目录
求解:argmaxc P(c|w) -> argmaxc P(w|c) P(c) / P(w)
贝叶斯简介:
贝叶斯(约1701-1761) Thomas Bayes,英国数学家
贝叶斯方法源于他生前为解决一个“逆概”问题写的一篇文章。
贝叶斯要解决的问题:
正向概率:假设袋子里面有N个白球,M个黑球,你伸手进去摸一把, 摸出黑球的概率是多大
逆向概率:如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛 摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可 以就此对袋子里面的黑白球的比例作出什么样的推测
所谓的贝叶斯定理源于他生前为解决一个“逆概”问题写的一篇文章,而这篇文章是在他死后才由他的一位朋友发表出来的。在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有 N 个白球,M 个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。这个问题,就是所谓的逆向概率问题。
为什么要使用贝叶斯:
1、现实世界本身就是不确定的,人类的观察能力是有局限性的:
--比如说我们上面说的N 个白球,M 个黑球,在现实里面可能是无穷大的,也就是说这个数值很难具体量化
2、我们日常所观察到的只是事物表面上的结果,因此我们需要提供一个猜测
理解贝叶斯例子:
在一个学校里面,男生占比60%,女生占40%

计算过程:
1、正向概率:
假设学校里面人的总数是 U 个(后面我们通过计算可以知道U是可以约分的),
穿长裤的(男生):U * P(Boy) * P(Pants|Boy)
P(Boy) 是男生的概率 = 60%
P(Pants|Boy) 是条件概率,即在 Boy 这个条件下穿长裤的概率是多大,这里是 100% ,因为所有男生都穿长裤
穿长裤的(女生): U * P(Girl) * P(Pants|Girl)
穿长裤总数:U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)
穿长裤概率=穿长裤总数/校里面人的总数=【U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)】/U
2、逆向概率计算:一个人穿了长裤,是女生的概率?
一个人穿了长裤,是女生的概率=P(Girl|Pants)=穿长裤的女生/穿长裤总数
