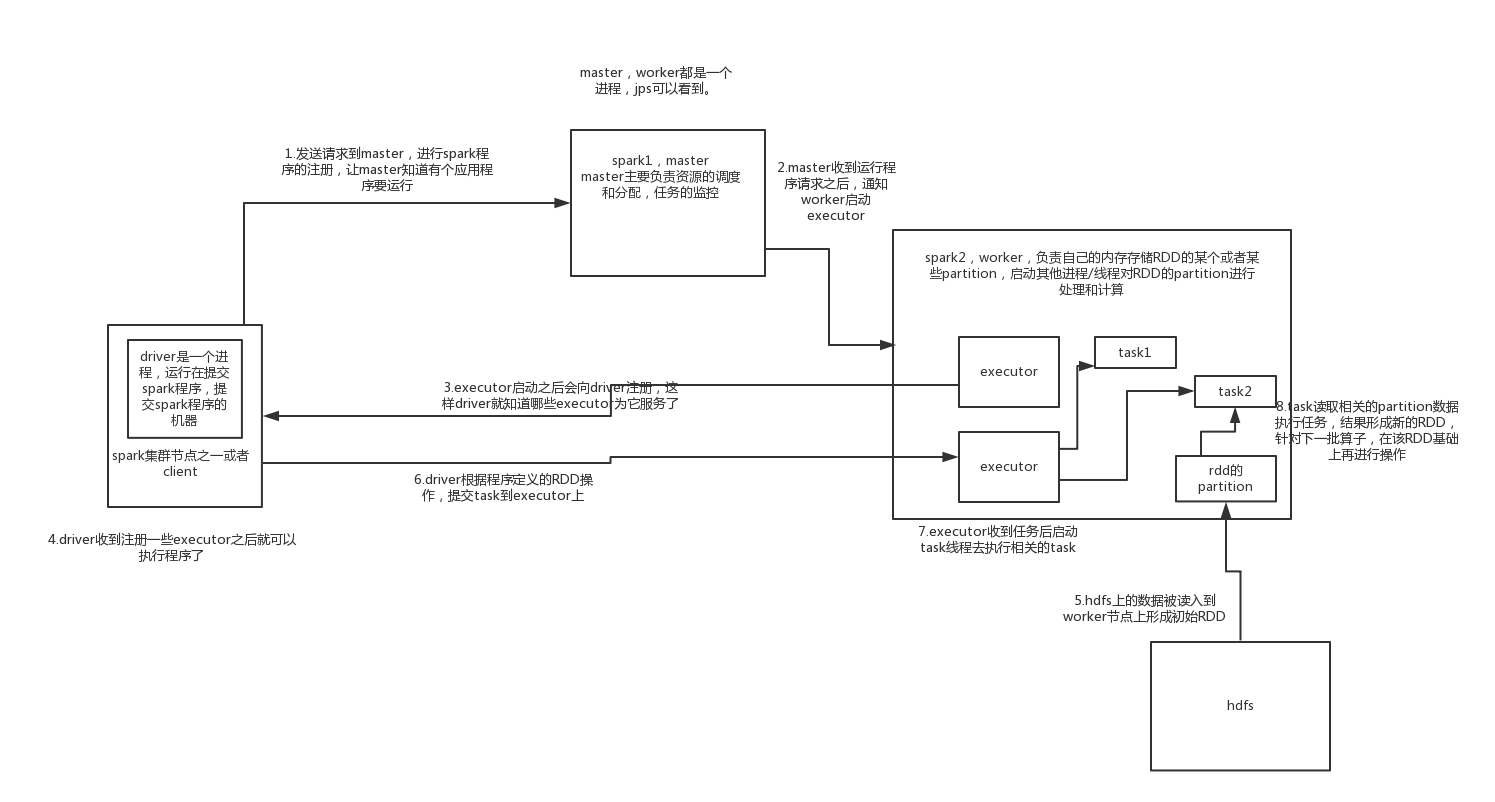
本文从整体流程上来分析spark任务在standalone集群模式下从提交到执行任务的整个流程:
1.standalone下的守护进程:首先在standalone集群模式下,集群分为master和worker节点,master和worker分别代表了spark的一个主节点和从节点,都是一个进程,我们可以用jps命令看到该进程。
2.driver节点:我们在spark的客户端使用spark-submit命令提交我们的jar包,提交所在的机器会运行一个driver进程,driver进程一直存在直到程序运行结束,保持与master和worker节点的通信。
3.driver提交一个application给master,master中维护着work节点的状态,根据一些算法选择一些worker去启动executor进程去处理任务,executor也是进程。
4.executor反向注册到driver节点,driver就拿到了运行任务所需要的executor列表,后续向这些executor上去分配任务。
5.driver的sparkContext根据我们自己编写的代码,首先根据transformation还是action动作做job划分,具体是每遇到一个action就划分成一个job;再对job划分,每遇到一个宽依赖划分成一个stage;最后对stage根据RDD的partition划分成taskset,具体是每个partition划分成一个task。将这些task提交给executor去执行。
6.executor收到执行任务的时候,首次会从hdfs或者其他存储读取数据形成初始RDD,启动task线程根据算子对这些RDD做运算,生成后续需要的RDD。
7.运算完成,sparkContext关闭。