1. spark cache原理
Task运行的时候是要去获取Parent的RDD对应的Partition的数据,它会调用RDD的iterator方法把对应的Partition的数据集给遍历出来,具体流程如下图:
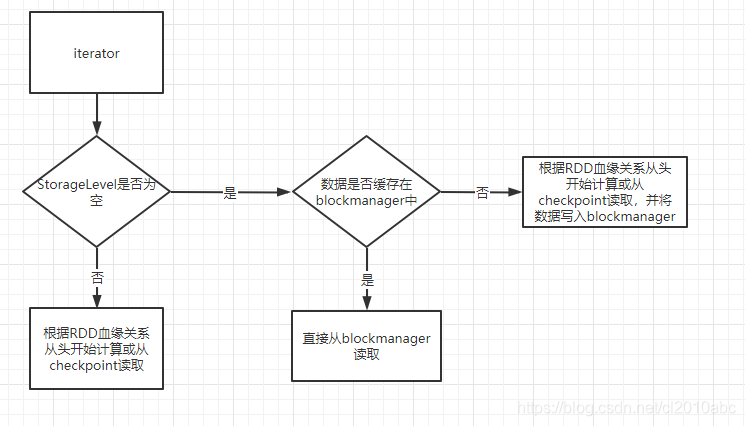
从图中可以看出,spark cache的本质就是将RDD的数据存储在了BlockManager上,下次重新使用的时候直接从BlockManager获取即可,免去了从“头”计算的开销。
2.cache 源代码分析
首先还是从RDD.scala的iterator方法开始,如果storageLevel不等于None,则调用getOrCompute,如果storageLevel等于None,则调用computeOrReadCheckpoint从头开始计算或者从checkpoint读取。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
// storageLevel不等于NONE,说明RDD已经cache
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
// 进行rdd partition的计算或者从checkpoint读取数据
computeOrReadCheckpoint(split, context)
}
}
getOrCompute方法中会调用BlockManager的getOrElseUpdate方法,如果指定的block存在,则直接获取,否则调用computeOrReadCheckpoint方法去计算block,然后再保存到BlockManager。
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
val blockId = RDDBlockId(id, partition.index)
var readCachedBlock = true
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
readCachedBlock = false
computeOrReadCheckpoint(partition, context)
}) match {
case Left(blockResult) =>
if (readCachedBlock) {
// 如果已经被缓存则直接读取
val existingMetrics = context.taskMetrics().inputMetrics
existingMetrics.incBytesRead(blockResult.bytes)
new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
} else {
new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])
}
case Right(iter) =>
new InterruptibleIterator(context, iter.asInstanceOf[Iterator[T]])
}
}
def getOrElseUpdate[T](
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[T],
makeIterator: () => Iterator[T]): Either[BlockResult, Iterator[T]] = {
// 尝试从本地获取数据,如果获取不到则从远端获取
get[T](blockId)(classTag) match {
case Some(block) =>
return Left(block)
case _ =>
}
// 如果本地化和远端都没有获取到数据,则调用makeIterator计算,最后将结果写入block
doPutIterator(blockId, makeIterator, level, classTag, keepReadLock = true) match {
case None =>
val blockResult = getLocalValues(blockId).getOrElse {
releaseLock(blockId)
throw new SparkException(s"get() failed for block $blockId even though we held a lock")
}
releaseLock(blockId)
Left(blockResult)
case Some(iter) =>
Right(iter)
}
}
computeOrReadCheckpoint方法中会判断rdd是否checkpoint,如果有则调用第一个parent rdd的iterator方法获取,否则从“头”开始计算。
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointedAndMaterialized) {
//如果rdd被checkpointed,则调用第一个parent rdd的iterator方法获取
firstParent[T].iterator(split, context)
} else {
//如果rdd没被checkpointed,则重新计算
compute(split, context)
}
}