=U * P(Girl) * P(Pants|Girl)/【U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)】--我们发现这里U是可以消去的
=P(Girl) * P(Pants|Girl)/【P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)】
分母其实就是 P(Pants) 分子其实就是 P(Pants, Girl)
贝叶斯公式:
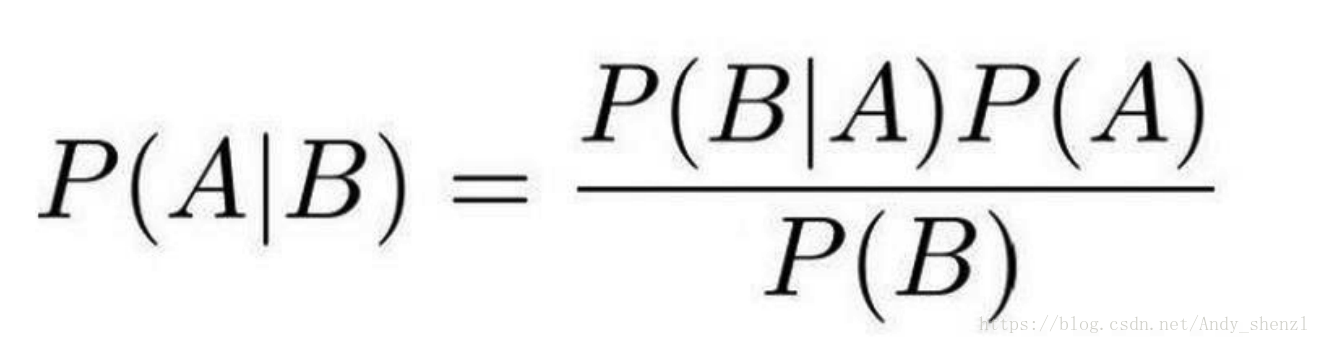
其中P(A|B)是在 B 发生的情况下 A 发生的可能性。
P(A)是 A 的先验概率,之所以称为“先验”是因为它不考虑任何 B 方面的因素。
P(A|B)是已知 B 发生后 A 的条件概率,也由于得自 B 的取值而被称作 A 的后验概率。
P(B|A)是已知 A 发生后 B 的条件概率,也由于得自 A 的取值而被称作 B 的后验概率。
P(B)是 B 的先验概率,也作标淮化常量(normalizing constant)。
按这些术语,贝叶斯定理可表述为:
后验概率 = (相似度 * 先验概率)/标淮化常量
贝叶斯公式推导
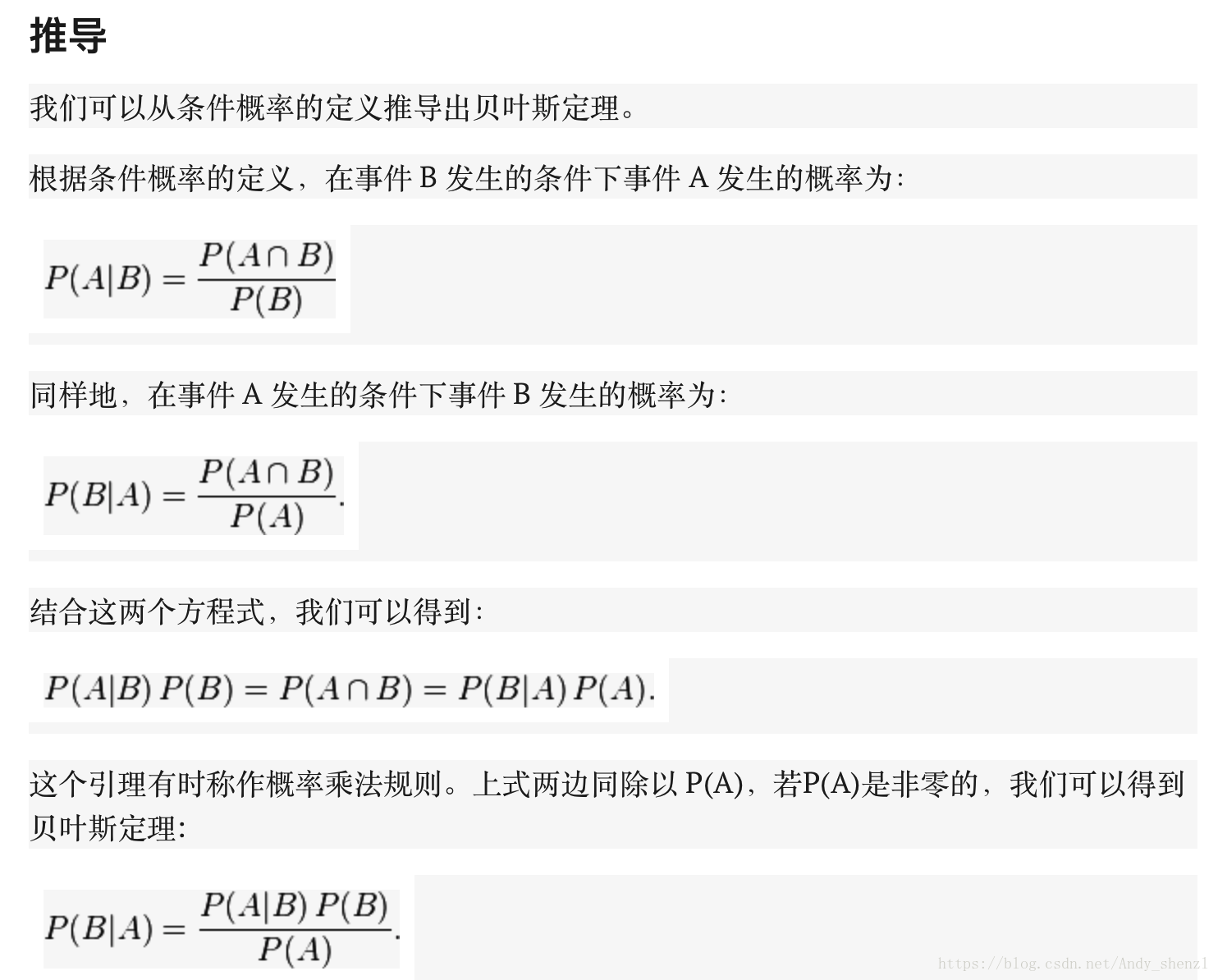
通常,事件 A 在事件 B 发生的条件下的概率,与事件 B 在事件 A 发生的条件下的概率是不一样的;然而,这两者是有确定关系的,贝叶斯定理就是这种关系的陈述。
贝叶斯公式的用途在于通过己知三个概率来推测第四个概率。它的内容是:在 B 出现的前提下,A 出现的概率等于 A 出现的前提下 B 出现的概率乘以 A 出现的概率再除以 B 出现的概率。通过联系 A 与 B,计算从一个事件发生的情况下另一事件发生的概率,即从结果上溯到源头(也即逆向概率)。
通俗地讲就是当你不能确定某一个事件发生的概率时,你可以依靠与该事件本质属性相关的事件发生的概率去推测该事件发生的概率。用数学语言表达就是:支持某项属性的事件发生得愈多,则该事件发生的的可能性就愈大。这个推理过程有时候也叫贝叶斯推理。
python经典取球实例:
假设有两个各装了100个球的箱子,甲箱子中有70个红球,30个绿球,乙箱子中有30个红球,70个绿球。假设随机选择其中一个箱子,从中拿出一个球记下球色再放回原箱子,如此重复12次,记录得到8次红球,4次绿球。问题来了,你认为被选择的箱子是甲箱子的概率有多大?
