简介
前面我分享了一个spark的wordcount,那么这篇blog我就简单的介绍一下spark提交任务的流程。
也就是当我们提交一个jar包到集群的时候,是如何进行调度和计算的。
然后就是分享一下有关RDD 的东西。RDD是spark框架中的组成单位,也是spark分布式计算的核心,在我看来,spark分布式计算完全是由RDD来实现的,所以RDD对于学习spark来说是非常关键的。
提交jar任务的流程
(1)spark集群与客户端的关系
首先,我们要是知道spark集群和客户端是分开的。大致的逻辑是从客户端提交任务给到集群。但是其中有一些细节大家要注意一下。
(2)客户端
客户端上有一个driver程序,顾名思义,他就是我们启动spark计算任务的启动的起点。相当于spark-shell或者spark-submit。
(3)集群
这里的集群是一个分布式的主从结构,一定会有一个master节点,然后会有若干个从节点我们叫worker。
(4)流程
- 首先我们通过Driver提交任务,而driver通过启动一个SparkContext对象提交任务的请求,请注意这里并不会提交任务,只是申请master是否执行。
- master节点接受到请求,然后为这个任务分配资源,然后再将这些资源分配给从节点。
- 然后worker为此启动Executor
- 然后Driver开始提交真正的任务而不再只是请求,而这次提交是不经过master的,而是直接提交给worker的。
注:在第四步 的提交的过程中,并不是一次性都提交完成,而是一个stage一个stage来提交的。
但是什么是stage呢?

Stage
这是每个spark任务被划分成的单位,每一个stage都可能产生不同的RDD,然后第n个Stage依赖于第n-1个stage的输出结果。
那么如何区分stage我们还需要先引入RDD的概念,然后才能讲清楚。
RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,他是最基本的数据抽象。
RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性,这里是源码中的描述:
- 一组分片:对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。
- 计算每个分区的函数:Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。
- 依赖关系:RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。
- Partitioner代表RDD的分片函数:Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
- 一个列表:存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
这里我们可以通过画图更加直观的来理解:
比如我们创建一个RDD
var rddTest = sc.parallelize(Array(,1,2,3,4,5),2)
这样我就创建了一个RDD,然后是一个1-5的数组,并且分为了两个partitioner。
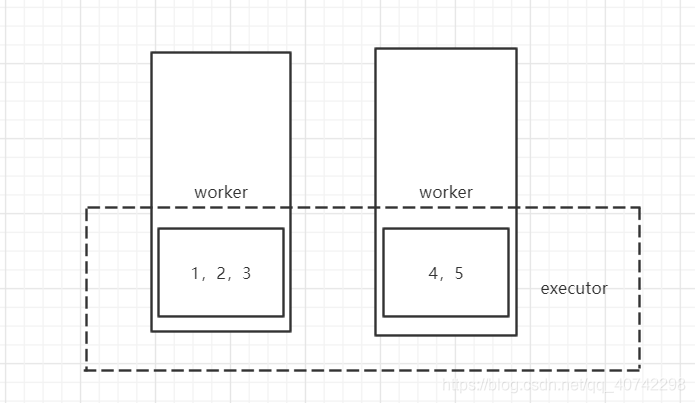
完全印证了弹性和分布式这两种特点。
RDD依赖
一个RDD和另一个RDD有两种依赖的关系:
(1)窄依赖
也就是每一个父RDD 的partition最多被子RDD的一个partition使用
(一对一)
(2)宽依赖
也就是每一个父RDD 的partition被多个子RDD的一个partition使用
(一对多)
根据RDD的依赖来划分stage
总结起来就是,根据宽依赖划分Stage。
比如:
两个RDD之间是窄依赖,那么这两个RDD是同属于一个stage。以此类推。
如果两个RDD之间是宽依赖,那么他们一定属于不同的stage。以此类推。