刚开始选择甲乙两箱子的先验概率都是50%,因为是随机二选一(这是贝叶斯定理二选一的特殊形式)。即有:
P(甲) = 0.5, P(乙) = 1 - P(甲);
这时在拿出一个球是红球的情况下,我们就应该根据这个信息来更新选择的是甲箱子的先验概率:
P(甲|红球1) = P(红球|甲) × P(甲) / (P(红球|甲) × P(甲) + (P(红球|乙) × P(乙)))
P(红球|甲):甲箱子中拿到红球的概率
P(红球|乙):乙箱子中拿到红球的概率
因此在出现一个红球的情况下,选择的是甲箱子的先验概率就可被修正为:
P(甲|红球1) = 0.7 × 0.5 / (0.7 × 0.5 + 0.3 × 0.5) = 0.7
即在出现一个红球之后,甲乙箱子被选中的先验概率就被修正为:
P(甲) = 0.7, P(乙) = 1 - P(甲) = 0.3;
如此重复,直到经历8次红球修正(概率增加),4此绿球修正(概率减少)之后,选择的是甲箱子的概率为:96.7%。
-
def bayesFunc(pIsBox1, pBox1, pBox2):
-
return (pIsBox1 * pBox1)/((pIsBox1 * pBox1) + (
1 - pIsBox1) * pBox2)
-
def redGreenBallProblem():
-
pIsBox1 =
0.5
-
# consider 8 red ball
-
for i
in range(
1,
9):
-
pIsBox1 = bayesFunc(pIsBox1,
0.7,
0.3)
-
print (
"拿到 %d 个球是红球是甲箱子的先验概率: %f" % (i, pIsBox1))
-
# consider 4 green ball
-
for i
in range(
1,
5):
-
pIsBox1 = bayesFunc(pIsBox1,
0.3,
0.7)
-
print (
"拿到 %d 个球是绿球是甲箱子的先验概率: %f" % (i, pIsBox1))
-
redGreenBallProblem()

python拼写纠正实例:
问题:我们看到用户输入了一个不在字典中的单词,我们需要去猜 测:“这个家伙到底真正想输入的单词是什么呢?
比如一个人输入了一个单词tha,其实他真正想输入的可能是the,也许是要输入than等等
P(我们猜测他想输入的单词 | 他实际输入的单词)
用户实际输入的单词记为D( D代表Data ,即观测数据)
猜测1:P(h1 | D),猜测2:P(h2 | D),猜测3:P(h3 | D) 。。。
统一为:P(h | D)
P(h | D) = P(h) * P(D | h) / P(D)
用户实际输入的单词记为 D ( D 代表 Data ,即观测数据)
对于不同的具体猜测 h1 h2 h3 .. ,P(D) 都是一样的,所以在比较 P(h1 | D) 和 P(h2 | D) 的时候我们可以忽略这个常数
P(h | D) ∝ P(h) * P(D | h) 对于给定观测数据,一个猜测是好是坏,取决于“这个猜测本身独 立的可能性大小(先验概率,Prior )”和“这个猜测生成我们观测 到的数据的可能性大小。
贝叶斯方法计算: P(h) * P(D | h),P(h) 是特定猜测的先验概率
比如用户输入tlp ,那到底是 top 还是 tip ?这个时候,当最大似然 不能作出决定性的判断时,先验概率就可以插手进来给出指示—— “既然你无法决定,那么我告诉你,一般来说 top 出现的程度要高许多,所以更可能他想打的是 top ”
模型比较理论
最大似然:最符合观测数据的(即 P(D | h) 最大的)最有优势
掷一个硬币,观察到的是“正”,根据最大似然估计的精神,我们应该 猜测这枚硬币掷出“正”的概率是 1,因为这个才是能最大化 P(D | h) 的那个猜测
奥卡姆剃刀: P(h) 较大的模型有较大的优势
奥卡姆剃刀定律(Occam's Razor, Ockham's Razor)又称“奥康的剃刀”,它是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出。这个原理称为“如无必要,勿增实体”,即“简单有效原理”。正如他在《箴言书注》2卷15题说“切勿浪费较多东西去做,用较少的东西,同样可以做好的事情。”(百度百科)
原理具体内容为:1.避重趋轻 2.避繁逐简 3.以简御繁 4.避虚就实
剃刀原则从来没有说简单的理论就是正确的理论,通常表述为“当两个假说具有完全相同的解释力和预测力时,我们以那个较为简单的假说作为讨论依据。”(科学松鼠会)
剃刀原则不是一个理论而是一个原理,它的目的是为了精简抽象实体。它不能被证明也不能被证伪,因为它是一个规范性的思考原则。大部分情况下,应用奥卡姆剃刀原理是合适的;但是这不代表奥卡姆剃刀就是正确的。(知乎)
总结一下,剃刀原则并不是一种定理(在数学上有推导,数学之美——刘未鹏),而是一种思维方式,可用于指导我们的工作,比如我们可以用A和B达到同样的效果,但B更简单,于是我们选择B。同时,也有人说可能因为能力不足,于是我们选择更简单的方式来处理问题,这也是剃刀的原则的一种应用吧。举个贴切的例子,做决策树分析的时候,采用9个属性的预测性能和5个属性的预测性能是相似的,那么我们就会选择5个属性来预测。
如果平面上有 N 个点,近似构成一条直线,但绝不精确地位于一条直线 上。这时我们既可以用直线来拟合(模型1),也可以用二阶多项式(模 型2)拟合,也可以用三阶多项式(模型3),特别地,用 N-1 阶多项式 便能够保证肯定能完美通过 N 个数据点。那么,这些可能的模型之中到 底哪个是最靠谱的呢?
奥卡姆剃刀:越是高阶的多项式越是不常见
求解:argmaxc P(c|w) -> argmaxc P(w|c) P(c) / P(w)
- P(c), 文章中出现一个正确拼写词 c 的概率, 也就是说, 在英语文章中, c 出现的概率有多大
- P(w|c), 在用户想键入 c 的情况下敲成 w 的概率. 因为这个是代表用户会以多大的概率把 c 敲错成 w
- argmaxc, 用来枚举所有可能的 c 并且选取概率最大的
-
import re, collections
-
-
def words(text):
return re.findall(
'[a-z]+', text.lower())
#把语料中的单词全部抽取出来, 转成小写, 并且去除单词中间的特殊符号
-
-
def train(features):
-
model = collections.defaultdict(
lambda:
1)
-
for f
in features:
-
model[f] +=
1
-
return model
-
#要是遇到我们从来没有过见过的新词怎么办. 假如说一个词拼写完全正确, 但是语料库中没有包含这个词, 从而这个词也永远不会出现在训练集中. 于是, 我们就要返回出现这个词的概率是0. 这个情况不太妙, 因为概率为0这个代表了这个事件绝对不可能发生, 而在我们的概率模型中, 我们期望用一个很小的概率来代表这种情况. lambda: 1
-
NWORDS = train(words(open(
'big.txt').read()))
#big.txt为语料库
-
-
alphabet =
'abcdefghijklmnopqrstuvwxyz'
-
-
#编辑距离:
-
#两个词之间的编辑距离定义为使用了几次插入(在词中插入一个单字母), 删除(删除一个单字母), 交换(交换相邻两个字母), 替换(把一个字母换成另一个)的操作从一个词变到另一个词.
-
def edits1(word):
#改变其中一个字母
-
n = len(word)
-
return set([word[
0:i]+word[i+
1:]
for i
in range(n)] +
# 删除某个字母
-
[word[
0:i]+word[i+
1]+word[i]+word[i+
2:]
for i
in range(n
-1)] +
# 改变其中两个字母前后顺序
-
[word[
0:i]+c+word[i+
1:]
for i
in range(n)
for c
in alphabet] +
# 替换某个字母
-
[word[
0:i]+c+word[i:]
for i
in range(n+
1)
for c
in alphabet])
# 插入某个字母
-
-
def known_edits2(word):
#改变两个字母
-
return set(e2
for e1
in edits1(word)
for e2
in edits1(e1)
if e2
in NWORDS)
-
-
def known(words):
return set(w
for w
in words
if w
in NWORDS)
-
#如果known(set)非空, candidate 就会选取这个集合, 而不继续计算后面的
-
def correct(word):
-
candidates = known([word])
or known(edits1(word))
or known_edits2(word)
or [word]
-
return max(candidates, key=
lambda w: NWORDS[w])
比如我们输入了morw,那么根据语料库的统计,我们应该输入的是more

目录